

2018软件工程第二次作业——个人项目
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 60 |
| · Estimate | · 估计这个任务需要多少时间 | 60 | 60 |
| Development | 开发 | 1500 | 2070 |
| · Analysis | · 需求分析 (包括学习新技术) | 360 | 780 |
| · Design Spec | · 生成设计文档 | 180 | 60 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 0 | 0 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 60 | 30 |
| · Design | · 具体设计 | 240 | 240 |
| · Coding | · 具体编码 | 360 | 420 |
| · Code Review | · 代码复审 | 120 | 60 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 180 | 480 |
| Reporting | 报告 | 420 | 240 |
| · Test Report | · 测试报告 | 180 | 120 |
| · Size Measurement | · 计算工作量 | 120 | 60 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 120 | 60 |
| 合计 | 1980 | 2370 |
这里我要备注一下,因为是个人项目,所以设计复审部分没有进行,代码规范我是混杂在具体设计里面,所以时间安排上不知道要怎么分离出来,就暂记为0。
也许我应该搞一个进度条,记录某段时间我打开电脑开始看文档、什么时候我在写代码。。。不然真的好难记录.因为我是以大致的小时来计算的,所以换算成分钟之后才会这么正好。
需求分析
实现一个命令行程序,就是叫WordCount。执行方式是这样的:
