

理解 Linux 网络栈(3):QEMU/KVM + VxLAN 环境下的 Segmentation Offloading 技术(发送端)
本系列文章总结 Linux 网络栈,包括:
(2)非虚拟化Linux环境中的网络分段卸载技术 GSO/TSO/UFO/LRO/GRO
(3)QEMU/KVM + VxLAN 环境下的 Segmentation Offloading 技术(发送端)
(4)QEMU/KVM + VxLAN 环境下的 Segmentation Offloading 技术(接收端)
1. 测试环境
1.1 总体环境
- 宿主机:Ubuntu Linux/KVM + VxLAN + Linux bridge,网卡 MTU 9000
- 客户机:Ubuntu Linux + Virtio-net NIC,网卡 MTU 1500,使用 OpenStack Kilo 管理虚机
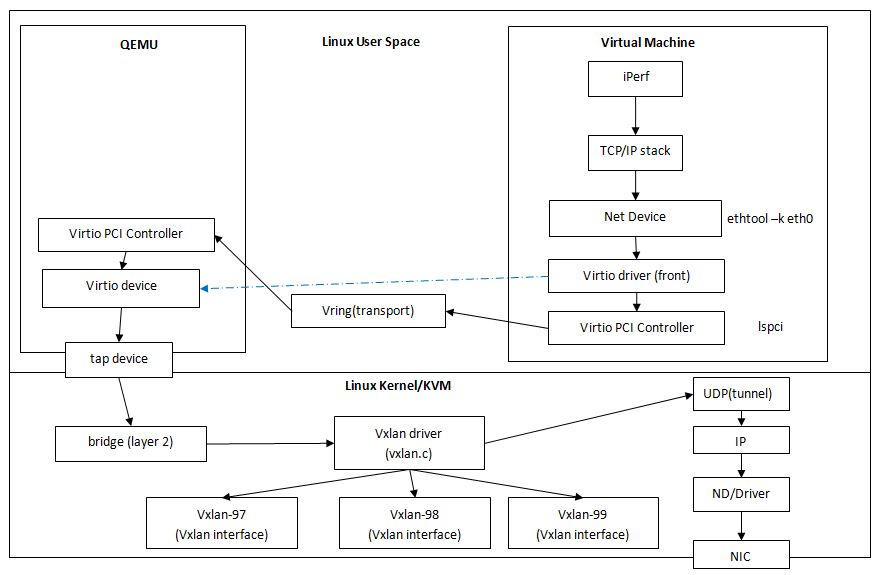
(这是发送端宿主机和客户机示意图)
在发送端,虚机要把一个数据包发出去,需要首先把 packet 经过 virtio 设备发到宿主机的某个 linux bridge,网桥再转发到 xvlan 的虚拟网卡,虚拟网卡把它变成 VxLAN UDP frame,然后发往UDP 层,再通过TCP/IP层再次进行路由,数据包这次会被发往物理网络,并最终抵达接收端端。
1.2 客户机中使用的 virtio-net 虚拟网卡
客户机的 virtio-net 超虚拟化网卡其实是一个使用中断和 DMA 技术实现的 PCI 设备,因此可以使用 lspci 命令查看它的信息:
00:03.0 Ethernet controller [0200]: Red Hat, Inc Virtio network device [1af4:1000]
默认情况下,该网卡的 Segmentation Offloading 全部是打开的:
root@sammyubuntu1:~# ethtool -k eth0 Features for eth0: rx-checksumming: on [fixed] tx-checksumming: on scatter-gather: on tcp-segmentation-offload: on udp-fragmentation-offload: on generic-segmentation-offload: on generic-receive-offload: on large-receive-offload: off [fixed]
2. 发送端的实验和实现
2.1 实验
2.1.1 在客户机和宿主机网卡的 GSO/TSO/UFO 全部打开情况下的实验
(1)iperf 的 MSS 是 1448 bytes
root@sammyubuntu1:~# iperf -c 20.0.0.103 -l 65550 -m -M 400000 WARNING: attempt to set TCP maxmimum segment size to 400000 failed. Setting the MSS may not be implemented on this OS. ------------------------------------------------------------ Client connecting to 20.0.0.103, TCP port 5001 TCP window size: 85.0 KByte (default) ------------------------------------------------------------ [ 3] local 20.0.0.150 port 56228 connected with 20.0.0.103 port 5001 [ ID] Interval Transfer Bandwidth [ 3] 0.0-10.0 sec 1.06 GBytes 908 Mbits/sec [ 3] MSS size 1448 bytes (MTU 1500 bytes, ethernet)
实验表明,客户机中的TCP MSS 只和客户机网卡的 MTU 有关,和其它因素比如宿主机网卡 MTU 没有关系。而且,一个 TCP 连接的两个方向上的 MSS 是可以不同的。正是因为 MSS 的独立性,它可能会产生不同的后果,下文会有阐述。
另外一个有趣的结果是,客户机网卡的 MTU 的大小对网络性能的影响不大。在下面的测试中,客户机网卡 MTU 由 1500 提高到 8000,性能只提高了 6.8%。
