

OpenStack 企业私有云的若干需求(6):大规模扩展性支持
本系列会介绍OpenStack 企业私有云的几个需求:
- 自动扩展(Auto-scaling)支持
- 多租户和租户隔离 (multi-tenancy and tenancy isolation)
- 混合云(Hybrid cloud)支持
- 主流硬件支持、云快速交付 和 SLA 保证
- 大规模扩展性支持
- 私有云外围环境支持(包括支持CDN 、商业SDN控制器、防火墙和VPN/专线等)
- 向上扩展性(PaaS 和 SaaS 等支撑)
- 企业数据中心IT环境支持(包括裸金属/Bare metal、F5 、GPU、跨云网络连通、租户计费、备份等支持)
- 行业解决方案
- 独立的服务,包括培训、运维等
扩展性(Scalability)是云的基本要素之一,因此对 OpenStack 云也不例外。
一方面,和已经非常成熟的公有云和私有云方案相比,目前的 OpenStack 在扩展性方面还有很多的不足,这些不足给其大规模扩展性带来了相当多的问题。另一方面,扩展性本身也许不是太大的问题,比如一个云能够支持200个节点还是支持300个节点也许不是那么重要,但是,个人认为,扩展性和产品的品质是息息相关的。一个具有良好扩展性的OpenStack 私有云产品,是可以比较容易地和它的高质量联系上的,一个能支持大的规模扩展性良好的系统,其稳定性、可靠性、可用性都将会比较好。
本文基于目前一些 OpenStack 私有云扩展性的公开成果,结合自己的理解,谈谈如果设定 OpenStack 企业私有云的扩展性目标,以及在技术上如何实现这些目标。
1. 扩展性的范围和一些公开的数据
1.1 扩展性的范围
OpenStack 云包括存储、计算和网络,其中:
- 存储往往是外部存储,包括开源的比如 Ceph,以及商业的比如 EMC,IBM的企业级存储,因此,存储的的扩展性可以另行讨论。
- 网络的扩展性,是在 OpenStack 扩展性的范围内
- 计算的扩展性,是在 OpenStack 扩展性的范围内
1.2 几个可比较的公开数据
1.2.1 单个HP Helion 私有云的扩展性上限:200 计算节点,1000虚机
 (来源)
(来源)
1.2.2 单个华为私有云的扩展性上限:1024 计算节点,80000虚机
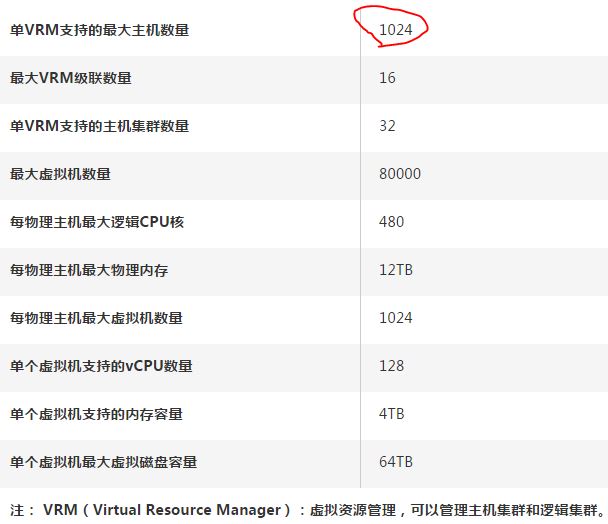 (来源于华为官网)
(来源于华为官网)
1.2.3 VMware vSphere 6.0 扩展性:每个 vCenter 最多管1000个节点,8000个虚机
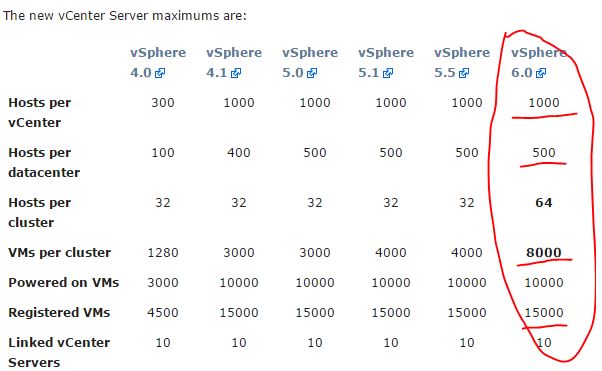 (来源于VMware官网)
(来源于VMware官网)
1.2.4 据 2015 OpenStack 社区的用户调查,56% 用户的虚机数在50以内,30% 用户的虚机数在500以内。
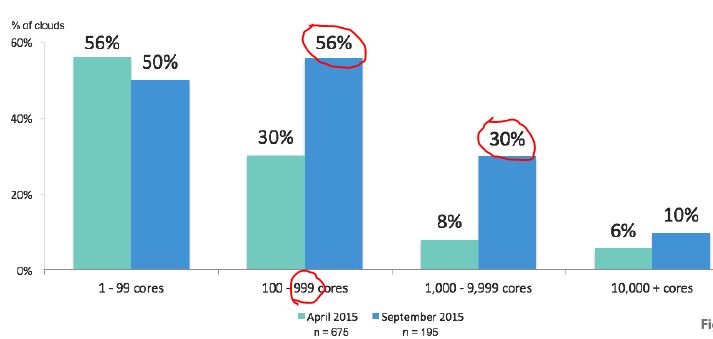
2. 一些公开的大规模测试案例
2.1 Mirantis 在 SoftLayer 上分别所做的200个和350个节点环境的测试
2.1.1 环境配置