//C语言类 WordCount.exe input.txt //Java语言 java WordCount input.txt基本功能
- 统计文件的字符数:
- 只需要统计Ascii码,汉字不需考虑(我的理解就是,中文不能计入)
- 空格,水平制表符,换行符,均算字符
- 统计文件的单词总数:
- 单词:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。
- 英文字母: A-Z,a-z
- 字母数字符号:A-Z, a-z,0-9
- 分割符:空格,非字母数字符号
- 例:file123是一个单词,123file不是一个单词。file,File和FILE是同一个单词
- 统计文件的有效行数:任何包含非空白字符的行,都需要统计。
- 统计文件中各单词的出现次数,最终只输出频率最高的10个。频率相同的单词,优先输出字典序靠前的单词。
- 按照字典序输出到文件result.txt:例如,windows95,windows98和windows2000同时出现时,则先输出windows2000
- 输出的单词统一为小写格式
- 输出的格式为
characters: number words: number lines: number <word1>: number <word2>: number ...进阶要求
把基本功能里的:
- 统计字符数
- 统计单词数
- 统计最多的10个单词及其词频
这三个功能独立出来,成为一个独立的模块(class library, DLL, 或其它)。
思路
一开始思路是比较乱的,再加上很多基础都忘记了,所以我先在OneNote上整理了一下:

标蓝色的都是我当时不会的,要么要复习,要么要学习。肝了一段时间后,对于要用到的知识掌握得差不多了之后,我在课间粗略地在草稿纸上写了一些思路:

大致看一下就好,太乱了。
本来我打算将文件操作单独分离出来,但是考虑到我的各个功能是要用类来实现的,所以后来我把读写文件的功能写在每个类里面,也就是说每个类自己会做一次读写操作。
然后读字符数和读行数都比较简单,就是注意字符限定在ASCII字符以内,行数要注意包含空白字符的空行处理。