<客户机网卡 MTU 1500,宿主机网卡 MTU 9000> root@sammyubuntu1:~# iperf -c 20.0.0.103 -m ------------------------------------------------------------ Client connecting to 20.0.0.103, TCP port 5001 TCP window size: 85.0 KByte (default) ------------------------------------------------------------ [ 3] local 20.0.0.150 port 56275 connected with 20.0.0.103 port 5001 [ ID] Interval Transfer Bandwidth [ 3] 0.0-10.0 sec 1.06 GBytes 909 Mbits/sec [ 3] MSS size 1448 bytes (MTU 1500 bytes, ethernet) <客户机网卡 MTU 8000,宿主机网卡 MTU 9000> root@sammyubuntu1:~# iperf -c 20.0.0.103 -m ------------------------------------------------------------ Client connecting to 20.0.0.103, TCP port 5001 TCP window size: 325 KByte (default) ------------------------------------------------------------ [ 3] local 20.0.0.150 port 56274 connected with 20.0.0.103 port 5001 [ ID] Interval Transfer Bandwidth [ 3] 0.0-10.0 sec 1.14 GBytes 977 Mbits/sec [ 3] MSS size 7948 bytes (MTU 7988 bytes, unknown interface)
(2)客户机网卡:Frame 的 size 明显超过了 MSS,说明在启用了 GSO/TSO 的情况下,只要每个数据包不超过 IP 包的最大大小 64k,virtio-net 网卡就可以直接经过 virtqueue 发给 QEMU 中的backend。检验码报错,说明校验和计算被卸载到了网卡上,但是可能网卡计算错误。
20.0.0.150.56230 > 20.0.0.103.5001: Flags [.], cksum 0x2ecb (incorrect -> 0xc064), seq 438742392:438743840, ack 1, win 229, options [nop,nop,TS val 7353870 ecr 564507], length 1448
20.0.0.150.56230 > 20.0.0.103.5001: Flags [.], cksum 0x27ac (incorrect -> 0x74c2), seq 1119980056:1120045216, ack 1, win 229, options [nop,nop,TS val 7355371 ecr 566008], length 65160
(3)宿主机上客户机网卡对应的 tap 设备:跟客户机网卡中看到的一样,说明 QEMU 中的 virtio-queue(backend)和 宿主机中的 tap 网络设备都是对这些 packets 直接发送的,没有做任何分包等操作。
08:12:23.443278 fa:16:3e:a3:a0:55 > fa:16:3e:1e:d9:f4, ethertype IPv4 (0x0800), length 61322: (tos 0x0, ttl 64, id 52865, offset 0, flags [DF], proto TCP (6), length 61308) 20.0.0.150.56238 > 20.0.0.103.5001: Flags [.], cksum 0x186c (incorrect -> 0xad42), seq 896238816:896300072, ack 1, win 157, options [nop,nop,TS val 7598521 ecr 809156], length 61256 08:12:23.443355 fa:16:3e:a3:a0:55 > fa:16:3e:1e:d9:f4, ethertype IPv4 (0x0800), length 3030: (tos 0x0, ttl 64, id 52927, offset 0, flags [DF], proto TCP (6), length 3016) 20.0.0.150.56238 > 20.0.0.103.5001: Flags [.], cksum 0x34b7 (incorrect -> 0x97b3), seq 896300072:896303036, ack 1, win 157, options [nop,nop,TS val 7598521 ecr 809156], length 2964
(4)宿主机内的连接 tap 设备和vxlan interface 的 linux bridge:帧的大小超过其 MTU,说明它直接转发经过 GSO/TSO 合并后的帧。