Totals for resources are: * 100,000 vCPUs * 6250 Gb of RAM * 200TB of disk space. * 400 hardware servers #最多400台服务器 * CPU as 1:32 * RAM as 1:1.5, * OpenStack 2013.2 (Havana) * only three OpenStack services: Compute (Nova), Image (Glance) and Identity (Keystone). * For networking, we used the Nova Network service in FlatDHCPmode with the Multi-host feature enabled. * standard Mirantis OpenStack HA architecture, including synchronously replicated multi-master database (MySQL+Galera), software load balancer for API services (haproxy) and corosync/pacemaker for IP level HA * Rally
2.1.2 200 个节点的测试结果
在做少量配置修改的情况下(修改 sqlalchemy 的 连接池大小从 5 为 100;修改 haproxy 的连接数为 16000 ),创建虚机的成功率达到 99.96%:

也就是说,OpenStack 社区版本支持 200 个计算节点的环境基本上是不需要做什么代码修改和优化的,这种支持是内在的。
2.1.3 350 个节点环境的测试结果

成功率略有下降,但是下降有限。
2.2 CERN 私有云使用 Nova Cell 管理超过5000个计算节点
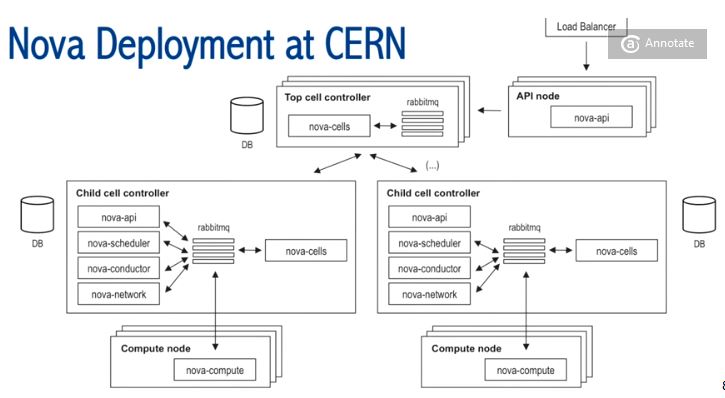
他们使用 33 个 Cell,每个 Child Cell 大概 200 个计算节点,管理超过 5000 个计算节点。详情请参考 超千个节点OpenStack私有云案例(1):CERN 5000+ 计算节点私有云。
3. 提高扩展性的一些技术
3.1 计算资源的扩展:Nova-cell
3.1.1 Nova Cell 的分层架构
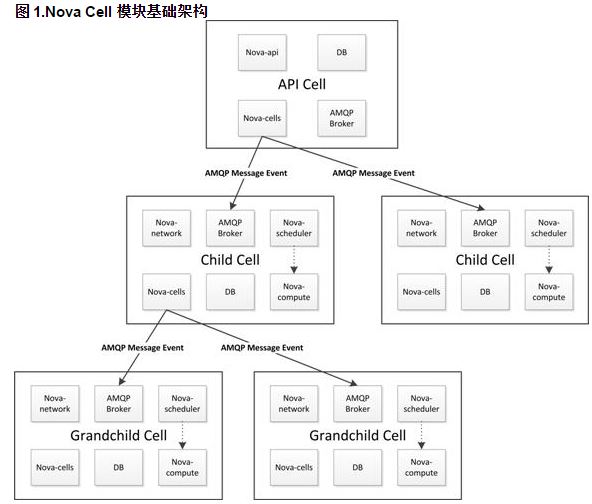
OpenStack 在G 版本引入了 nova-cell 技术,概括如下:
- 每一个Cell中拥有独立的DB和AMQP broker
- 引入新的nova-cell服务
- 消息路由
- 调度(与主机调度不同,子Cell通过定时刷新将自己能力和资源上报给父Cell)
- cell之间通信通过RPC
- cells之间是树状结构
- 顶层是API cell,不感知底层物理主机以及虚拟化
- 子cell无nova-api服务
- 子cell无quota概念(NoopQuota)