比较麻烦的是读单词数和计算频率。
读单词因为有限定要求,所以难度有所降低,我的想法是一个一个字符先读进去,遇到英文或数字就先append到string里面,否则就停止,进入判断:如果string.length()>=4,再判断前四个字符是不是英文,是的话单词数加一,不是就舍弃。
计算频率是另一个类,所以前半部分“单词的构成”和读单词一样,就是后面不再是单纯地number++。我一开始想用数组加链表的方法(就像草稿纸上画的那样),但是单词数不确定,这样的话很浪费空间,而且要查找哪个单词是否已经存在也很麻烦,毕竟是链表查找。也想过要不用结构体,但是问题还是差不多没解决啊。后来在翻C++ Primer Plus的时候看到map容器是按关键字升序排序,而且关键字不能重复,那么用单词作为关键字就能解决按字典序排列以及对应频数的目的了。但是我发现map容器不能按value排序,于是我用了另一个容器vector,把计算好频数的map转换成vector,再调用sort就可以实现按value排序,同时又已经是字典排序好了的。
设计测试文档
尽可能考虑可能出现的奇葩情况,我设计了以下test.txt的内容:
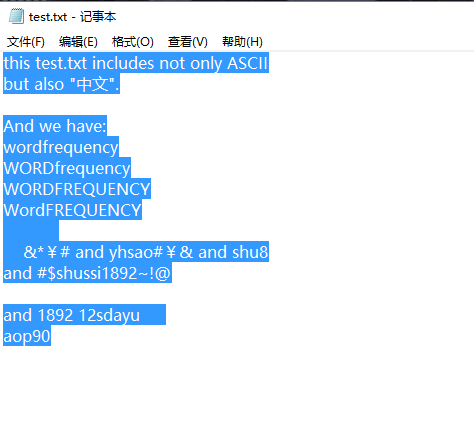
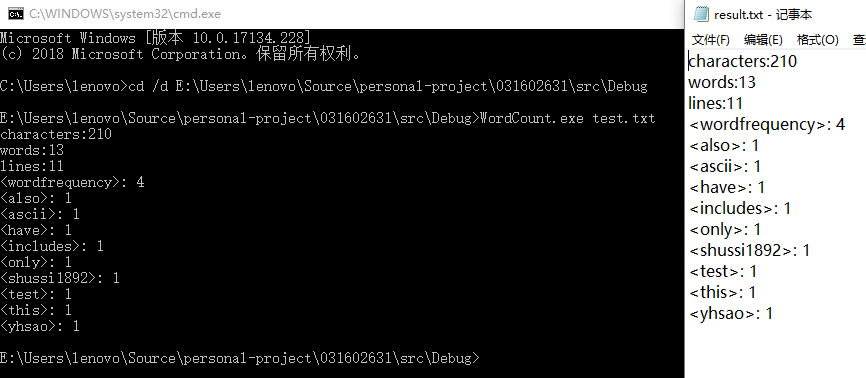
其中
character:210
line:11
word:13
wordfrequency: 4
also: 1
ascii: 1
have: 1
includes: 1
only: 1
shussi1892: 1
test: 1
this: 1
yhsao: 1
环境
- 操作系统:Windows 10
- IDE:Visual Studio 2017 Community
- 编程语言:C++
代码规范
- 书写风格规范
- 一行代码的长度最好不要超过VS2017的屏幕可显示范围,大概就是110个字符
- 缩进采用VS2017默认格式
- 凡是用到{}的地方,要使“{”、“}”独占一行
- 不允许多条语句在同一行
