

理解 OpenStack 高可用(HA) (4): Pacemaker 和 OpenStack Resource Agent (RA)
本系列会分析OpenStack 的高可用性(HA)概念和解决方案:
(2)Neutron L3 Agent HA - VRRP (虚拟路由冗余协议)
(3)Neutron L3 Agent HA - DVR (分布式虚机路由器)
(4)Pacemaker 和 OpenStack Resource Agent (RA)
(5)RabbitMQ HA
(6)MySQL HA
1. Pacemaker
1.1 概述
Pacemaker 承担集群资源管理者(CRM - Cluster Resource Manager)的角色,它是一款开源的高可用资源管理软件,适合各种大小集群。Pacemaker 由 Novell 支持,SLES HAE 就是用 Pacemaker 来管理集群,并且 Pacemaker 得到了来自Redhat,Linbit等公司的支持。它用资源级别的监测和恢复来保证集群服务(aka. 资源)的最大可用性。它可以用基础组件(Corosync 或者是Heartbeat)来实现集群中各成员之间的通信和关系管理。它包含以下的关键特性:
- 监测并恢复节点和服务级别的故障
- 存储无关,并不需要共享存储
- 资源无关,任何能用脚本控制的资源都可以作为服务
- 支持使用 STONITH 来保证数据一致性
- 支持大型或者小型的集群
- 支持 quorum (仲裁) 或 resource(资源) 驱动的集群
- 支持任何的冗余配置
- 自动同步各个节点的配置文件
- 可以设定集群范围内的 ordering, colocation and anti-colocation
- 支持高级的服务模式
1.2 Pacemaker 集群的架构
1.2.1 软件架构
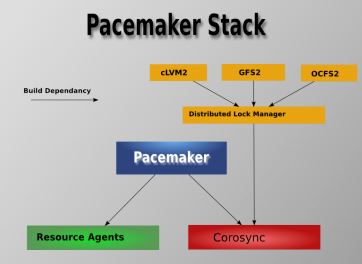
- Pacemaker - 资源管理器(CRM),负责启动和停止服务,而且保证它们是一直运行着的以及某个时刻某服务只在一个节点上运行(避免多服务同时操作数据造成的混乱)。
- Corosync - 消息层组件(Messaging Layer),管理成员关系、消息和仲裁。见 1.2 部分介绍。
- Resource Agents - 资源代理,实现在节点上接收 CRM 的调度对某一个资源进行管理的工具,这个管理的工具通常是脚本,所以我们通常称为资源代理。任何资源代理都要使用同一种风格,接收四个参数:{start|stop|restart|status},包括配置IP地址的也是。每个种资源的代理都要完成这四个参数据的输出。Pacemaker 的 RA 可以分为三种:(1)Pacemaker 自己实现的 (2)第三方实现的,比如 RabbitMQ 的 RA (3)自己实现的,比如 OpenStack 实现的它的各种服务的RA,这是 mysql 的 RA。
1.2.2 Pacemaker 支持的集群类型
Pacemaker 支持多种类型的集群,包括 Active/Active, Active/Passive, N+1, N+M, N-to-1 and N-to-N 等。
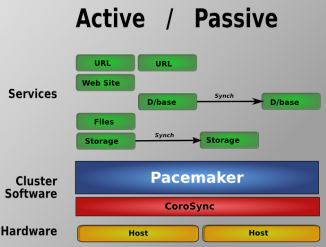
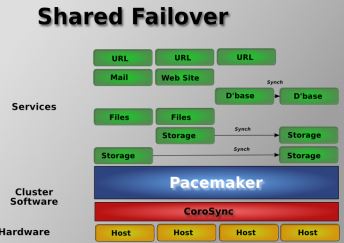

这里 有详细的 Pacemaker 安装方法。这是 中文版。这篇文章 提到了 Pacemaker 的一些问题和替代方案。
1.3 Corosync