oot@hkg02kvm004ccz023:~# ifconfig brq137db7ce-a4 brq137db7ce-a4 Link encap:Ethernet HWaddr 36:7e:1f:8e:65:a0 UP BROADCAST RUNNING MULTICAST MTU:8950 Metric:1 RX packets:594948 errors:0 dropped:0 overruns:0 frame:0 TX packets:0 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:0 RX bytes:1058392082 (1.0 GB) TX bytes:0 (0.0 B) 08:18:39.574679 fa:16:3e:a3:a0:55 > fa:16:3e:1e:d9:f4, ethertype IPv4 (0x0800), length 52430: (tos 0x0, ttl 64, id 1585, offset 0, flags [DF], proto TCP (6), length 52416) 20.0.0.150.56238 > 20.0.0.103.5001: Flags [.], cksum 0xf5af (incorrect -> 0x47b1), seq 7027645:7080009, ack 0, win 157, options [nop,nop,TS val 7692554 ecr 903188], length 52364 08:18:39.574784 fa:16:3e:a3:a0:55 > fa:16:3e:1e:d9:f4, ethertype IPv4 (0x0800), length 52430: (tos 0x0, ttl 64, id 1638, offset 0, flags [DF], proto TCP (6), length 52416)
(5)宿主机内的 vxlan-interface:帧的大小超过其 MTU,说明它直接转发经过 GSO/TSO 合并后的帧
root@hkg02kvm004ccz023:~# ifconfig vxlan-97 vxlan-97 Link encap:Ethernet HWaddr d6:7e:83:70:40:b2 UP BROADCAST RUNNING MULTICAST MTU:8950 Metric:1 RX packets:44754025 errors:0 dropped:0 overruns:0 frame:0 TX packets:5179964 errors:0 dropped:2 overruns:0 carrier:0 collisions:0 txqueuelen:0 RX bytes:2381558146 (2.3 GB) TX bytes:89661075401 (89.6 GB) 08:16:54.685914 fa:16:3e:a3:a0:55 > fa:16:3e:1e:d9:f4, ethertype IPv4 (0x0800), length 1054: (tos 0x0, ttl 64, id 14493, offset 0, flags [DF], proto TCP (6), length 1040) 20.0.0.150.56238 > 20.0.0.103.5001: Flags [.], cksum 0x2cff (incorrect -> 0x3143), seq 60291712:60292700, ack 1, win 157, options [nop,nop,TS val 7666332 ecr 876964], length 988 08:16:54.685936 fa:16:3e:a3:a0:55 > fa:16:3e:1e:d9:f4, ethertype IPv4 (0x0800), length 24766: (tos 0x0, ttl 64, id 14494, offset 0, flags [DF], proto TCP (6), length 24752) 20.0.0.150.56238 > 20.0.0.103.5001: Flags [.], cksum 0x899f (incorrect -> 0xf01d), seq 60292700:60317400, ack 1, win 157, options [nop,nop,TS val 7666332 ecr 876964], length 24700
(6)宿主机 VxLAN UDP socket 所绑定的物理网卡:测试了三种情况,证明了网卡是按照 MSS 进行 IP 分片的。
当 TCP 连接的 MSS 是 988 时: 08:19:34.286094 IP 10.110.156.43.33980 > 10.110.156.42.4789: VXLAN, flags [I] (0x08), vni 97 IP 20.0.0.150.56238 > 20.0.0.103.5001: Flags [.], seq 96306288:96307276, ack 1, win 157, options [nop,nop,TS val 7706232 ecr 916866], length 988 当 TCP 连接的 MSS 是 1448 时: 07:45:24.008510 IP 10.110.156.43.44429 > 10.110.156.42.4789: VXLAN, flags [I] (0x08), vni 97 IP 20.0.0.150.56228 > 20.0.0.103.5001: Flags [.], seq 126000:127448, ack 1, win 229, options [nop,nop,TS val 7193663 ecr 404323], length 1448 如果将网卡的 MTU 调到比 MSS (1448)还小,比如 1400,则会出现 IP 分片,说明 GSO 还是按照 MSS 分段,而不是按照 MTU 或者 [MTU, MSS] 中的较小值来分段: 08:39:35.743048 IP 10.110.156.43.41903 > 10.110.156.42.4789: VXLAN, flags [I] (0x08), vni 97 IP truncated-ip - 154 bytes missing! 