- 有疑问的代码、测试用的代码段、函数之间、或者什么其他的地方,用注释/**/或//做出分割线,标注清楚功能、疑问、以后想要扩展的内容等等
- 短注释可以跟在一行代码后面,长的注释比如功能说明,要在函数前独占一块
- 不同的函数之间要有空行分割,函数内部功能相差较大的也要用空行分割
- 普通变量、函数名一律小写,类首字母大写,尽量少用 _
- 代码设计规范
- 类和函数名根据各自的功能命名,要求一眼就知道是做什么的
- 要求每个类根据“进阶需求”那样尽量分离,一个类实现一个功能,且类之间尽量不要相互引用
- 类里的变量最好是private
- 传进来的参数要检查
- 文件处理要做好基本的排错处理
具体设计
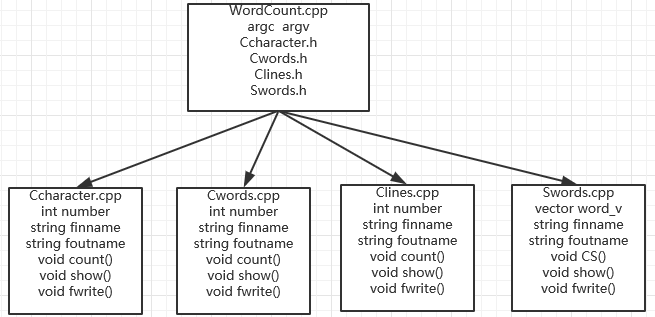
1.代码的结构划分
在需求的基础上,我划分了四个功能出来,也就是四个类:
Ccharacter.hcount charactersClines.hcount linesCwords.hcount wordsSwords.hsort words and show the top 10
其中,每个类通常都包含:
- 一个运算函数
count()(Swords.h里是CS()) - 一个显示函数
show() - 一个写入文件result.txt的写入函数
fwrite() - 构造函数
private finnameprivate foutnameprivate number(Swords.h没有)
分布图:
2.功能实现
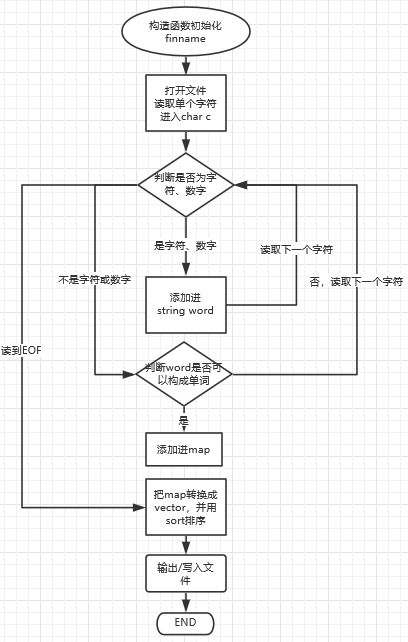
这里大致讲一下CS()的实现过程,和之前思路里提到的一样,就展示一下流程图好了:
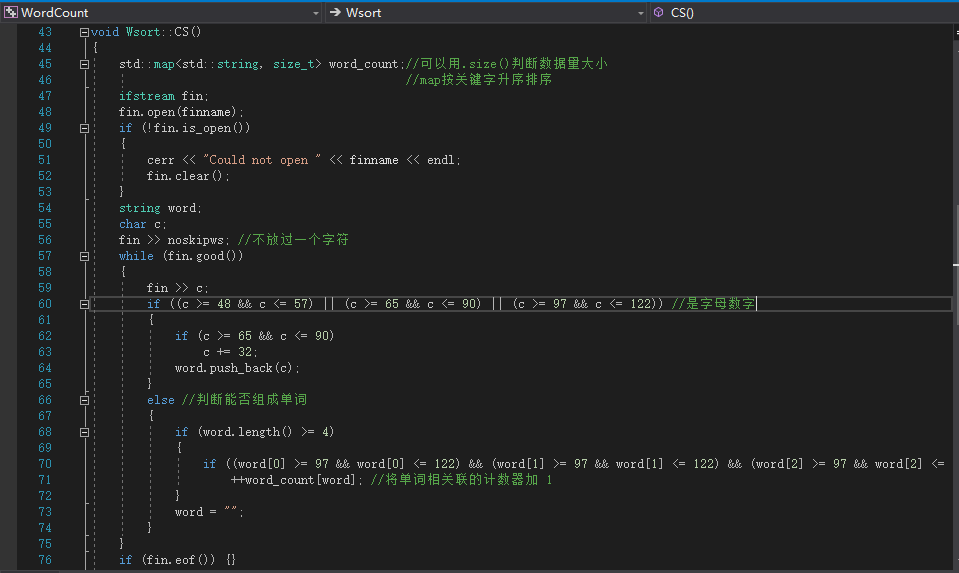
3.编码以及展示部分代码
统计词频的关键代码如下:

结果展示:
使用的是test.txt的测试样例
4.性能分析报告
测试样例我是用的test.txt,然后把main()改成非IDE的形式,循环跑了10000次,得到如下的性能分析报告。