Corosync 用于高可用环境中提供通讯服务,位于高可用集群架构中的底层,扮演着为各节点(node)之间提供心跳信息传递这样的一个角色。Pacemaker 位于 HA 集群架构中资源管理、资源代理这么个层次,它本身不提供底层心跳信息传递的功能,它要想与对方节点通信就需要借助底层的心跳传递服务,将信息通告给对方。

关于心跳的基本概念:
- 心跳:就是将多台服务器用网络连接起来,而后每一台服务器都不停的将自己依然在线的信息使用很简短很小的通告给同一个网络中的其它主机,告诉它们自己依然在线,其它服务器收到这个心跳信息就认为它是在线的,尤其是主服务器。
- 心跳信息怎么发送,由谁来收,其实就是进程间通信。两台主机是没法通信的,只能利用网络功能,通过进程监听在某一套接字上,实现数据发送,数据请求,所以多台服务器就得运行同等的进程,这两个进程不停的进行通信,主节点(主服务器)不停的向对方同等的节点发送自己的心跳信息,那这个软件就叫高可用的集群的基准层次,也叫心跳信息传递层以及事物信息的传递层,这是运行在集群中的各节点上的进程,这个进程是个服务软件,关机后需要将其启动起来,主机间才可以传递信息的,一般是主节点传给备节点。
这篇文章 详细介绍了其原理。
1.4 Fencing Agent
一个 Pacemaker 集群往往需要使用 Fencing agent。https://alteeve.ca/w/ANCluster_Tutorial_2#Concept.3B_Fencing 详细地阐述了Fencing的概念及其必要性。Fencing 是在一个节点不稳定或者无答复时将其关闭,使得它不会损坏集群的其它资源,其主要用途是消除脑裂。
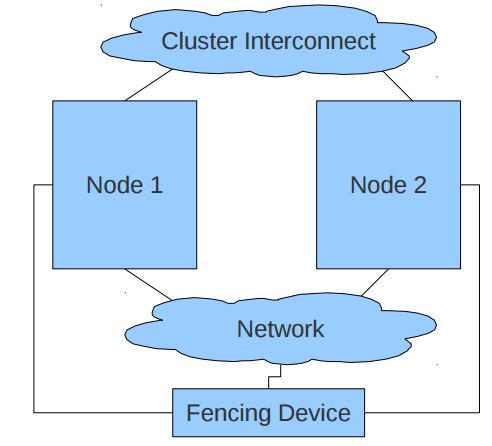
通常有两种类型的 Fencing agent:power(电源)和 storage (存储)。Power 类型的 Agent 会将节点的电源断电,它通常连到物理的设备比如UPS;Storage 类型的Agent 会确保某个时刻只有一个节点会读写共享的存储。
1.5 资源代理(Resource Agent - RA)
一个 RA 是管理一个集群资源的可执行程序,没有固定其实现的编程语言,但是大部分RA都是用 shell 脚本实现的。Pacemaker 使用 RA 来和受管理资源进行交互,它既支持它自身实现的70多个RA,也支持第三方RA。Pacemaker 支持三种类型的 RA:
主流的 RA 都是 OCF 类型的。RA 支持的主要操作包括:
- start: enable or start the given resource
- stop: disable or stop the given resource
- monitor: check whether the given resource is running (and/or doing useful work), return status as running or not running
- validate-all: validate the resource's configuration
- meta-data: return information about the resource agent itself (used by GUIs and other management utilities, and documentation tools)
- some more, see OCF Resource Agents and the Pacemaker documentation for details.