20.0.0.150.56246 > 20.0.0.103.5001: Flags [.], seq 12179152:12180600, ack 1, win 188, options [nop,nop,TS val 8006596 ecr 1217232], length 1448
2.1.2 在客户机关闭 GSO/TSO/UFO
root@sammyubuntu1:~# iperf -c 20.0.0.103 -l 65550 -m ------------------------------------------------------------ Client connecting to 20.0.0.103, TCP port 5001 TCP window size: 325 KByte (default) ------------------------------------------------------------ [ 3] local 20.0.0.150 port 56269 connected with 20.0.0.103 port 5001 [ ID] Interval Transfer Bandwidth [ 3] 0.0-10.0 sec 1.00 GBytes 859 Mbits/sec [ 3] MSS size 1448 bytes (MTU 1500 bytes, ethernet) 客户机网卡:在客户机 CPU 中进行了 TCP 分段 10:02:41.474750 IP (tos 0x0, ttl 64, id 59282, offset 0, flags [DF], proto TCP (6), length 1500) 20.0.0.150.56269 > 20.0.0.103.5001: Flags [.], cksum 0x2ecb (incorrect -> 0x1924), seq 1795544:1796992, ack 1, win 229, options [nop,nop,TS val 9253025 ecr 2463660], length 1448
该过程说明客户机中产生了 TCP 分段;对网络性能有一定的下降。
2.1.3 虚机 TSO/GSO 打开 和宿主机的 GSO/TSO 关闭
客户机网卡:传输 GSO 大帧 09:47:35.894971 IP (tos 0x0, ttl 64, id 5902, offset 0, flags [DF], proto TCP (6), length 65212) 20.0.0.150.56263 > 20.0.0.103.5001: Flags [.], cksum 0x27ac (incorrect -> 0xdeb7), seq 893020126:893085286, ack 1, win 229, options [nop,nop,TS val 9026630 ecr 2237265], length 65160vxlan-interface 设备:直接转发 09:53:15.457088 fa:16:3e:a3:a0:55 > fa:16:3e:1e:d9:f4, ethertype IPv4 (0x0800), length 65226: (tos 0x0, ttl 64, id 43361, offset 0, flags [DF], proto TCP (6), length 65212) 20.0.0.150.56267 > 20.0.0.103.5001: Flags [.], cksum 0x27ac (incorrect -> 0x2e18), seq 1127931208:1127996368, ack 1, win 229, options [nop,nop,TS val 9111525 ecr 2322160], length 65160 宿主机物理网卡:发送size 为 TCP MSS 的小帧 09:50:41.251821 IP 10.110.156.43.12914 > 10.110.156.42.4789: VXLAN, flags [I] (0x08), vni 97 IP 20.0.0.150.56265 > 20.0.0.103.5001: Flags [.], seq 80044016:80045464, ack 1, win 229, options [nop,nop,TS val 9072973 ecr 2283609], length 1448
该过程说明这里产生了 UDP/IP 分片。
2.1.4 TCP 传输性能比较
客户机和宿主机GSO/TSO/UFO都打开 > 客户机打开宿主机关闭 > 客户机关闭。