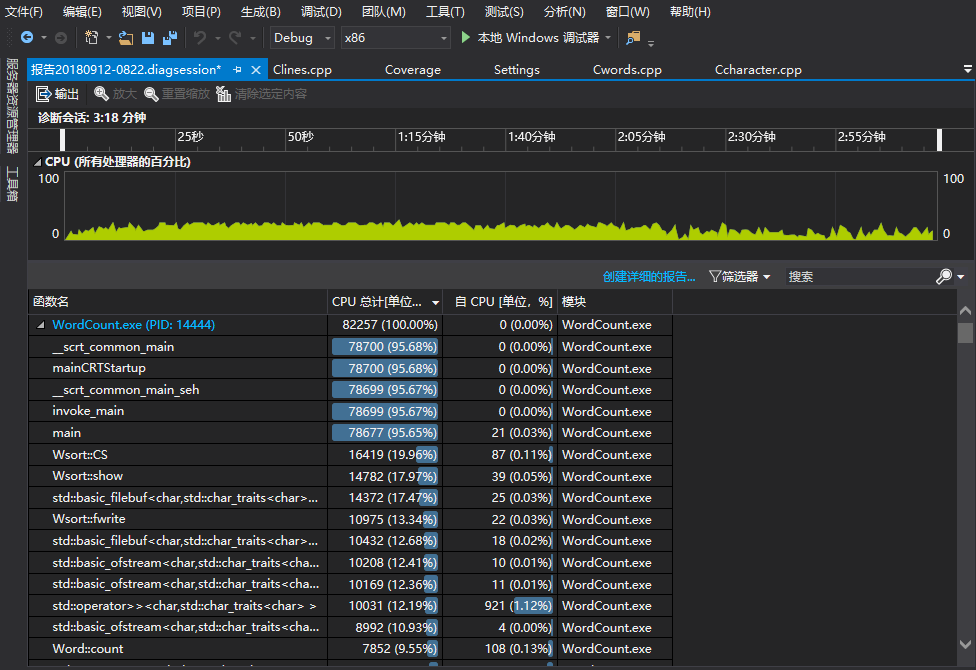
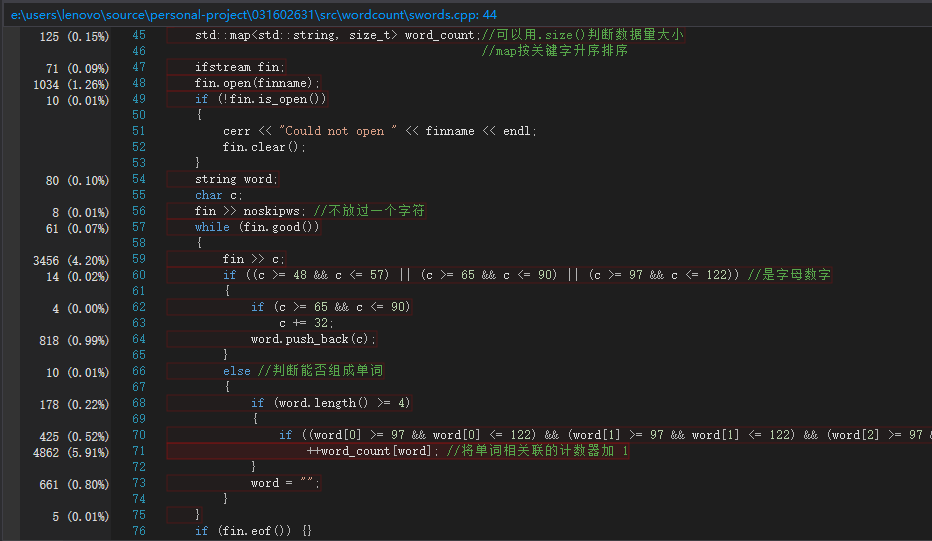

从性能分析上来看,主要的CPU消耗在了读写文件的操作上,毕竟每个类都会调用自己的读写文件,I/O操作多做了四倍。如果具体到函数的话,从第二张图看到计算词频的CS()函数也挺耗CPU的,主要是map和vector、sort的调用部分。还有第三张图显示的是唯一一个用cout输出的,结果就。。
因为考虑到我自己写的算法估计不会比map,vector那些要来得高效,所以这部分我并没有改动。然后fwrite()这部分我是做成独立的函数,可调用也可不调用,不调用的话,我也有提供获取private变量的方法,所以这部分代码我也保留了。再者就是文件读的部分,我有想过要不把文件读单独抽离出来,可是我是采用边读边处理的方法,这样的话每个类、每个函数要从文件中读出数据并处理的方式并不一样,如果我先把数据一次性读完暂存在一个缓存空间里面,那样的话和我边读取边处理相比太占内存,万一遇上数据量大的就不能用了。然后纠结了很久,结果也没改。
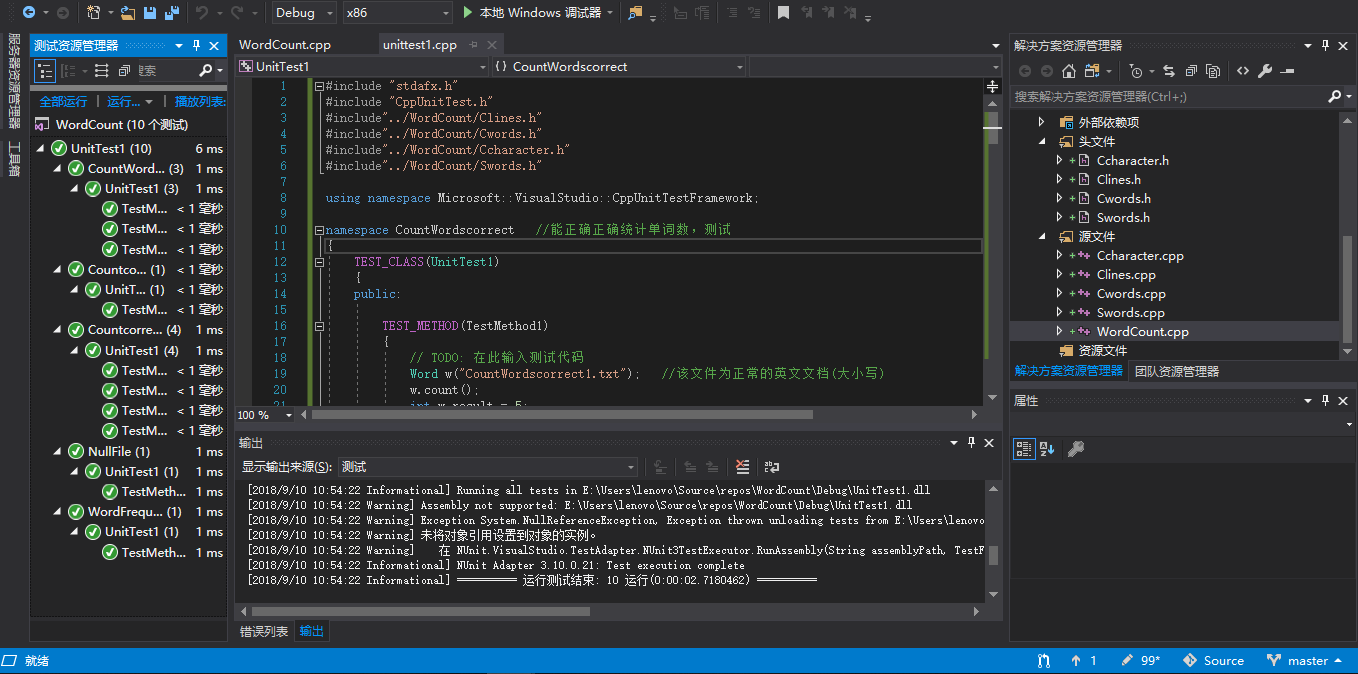
5.单元测试
我设计了十个测试用例:
| 单元测试名称 | 测试内容 | 被测试实例 |
|---|---|---|
| CountWordscorrect1 | 能正确统计单词数,该文件为正常的英文文档(大小写) | Cwords.cpp |
| CountWordscorrect2 | 能正确统计单词数,该文件为包含ASCII码的文档 | Cwords.cpp |
| CountWordscorrect3 | 能正确统计单词数,该文件既包含ASCII码,也包含中文 | Cwords.cpp |
| NullFile | 打开内容为空的文件 | 测试全部 |
| Countcorrect_c | 正确统计字符,ASCII和中文混用,中文不记录 | Ccharacter.cpp |
| Countcorrect_l1 | 正确统计行数,每一行以有效字符开头 | Clines.cpp |