在一个 OpenStack Pacemaker 集群中,往往都包括这几种类型的 RA,比如:
- MySQL 和 Apache RA 是 Pacemaker native 的。更多的原生 RA 在 http://www.linux-ha.org/wiki/Resource_agents 中可以查看。
- RabbitMQ RA 和 OpenStack RA 也是第三方的
在 OpenStack 控制节点Pacemaker集群中各组件:

- CIB 是个分布式的XML 文件,有用户添加配置
- Pacemaker 和 Corosync 根据 CIB 控制 LRMD 的行为
- LRMD 通过调用 RA 的接口控制各资源的行为
1.5.1 RA 的实现
要实现一个 RA, 需要遵守 OCF 的规范,其规范在 http://www.opencf.org/cgi-bin/viewcvs.cgi/specs/ra/resource-agent-api.txt?rev=HEAD
下面以OpenStack Glance-api RA 为例,说明其功能。其代码在 https://github.com/openstack/openstack-resource-agents/blob/master/ocf/glance-api,本身其实是一个 shell 脚本。

usage() { #RA 的功能,包括 start,stop,validate-all,meta-data,status 和 monitor glance-api 等,每个对应下面的一个函数 cat <<UEND usage: $0 (start|stop|validate-all|meta-data|status|monitor) $0 manages an OpenStack ImageService (glance-api) process as an HA resource The 'start' operation starts the imaging service. The 'stop' operation stops the imaging service. The 'validate-all' operation reports whether the parameters are valid The 'meta-data' operation reports this RA's meta-data information The 'status' operation reports whether the imaging service is running The 'monitor' operation reports whether the imaging service seems to be working UEND } meta_data() { #meta-data 功能,输出一段XML cat <<END ... END } ####################################################################### # Functions invoked by resource manager actions glance_api_validate() { #检查 glance-api,比如libaray是否存在,配置文件是否存在,RA 使用的用户是否存在 local rc check_binary $OCF_RESKEY_binary check_binary $OCF_RESKEY_client_binary # A config file on shared storage that is not available # during probes is OK. if [ ! -f $OCF_RESKEY_config ]; then if ! ocf_is_probe; then ocf_log err "Config $OCF_RESKEY_config doesn't exist" return $OCF_ERR_INSTALLED fi ocf_log_warn "Config $OCF_RESKEY_config not available during a probe" fi getent passwd $OCF_RESKEY_user >/dev/null 2>&1 rc=$? if [ $rc -ne 0 ]; then ocf_log err "User $OCF_RESKEY_user doesn't exist" return $OCF_ERR_INSTALLED fi true } glance_api_status() { #获取运行状态,通过检查 pid 文件来确认 glance-api 是否在运行 local pid local rc if [ ! -f $OCF_RESKEY_pid ]; then ocf_log info "OpenStack ImageService (glance-api) is not running" return $OCF_NOT_RUNNING else pid=`cat $OCF_RESKEY_pid` fi ocf_run -warn kill -s 0 $pid rc=$? if [ $rc -eq 0 ]; then return $OCF_SUCCESS else ocf_log info "Old PID file found, but OpenStack ImageService (glance-api) is not running" return $OCF_NOT_RUNNING fi } glance_api_monitor() { #监控 glance-api 服务的运行状态,通过运行 glance image-list 命令 local rc glance_api_status rc=$? # If status returned anything but success, return that immediately if [ $rc -ne $OCF_SUCCESS ]; then return $rc fi # Monitor the RA by retrieving the image list if [ -n "$OCF_RESKEY_os_username" ] && [ -n "$OCF_RESKEY_os_password" ] \ && [ -n "$OCF_RESKEY_os_tenant_name" ] && [ -n "$OCF_RESKEY_os_auth_url" ]; then ocf_run -q $OCF_RESKEY_client_binary \ --os_username "$OCF_RESKEY_os_username" \ --os_password "$OCF_RESKEY_os_password" \ --os_tenant_name "$OCF_RESKEY_os_tenant_name" \ --os_auth_url "$OCF_RESKEY_os_auth_url" \ index > /dev/null 2>&1 rc=$? if [ $rc -ne 0 ]; then ocf_log err "Failed to connect to the OpenStack ImageService (glance-api): $rc" return $OCF_NOT_RUNNING fi fi ocf_log debug "OpenStack ImageService (glance-api) monitor succeeded" return $OCF_SUCCESS } glance_api_start() { #启动 glance-api 服务 local rc glance_api_status rc=$? if [ $rc -eq $OCF_SUCCESS ]; then ocf_log info "OpenStack ImageService (glance-api) already running" return $OCF_SUCCESS fi # run the actual glance-api daemon. Don't use ocf_run as we're sending the tool's output # straight to /dev/null anyway and using ocf_run would break stdout-redirection here. su ${OCF_RESKEY_user} -s /bin/sh -c "${OCF_RESKEY_binary} --config-file $OCF_RESKEY_config \ $OCF_RESKEY_additional_parameters"' >> /dev/null 2>&1 & echo $!' > $OCF_RESKEY_pid # Spin waiting for the server to come up. # Let the CRM/LRM time us out if required while true; do glance_api_monitor rc=$? [ $rc -eq $OCF_SUCCESS ] && break if [ $rc -ne $OCF_NOT_RUNNING ]; then ocf_log err "OpenStack ImageService (glance-api) start failed" exit $OCF_ERR_GENERIC fi sleep 1 done ocf_log info "OpenStack ImageService (glance-api) started" return $OCF_SUCCESS } glance_api_stop() { #停止 glance-api 服务 local rc local pid glance_api_status rc=$? if [ $rc -eq $OCF_NOT_RUNNING ]; then ocf_log info "OpenStack ImageService (glance-api) already stopped" return $OCF_SUCCESS fi # Try SIGTERM pid=`cat $OCF_RESKEY_pid` ocf_run kill -s TERM $pid rc=$? if [ $rc -ne 0 ]; then ocf_log err "OpenStack ImageService (glance-api) couldn't be stopped" exit $OCF_ERR_GENERIC fi # stop waiting shutdown_timeout=15 if [ -n "$OCF_RESKEY_CRM_meta_timeout" ]; then shutdown_timeout=$((($OCF_RESKEY_CRM_meta_timeout/1000)-5)) fi count=0 while [ $count -lt $shutdown_timeout ]; do glance_api_status rc=$? if [ $rc -eq $OCF_NOT_RUNNING ]; then break fi count=`expr $count + 1` sleep 1 ocf_log debug "OpenStack ImageService (glance-api) still hasn't stopped yet. Waiting ..." done glance_api_status rc=$? if [ $rc -ne $OCF_NOT_RUNNING ]; then # SIGTERM didn't help either, try SIGKILL ocf_log info "OpenStack ImageService (glance-api) failed to stop after ${shutdown_timeout}s \ using SIGTERM. Trying SIGKILL ..." ocf_run kill -s KILL $pid fi ocf_log info "OpenStack ImageService (glance-api) stopped" rm -f $OCF_RESKEY_pid return $OCF_SUCCESS } ####################################################################### case "$1" in meta-data) meta_data exit $OCF_SUCCESS;; usage|help) usage exit $OCF_SUCCESS;; esac # Anything except meta-data and help must pass validation glance_api_validate || exit $? # What kind of method was invoked? case "$1" in start) glance_api_start;; stop) glance_api_stop;; status) glance_api_status;; monitor) glance_api_monitor;; validate-all) ;; *) usage exit $OCF_ERR_UNIMPLEMENTED;; esac