因此,nova cell 的功能允许我们以更加灵活的分布式的方式实现对 OpenStack Compute 云的缩放,而不需要更加复杂的技术,只需数据库和消息队列等。它的目的是支持更大规模的部署。当启用了这个功能的时候,OpenStack Compute 云中的主机会被分组,称作 cell。cell的结构是树的形式。top-level 级别的 cell 中的主机运行一个 nova-api 服务,但是可以没有 nova-compute 服务。每一个子 cell 应该运行常规 OpenStack 云计算中所有nova-*类型的服务,除了nova-api服务。我们可以把一个cell树结构看成一个正常的OpenStack Compute部署,因为在这个树中的每个cell中都有自己的数据库服务和消息队列服务。
nova-cells 服务处理cell之间的通信,并选择一个cell用于建立新的实例。这个服务将会被每个cell所需要的。cell之间的通信是可插拔的,目前cell之间的通信只是通过RPC服务来实现的。采用cell服务实现了cell的调度和主机节点的调度是相互分离的。nova-cells 服务首先会选择一个cell(目前实现的是随机选择,将来会添加过滤/权重功能,还可以基于广播获取的capacity/capabilities等参数)。一旦合适的cell被选择,且建立新的实例的请求到达了这个cell的nova-cells服务之上,这个cell将会发送建立新的实例的请求到这个cell的主机调度器。
3.1.2 Nova Cell 的现状和问题
Nova Cell 有 V1 和 V2 两个版本。目前,V1 的开发已经被冻结,大量的 bug 没有被修复;V2 还在开发过程中,还没有正式 GA,因此,其架构还不够稳定,官方并不推荐在生产环境部署使用。因此,如果厂商需要使用 Nova Cell 的话,需要自己做开发和维护,但是在目前,这似乎是扩展计算资源唯一的方式,因此,可以看到不少的客户在使用 CERN、天河、RackSpace 和 eBay 等等。
3.2 网络资源的扩展
3.2.1 标准 Neutron
标准 Neutron 的扩展性非常差,这是因为跨网段的网络流量全部需要经过网络节点,这使得它成为一个瓶颈,阻止了云规模的进一步扩展。
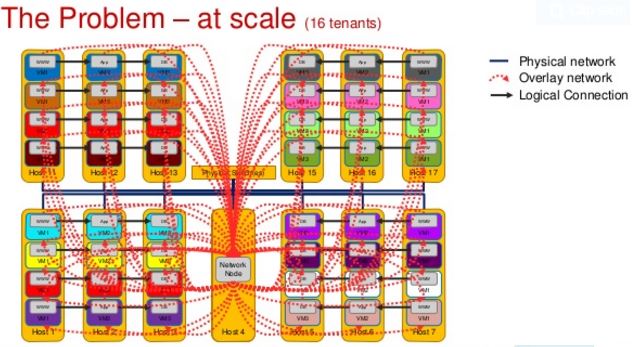
HP 曾经在它的公有云上使用 OpenStack,其 Neutron 是基于 IceHouse 版本的。他们总结了一些建议,包括:
- Upgrade neutron (Icehouse is better than Havana is better than Grizzly…)
- Make sure your neutron server is properly provisioned and tuned
- Make sure the metadata agent is properly tuned
- Upgrade your kernel (newer is generally better)
- Make sure sudo is properly versioned and tuned
- Expect improved stability, performance and scalability in Juno
完整信息请参考原文。
3.2.2 Neutron DVR
DVR 是在 Juno 版本引入的,详细的解释可以参考 理解 OpenStack 高可用(HA)(3):Neutron 分布式虚拟路由(Neutron Distributed Virtual Routing)