| Countcorrect_l2 | 正确统计行数,存在空行和有效行 | Clines.cpp |
| Countcorrect_l3 | 正确统计行数,全部都是空行或只有空格 | Clines.cpp |
| Countcorrect_l4 | 正确统计行数,存在空行、开头为多个空格的有效行、有效行 | Clines.cpp |
| WordFrequency | 正确统计大小写英文单词的词频,仅包含同一个有效单词,但存在多个大小写混用的版本 | Swords.cpp |
单元测试结果:
6.代码覆盖率
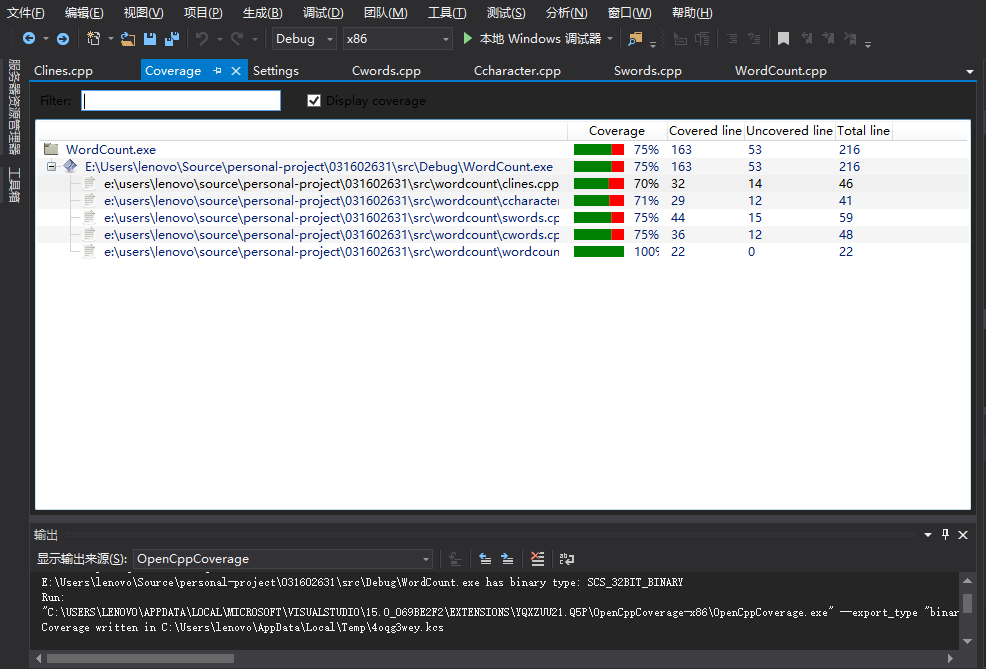

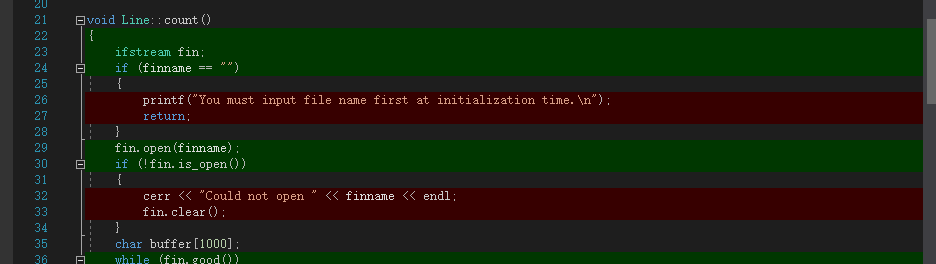
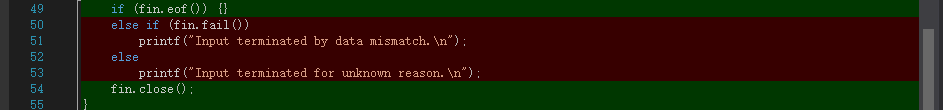

其实这个代码覆盖率我不是很看得懂。我用我设计的
test.txt测试,应该可以遍历主要的分支代码,但是就拿上面的Swords.cpp来看,有一些必要的代码却显示红色,也就是条件判断if有运行到,可是里面的内容没有运行,然后结果显示的也是我预防文件出错的错误提示,但是我用IDE是可以运行的,就不是很懂了。除此之外代码覆盖率低还因为我写了一些在单元测试的时候需要用到的,但在平时正常运行用不到的函数,比如get()用来返回private number,以及一般不会遇到的文件错误处理代码。
我现在明白为什么之前有些代码明明应该运行却没有运行了,是因为我文件名输入有错,我改正之后,代码覆盖率如上,提高到75%,剩下的未覆盖代码我看了一下,还是那些“异常文件处理机制”,因为文件正常打开,没有抛error,所以那些代码就都没有运行了。
7.DLL设计
这是进阶部分的要求,我觉得应该是要把几个功能函数挑出来单独设计成三个DLL吧,所以我就做了。得到以下.dll文件,我是按动态链接做的。

所以做完DLL之后,我的文件结构就变成这样了:
031602631
|- src
|- WordCount.sln
|- WordCount
|- WordCount.cpp