1.5.2 RA 的配置
(1)因为上述的 RA 是第三方的,因此需要将它下载到本地,RA 所在的文件夹是 /usr/lib/ocf/resource.d/provider,对 OpenStack 来说,就是 /usr/lib/ocf/resource.d/openstack。然后设置其权限为可运行。
(2)通过运行 crm configure,输入下面的配置,就可以创建一个 Pacemaker 资源来对 glance-api 服务进行 monitor:
primitive p_glance-api ocf:openstack:glance-api \ params config="/etc/glance/glance-api.conf" os_password="secretsecret" \ os_username="admin" os_tenant_name="admin" os_auth_url="http://192.168.42. 103:5000/v2.0/" \ op monitor interval="30s" timeout="30s"
该配置指定了:
- ocf:openstack:glance-api: ”ocf“ 是指该 RA 的类型,”openstack“ 是指RA 的 namespace,”glance-api“ 是 RA 可执行程序的名称。
- os_* 和 interval 和 timeout 参数参数(monitor 函数会用到)
- glance-api 和 config 文件 (在 start 和 stop 中会用到)
- ”op monitor“ 表示对该资源进行 monitor,如果失败,则执行默认的行为 restart(先 stop 再 start)(注意这里Pacemaker 有可能在另一个节点上重启,OpenStack 依赖其它约束比如 Pacemaker resource group 等来进行约束)
- ”interval = 30s“ 表示 monitor 执行的间隔是 30s
- ”timeout = 30“ 表示每次 monitor 的最长等待时间为 30s
- 另外,其实这里可以指定该资源为 clone 类型,表示它会分布在两个节点上运行于 active/active 模式;既然这里没有设置,它就只运行在一个节点上。
- 另外,Pacemaker 1.1.18 版本之后,crm configure 命令被移除了,取而代之的是 pcs 命令。
(3)创建一个 service group
group g_services_api p_api-ip p_keystone p_glance-api p_cinder-api p_neutron-server p_glance-registry p_ceilometer-agent-central
Pacemaker group 的一些特性:
- 一个 group 中的所有服务都位于同一个节点上。本例中,VIP 在哪里,其它的服务也在那个节点上运行。
- 规定了 failover 时的启动和停止操作的规则:启动时,group 中所有的 service 都是按照给定顺序被启动的;停止时,group 中所有的 service 都是按照逆给定顺序被停止的
- 启动时,前面的 service 启动失败了的话,后面的服务不会被启动。本例中,如果 p_api-ip (VIP)启动失败,后面的服务都不会被启动
1.4.3 Pacemaker 对 RA 的使用
Pacemaker 根据 CIB 中对资源的 operation 的定义来执行相应的 RA 中的命令:
(1)monitor:Pacemaker 使用 monitor 接口来检查整个集群范围内该资源的状态,来避免重复启动一个资源。同时,重启已经崩溃的资源。
(2)restart:在被 monitored 的资源不在运行时,它会被重启(stop 再 start)。需要注意的是,Pacemaker 不一定在原来的节点上重启某服务,因此,需要通过更多的限制条件(group 和 colocation),来使得某服务在规定的节点上运行。
(3)failover:当 master 节点宕机时,Pacemaker 会启动failover 将它监管的服务切换到被节点上继续运行。这种切换,也许需要启动服务,也许只需要做上下文切换即可。
1.4.4 CIB 和 Pacemaker 的行为
这篇文章 分析了用户在 CIB 中对 Pacemaker 所做的配置和 Pacemaker 的行为时间之间的关系。
CIB 针对重启服务的行为,做了两种规定:
- 1) Intervals and timeout of recovery tasks (“when”).
- 2) Grouping and colocation of recovery tasks (“where”).
各种配置项、值和结果:
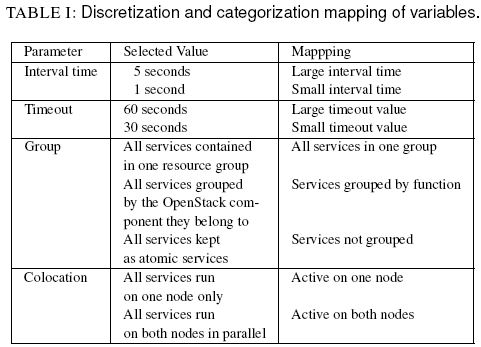
这篇文章通过多种测试,得出如下基本的结论:
- CIB 配置对资源恢复时长有直接影响
- 减少 group 有利于减少时长
- 增加 colocation 有利于减少时长
- 需要合理地进行配置来尽可能减少时长
详细的结论可以直接阅读那论文。
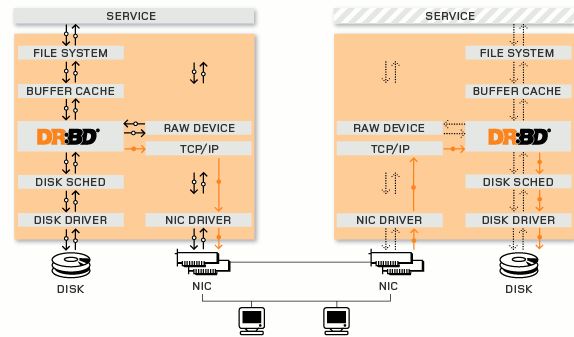
2. DRBD

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步