2.2 Linux 内核支持 GSO for UDP tunnels:“udp: Generalize GSO for UDP tunnels”
这个支持是在 2014 年才加入 Linux 内核的,更多信息请参考原文 https://lwn.net/Articles/613999/。这个 patch 在 GSO 中添加了对 UDP 隧道技术的支持。
- 需要在 skb 发到 UDP 协议栈之前,添加一个新的 option:inner_protocol,可以使用方法 skb_set_inner_ipproto 或者 skb_set_inner_protocol 来设置。vxlan driver 中的相关代码为 skb_set_inner_protocol(skb, htons(ETH_P_TEB));
- 函数
skb_udp_tunnel_segment 会检查该 option 再处理分段。
- 支持多种类型的封装,包括 SKB_GSO_UDP_TUNNEL{_CSUM}
2.3 VxLAN 的实现
代码在这里:https://github.com/torvalds/linux/blob/master/drivers/net/vxlan.c
2.3.1 VxLAN interface
跟名字一样,VxLAN interface 也是当做一个 network device interface 来使用的,vxlan.c 文件中实现了其驱动的逻辑。它处于数据链路层的 device driver 层,实现了 vxlan interface 的 device driver。vxlan interface 同样可以使用 ethtool 查看其 segmentation offloading 能力:
root@hkg02kvm004ccz023:~# ethtool -k vxlan-4 | grep offload tcp-segmentation-offload: on udp-fragmentation-offload: on generic-segmentation-offload: on generic-receive-offload: on large-receive-offload: off [fixed] rx-vlan-offload: off [fixed] tx-vlan-offload: on l2-fwd-offload: off [fixed]
其驱动设置了 net_device_ops结构体变量, 其中定义了操作 net_device 的重要函数,vxlan在驱动程序中根据需要的操作要填充这些函数,其中主要是 packets 的接收和发送处理函数。
static const struct net_device_ops vxlan_netdev_ops = { .ndo_init = vxlan_init, .ndo_uninit = vxlan_uninit, .ndo_open = vxlan_open, .ndo_stop = vxlan_stop, .ndo_start_xmit = vxlan_xmit, #向 vxlan interface 发送 packet ... };
来看看代码实现:
(1)首先看 static netdev_tx_t vxlan_xmit(struct sk_buff *skb, struct net_device *dev) 方法,它的输入就是要传输的 packets 所对应的 sk_buff 以及要经过的 vxlan interface dev:
它的主要逻辑是获取 vxlan dev,然后为 sk_buff 中的每一个 skb 调用 vxlan_xmit_skb 方法。
#该方法主要逻辑是,计算 tos,ttl,df,src_port,dst_port,md 以及 flags等,然后调用 vxlan_xmit_skb 方法。
err = vxlan_xmit_skb(rt, sk, skb, fl4.saddr, dst->sin.sin_addr.s_addr, tos, ttl, df, src_port, dst_port, htonl(vni << 8), md, !net_eq(vxlan->net, dev_net(vxlan->dev)), flags);
(2)vxlan_xmit_skb 函数修改了 skb,添加了 VxLAN Header,以及设置 GSO 参数。
static int vxlan_xmit_skb(struct rtable *rt, struct sock *sk, struct sk_buff *skb, __be32 src, __be32 dst, __u8 tos, __u8 ttl, __be16 df, __be16 src_port, __be16 dst_port, __be32 vni, struct vxlan_metadata *md, bool xnet, u32 vxflags) { ...int type = udp_sum ? SKB_GSO_UDP_TUNNEL_CSUM : SKB_GSO_UDP_TUNNEL; #计算 GSO UDP 相关的 offload type,使得能够利用内核 GSO for UDP Tunnel u16 hdrlen = sizeof(struct vxlanhdr); #计算 vxlan header 的长度 ...