DVR 是对标准 Neutron 的一个优化,它带来了一些优点,但是也引入了新的很大的问题:
| 优势 | 劣势 |
| 将东西网络流量和 DNAT 分布到计算节点上 | 给消息队列带来了非常大的压力(比如,同步 ARP 到所有的 names) |
| 显然地减少了网络节点的压力 | 管理复杂 |
| 巨大的代码改动,影响代码的稳定性 | |
| 使用 Linux TCP/IP 协议栈带来的性能下降 |
3.2.3 SDN:能解决某些场景下的问题,但是不能解决全部问题
本质上,SDN 是一个集中式方案,它不是为了解决 Neutron 的扩展性问题,而是为了解决性能和管理性问题的。
下面是国内盛科的一个SDN 解决方案:
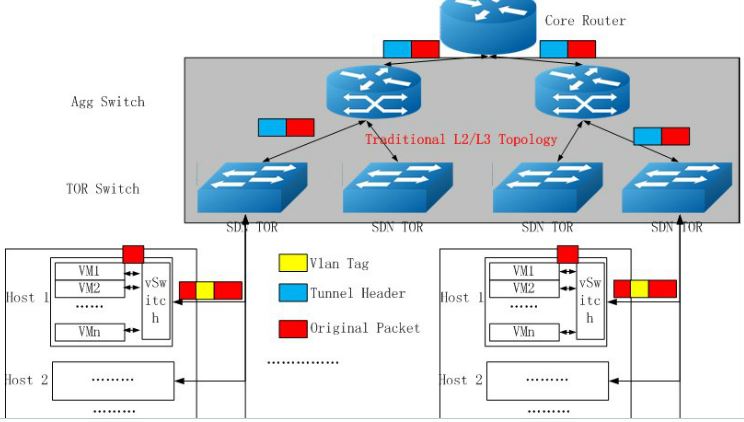
它能一定程度上消除单点瓶颈,并带来扩展性的提升:

但是,SDN 本身使用逻辑上集中的 SDN Controller (控制器),即使它们是物理上分布式的,其本身的扩展性还是有一定的限制。
<04/20 更新 >
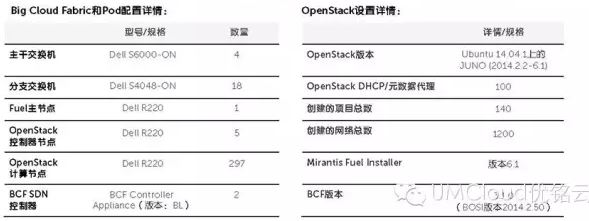
UMCloud 发出 联合呈现首个公开商业 SDN OpenStack 数据中心解决方案 ,Mirantis、戴尔与 Big Switch 在戴尔公司数据中心内合作部署并测试了完全填充的8个机架(300节点)OpenStack 数据中心设置。整个解决方案包含:
- Dell Networking 交换机和服务器——包含一系列10/40GbE开放式网络交换机(S6000-ON和S4048-ON)及1RU机架式服务器(PowerEdge系列);
- Mirantis OpenStack 6.1——含 Mirantis Fuel Installer,可快速、灵活并稳定地部署 OpenStack 组件;
- Big Cloud Fabric(P+V版本)——含适用于使用ML2驱动程序和L3插件的L2+L3网络的 BCF OpenStack Neutron Plugin,为生产级 OpenStack 部署提供所需的规模和弹性;
- BCF OpenStack Installer (BOSI)——OpenStack 安装的一个插件,与 Mirantis Fuel 等安装程序无缝互操作,以处理操作系统控制器和计算节点上所有与网络相关的安装和配置任务;
Big Switch Networks 推出了业内第一款统一 SDN 结构Big Cloud Fabric(P+V版本),为 OpenStack 数据中心提供高弹性和自动化的网络解决方案。Big Cloud Fabric (BCF) 构建为分支、主干和虚拟交换机结构,采用 BCF Controller 作为单一窗口,以便对整个物理和虚拟网络环境进行设置和故障排除,并提供环境的可见性和分析。
测试的主要 OpenStack Neutron 增强功能和特性包括:
-
分布式虚拟路由和分布式NAT/浮动IP——解决L3代理瓶颈和流量发卡问题;
-
简化的故障排除——提供跨物理和虚拟交换机的端到端可见性,包括安全组策略;