|- WordCount.vcxproj
|- WordCount_dll
|- Debug
|- WordCount.exe
|- Release
|- UnitTest1
我就列了个大概,不知道这样子还能不能符合助教的要求。。。
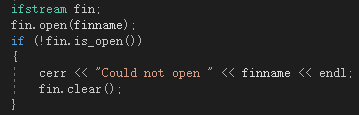
8.异常处理
我主要对文件操作进行了一些异常处理,还有就是IDE运行状态也有部分异常处理
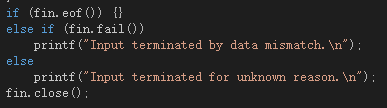

总结
刚看到题目我就觉得:完了!我没学Java,C++也忘光了!我会死的很惨!
于是乎,我先是花了一天的时间,把C++ PRIMER Plus的字符处理、类的继承和多态、文件处理、动态内存分配又回顾了一遍。然后开始写代码之前,看了一下测试要求,发现Code Quality Analysis、单元测试、白盒测试、DLL我都不会啊,于是又用了一天大致了解了一下这些都是些什么东西,才开始着手设计框架。其实基础知识掌握了之后,很快就能够把代码的大致框架搭建起来,包括具体的实现等等。但是我花在测试代码正确性上的时间还是挺多的,大体的代码我在任务发布的第三天就差不多写完了,后面两三天就一直来来回回在搞DLL和测试。起初我一直是用IDE直接黑箱测试,一次性测试所有结果的正确性,等我觉得应该没问题了的时候,我才开始研究怎么玩单元测试。结果在单元测试想测试用例的时候,又发现了一些之前没考虑到的情况,增加之后又改正了一些错误。至于白盒测试,其实我现在也还不是很懂。
关于类和函数,我后来在《构建之法》里看到,作者有建议尽量用函数,必要用类。其实我一开始看到题目要求还要分模块,第一反应就是我要写功能类。前面用着还挺顺利,换成DLL函数也挺方便的。只是到后面测代码覆盖率的时候就觉得,这么低的覆盖率,好像挺难看的。虽然覆盖率高的代码不一定好,但还是暗暗为自己感到惭愧。这个时候就会觉得或许这么简单的功能真的不需要用到类?但我还是觉得用类比较方便,很有“对象”的感觉,所以目前来说,我还是不太懂为什么非必要不要用类。
其实我是有千言万语的,但是现在突然想不起来要讲什么了