#计算 skb 新的 headroom,其中包含了 VXLAN Header 的长度 min_headroom = LL_RESERVED_SPACE(rt->dst.dev) + rt->dst.header_len + VXLAN_HLEN + sizeof(struct iphdr) + (skb_vlan_tag_present(skb) ? VLAN_HLEN : 0); /* Need space for new headers (invalidates iph ptr) */ err = skb_cow_head(skb, min_headroom); #使得 skb head 可写 ... skb = vlan_hwaccel_push_inside(skb); #处理 vlan 相关事情 ... skb = iptunnel_handle_offloads(skb, udp_sum, type); #设置 checksum 和 type ... vxh = (struct vxlanhdr *) __skb_push(skb, sizeof(*vxh)); #扩展 skb data area,来容纳 vxlan header vxh->vx_flags = htonl(VXLAN_HF_VNI); vxh->vx_vni = vni; ... if (vxflags & VXLAN_F_GBP) vxlan_build_gbp_hdr(vxh, vxflags, md); skb_set_inner_protocol(skb, htons(ETH_P_TEB)); #设置 Ethernet protocol,这是 GSO 在 UDP tunnel 中必须要的 udp_tunnel_xmit_skb(rt, sk, skb, src, dst, tos, ttl, df, #调用 linux 网络栈接口,将 skb 传给 udp tunnel 协议栈继续处理 src_port, dst_port, xnet, !(vxflags & VXLAN_F_UDP_CSUM)); return 0; }

(3)接下来就进入了 Linux TCP/IP 协议栈,从 UDP 进入,然后再到 IP 层。如果硬件支持,则由硬件调用 linux 内核中的 UDP GSO 函数;如果硬件不支持,则在进入 device driver queue 之前由 linux 内核调用 UDP GSO 分片函数。然后再一直往下到网卡。
最终在这个函数 ip_finish_output_gso 里面,先调用 GSO分段函数,如果需要的话,再进行 IP 分片:
static int ip_finish_output_gso(struct net *net, struct sock *sk, struct sk_buff *skb, unsigned int mtu) { netdev_features_t features; struct sk_buff *segs; int ret = 0; /* Slowpath - GSO segment length is exceeding the dst MTU. * * This can happen in two cases: * 1) TCP GRO packet, DF bit not set * 2) skb arrived via virtio-net, we thus get TSO/GSO skbs directly * from host network stack. */ features = netif_skb_features(skb); segs = skb_gso_segment(skb, features & ~NETIF_F_GSO_MASK); #这里最终会调用到 UDP 的 gso_segment 回调函数进行 UDP GSO 分段 if (IS_ERR_OR_NULL(segs)) { kfree_skb(skb); return -ENOMEM; } consume_skb(skb); do { struct sk_buff *nskb = segs->next; int err; segs->next = NULL; err = ip_fragment(net, sk, segs, mtu, ip_finish_output2); #需要的话,再进行 IP 分片,因为 UDP GSO 是按照 MSS 进行,MSS 还是有可能超过 IP 分段所使用的宿主机物理网卡 MTU 的 if (err && ret == 0) ret = err; segs = nskb; } while (segs); return ret; }
这是 UDP 层所注册的 gso 回调函数:
static const struct net_offload udpv4_offload = { .callbacks = { .gso_segment = udp4_ufo_fragment, .gro_receive = udp4_gro_receive, .gro_complete = udp4_gro_complete, }, };
它的实现在这里:
static struct sk_buff *__skb_udp_tunnel_segment(struct sk_buff *skb, netdev_features_t features, struct sk_buff *(*gso_inner_segment)(struct sk_buff *skb, netdev_features_t features), __be16 new_protocol) { .../* segment inner packet. */ #先调用内层的 分段函数进行分段 enc_features = skb->dev->hw_enc_features & netif_skb_features(skb); segs = gso_inner_segment(skb, enc_features); ... skb = segs; do { #执行 UDP GSO 分段 struct udphdr *uh; int len; skb_reset_inner_headers(skb); skb->encapsulation = 1; skb->mac_len = mac_len; skb_push(skb, outer_hlen); skb_reset_mac_header(skb); skb_set_network_header(skb, mac_len); skb_set_transport_header(skb, udp_offset); len = skb->len - udp_offset; uh = udp_hdr(skb); uh->len = htons(len); ... skb->protocol = protocol; } while ((skb = skb->next)); out: return segs; } struct sk_buff *skb_udp_tunnel_segment(struct sk_buff *skb, netdev_features_t features, bool is_ipv6) { ...switch (skb->inner_protocol_type) { #计算内层的分片方法 case ENCAP_TYPE_ETHER: #感觉 vxlan 的 GSO 应该是走这个分支,相当于是将 VXLAN 所封装的二层帧当做 payload 来分段,而不是将包含 VXLAN Header 的部分来分 protocol = skb->inner_protocol; gso_inner_segment = skb_mac_gso_segment; break; case ENCAP_TYPE_IPPROTO: offloads = is_ipv6 ? inet6_offloads : inet_offloads; ops = rcu_dereference(offloads[skb->inner_ipproto]); if (!ops || !ops->callbacks.gso_segment) goto out_unlock; gso_inner_segment = ops->callbacks.gso_segment; break; default: goto out_unlock; } segs = __skb_udp_tunnel_segment(skb, features, gso_inner_segment, protocol); ... return segs; #返回分片好的seg list }
这里比较有疑问的是,VXLAN 没有定义 gso_segment 回调函数,这导致有可能在 UDP GSO 分段里面没有完整的 VXLAN Header。。这需要进一步研究。原因可能是在 inner segment 那里,分段是将 UDP 所封装的二层帧当做 payload 来分段,因此,VXLAN Header 就会保持在每个分段中。
(4)可见,在整个过程中,有客户机上 TCP 协议层设置的 skb_shinfo(skb)->gso_size 始终保持不变为 MSS,因此,在网卡中最终所做的针对 UDP GSO 数据报的 GSO 分片所依据的分片的长度还是根据 skb_shinfo(skb)->gso_size 的值即 TCP MSS。
3. 发送端现有方案的问题和改进方法
3.1 问题
从上面所描述的过程可以看出来,目前的 VXLAN 协议和实现中存在一个问题,那就是:最终在宿主机上所做的 IP 分片是根据客户机中 TCP 连接的 MSS 来进行的,而实际的网络环境中,宿主机的网卡的 MTU 往往采用巨帧技术设置为 9000 bytes,而客户机的网卡 MTU 往往使用默认的 1500 bytes,在接收端也是同样类型的节点的情况下,目前的分片方式存在很大的资源浪费。
理想的情况分为几种:
- (1)如果接收端是同样的采用 VXLAN VETP 的节点,IP 分片应该按照物理网卡的 MTU 进行,到了对端做了 IP 分片重组后,直接由 VXLAN VTEP 交给虚机。
- (2)如果对方是将会连接外网的 VXLAN Gateway 节点,那对端 VXLAN VTEP 收到 IP 分片重组后的大网络包后,它自己或者使用 Linux 网络协议栈 segmentation offloading 技术对大包进行分片,然后再转发到外网。
- (3)如果对方是普通网络节点(此时发送端是 VXLAN Gateway 节点),那么走当前的模式,根据 TCP MSS 使用 UDP/IP 分片,再发出去。
3.2 一种实现方案
文章 Segmentation Offloading Extension for VXLAN 提出了一种 VXLAN Segmentation Offloading Extension (VXLAN-soe) 实现方案。该方案扩展了 VXLAN Header,添加了几个新的标志位:(S - 标志位,是否使用该技术; Overlay MSS Hi 和 Lo:对 TCP,就是 MSS;对 UDP,就是 MTU)
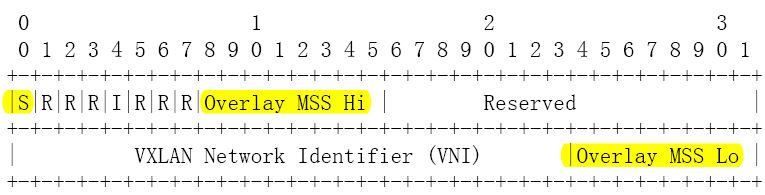
发送端 VXLAN VTEP 根据配置或者别的条件
- 设置 S = 1,表示 offload segmentation 到对端节点上的 VXLAN VTEP,并设置 Overlay MSS Hi 和 Lo
- 设置 S= 0,表示不做 remote segmentation offloading,做普通的处理
接收端 VXLAN Hypervisor VTEP 将检查 S 标志位:
- 如果为 1,则不做 MTU 检查,直接将包交给虚机
- S 标志位,如果为 0,则走普通处理流程
接收端 VXLAN Gateway VTEP:
- 检查 S 标志位,如果为 1,则它自己或者利用 segmentation offloading 技术做分片
该方案的问题是当 S = 1 时,会产生 UDP/IP 分片。
另一篇文章 MTU and Fragmentation Issues with In-the-Network Tunneling 也讨论了使用隧道时候的各种分片方案。它讨论的主要问题包括:
- 要不要在发送端分片
- 要不要在接收端重组,以及如何重组
- 要不要使用 PMTU。不使用的话,如何避免

 浙公网安备 33010602011771号
浙公网安备 33010602011771号