该测试也印证了我的 SDN 能够支撑 300 到 500 个节点规模的集群的观点。
3.2.4 DragonFlow
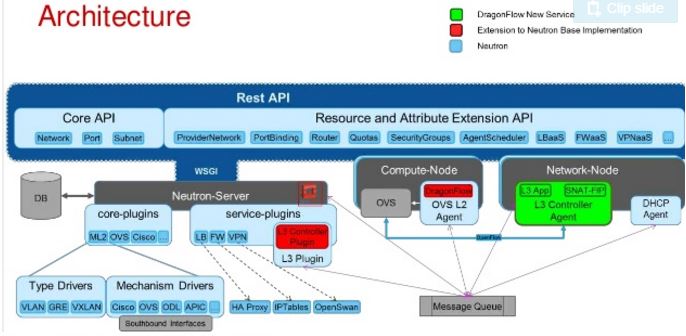
据说它是为了解决 Neutron DVR 的问题而来的,它和 DVR 相比的一些优势:

关于 DragonFlow 更详细的说明,请阅读官方文档。目前,其开发由华为主导,依然在进行中,因此,它还无法在生产系统中使用。
3.2.5 Neutron 的优化,一直在进行,一直在路上
也许可以考虑以下思路:
- 300 个节点以内的环境,可以使用经过仔细测试和配置优化的标准 Neutron
- 300 到 500 个节点的环境,可以考虑使用 SDN
- 500 个节点以上的环境,需要采用分布式方案,包括分布式 SDN和优化后的 Neutron DVR 等方案
3.3 控制服务的扩展性
因为大部分的控制服务是无状态的,因此,可以通过水平扩展的方式来提供其扩展性。以天河二号为例,他们使用的配置来管理超过 6000 个节点的环境:
OpenStack ─ IceHouse (2014.1) * 8个nova控制节点:运行nova-api和nova-cells; * 8个镜像服务节点:运行glance-*服务; * 8个卷服务节点:运行cinder-*服务; * 8个网络控制节点:运行neutron-server服务; * 16个网络服务节点:运行neutron-*-agent服务; * 8个认证服务节点:运行keystone服务; * 6个消息队列的节点:,运行Rabbitmq; * 6个数据库的节点:运行MySQL; * 4个负载均衡节点,采用LVS+Keepalived实现API节点的调度分发与高可用; * 2个Horizon节点; * 8个ceph 监控节点,运行ceph mon服务; * 16个监控节点:为了实现对当前系统状态的监控与报警,还部署了16个节点用作Ganglia和Nagios的服务器端;
4. 如何设定 OpenStack 企业私有云的扩展性目标
从HP和华为的产品的数据看,各自的扩展性上限的差别非常大;从客户的需求看,从几台计算节点,到几千台计算节点,都有需求。那到底如何来设定一个从技术和成本上都比较合理的扩展性上限呢?本人结合上文的分析,认为下面的设置是比较合理的:
| 规模级别 | 计算节点上限 | 网络方案 | 计算方案 | 实现成本 | 客户需求 | 市场竞争激烈程度 |
| 小 | 200 | 标准 Neutron | 标准 Nova | 低 | 量大,适合于小型客户 | 非常高 |
| 中 | 500 | 优化后的集中式方案,比如优化和裁剪后的标准Neutron 以及 SDN | 类似于 Nova Cell 的分层方案 | 中下 | 适量,适合于中型客户 | 中 |
| 大 | 1000 | 分布式方案,比如分布式 SDN 或者优化后的 Neutron DVR | 类似于 Nova Cell 的分层方案 | 中上 | 较少,适合大型客户,或者 IDC | 低 |
| 超大(公有云规模) | 几千甚至上万 | 需要从各个方面进行修改优化,包括架构修改、代码重写、新功能添加,以及使用第三方的组件,可能能够实现 | 高 | 往往是公有云提供商自行开发 | 仅仅若干厂商才能实现 | |

