
学习MySQL binlog格式 二:动手开干
继上一篇的准备工作后,就应该可以开始着手打开binlog文件了。
利用hexdump工具,这是一个用来查看“二进制”文件的十六进制编码工具:
# hexdump -Cv mysql.000005
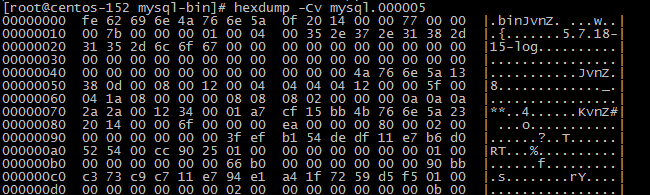
先看看右边的,.bin 5.7.18-15-log ,是不是很好玩,已经可以看到一些信息了。
我们先来分析一下这里的.bin 5.7.18-15-log是怎么来的?
1、到网上找个16进制->10进制->ascii工具:http://www.ab126.com/goju/1711.html
2、打开计算器
现在取前4个字节,fe 62 69 6e
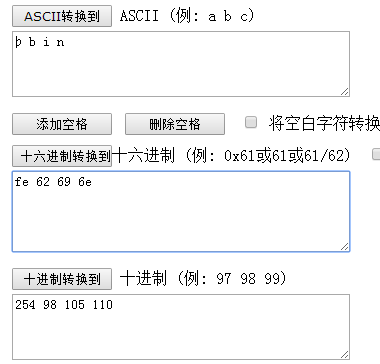
这时看到了bin字符了,既然顺移4个字节能看到bin,那么再往后移动是什么呢?这里就需要知道binlog的数据结构了,大家还记得第一篇的内容吧?不记得的话最好还是去看看
好了,现在我们往后移动19个字节,分别是4a 76 6e 5a 0f 20 14 00 00 77 00 00 00 7b 00 00 00 01 00。这里面包含的信息是1517188682(该事件时间), 15(事件类型), 5152(server_id), 119(该事件的长度), 123(下一个事件在文件的位置), 1(flags)。
怎样分析的呢?答案就是struce里面的'<IBIIIH'(不了解的读者,还是那句话先看第一篇),根据'<IBIIIH'我们吧信息改为这样5a 6e 76 4a 0f 00 00 14 20 00 00 00 77 00 00 00 7b 00 01
以下是binlog的一下常量:
BINLOG_FILE_HEADER = b'\xFE\x62\x69\x6E'
binlog_event_header_len = 19
binlog_event_fix_part = 13
binlog_quer_event_stern = 4
binlog_row_event_extra_headers = 2
read_format_desc_event_length = 56
binlog_xid_event_length = 8
table_map_event_fix_length = 8
fix_length = 8
这些是事件类型(比如上述分析的到的15,就是FORMAT_DESCRIPTION_EVENT):
UNKNOWN_EVENT= 0
START_EVENT_V3= 1
QUERY_EVENT= 2
STOP_EVENT= 3
ROTATE_EVENT= 4
INTVAR_EVENT= 5
LOAD_EVENT= 6
SLAVE_EVENT= 7
CREATE_FILE_EVENT= 8
APPEND_BLOCK_EVENT= 9
EXEC_LOAD_EVENT= 10
DELETE_FILE_EVENT= 11
NEW_LOAD_EVENT= 12
RAND_EVENT= 13
USER_VAR_EVENT= 14
FORMAT_DESCRIPTION_EVENT= 15
XID_EVENT= 16
BEGIN_LOAD_QUERY_EVENT= 17
EXECUTE_LOAD_QUERY_EVENT= 18
TABLE_MAP_EVENT = 19
PRE_GA_WRITE_ROWS_EVENT = 20
PRE_GA_UPDATE_ROWS_EVENT = 21
PRE_GA_DELETE_ROWS_EVENT = 22
WRITE_ROWS_EVENT = 23
UPDATE_ROWS_EVENT = 24
DELETE_ROWS_EVENT = 25
INCIDENT_EVENT= 26
HEARTBEAT_LOG_EVENT= 27
IGNORABLE_LOG_EVENT= 28
ROWS_QUERY_LOG_EVENT= 29
WRITE_ROWS_EVENT = 30
UPDATE_ROWS_EVENT = 31
DELETE_ROWS_EVENT = 32
GTID_LOG_EVENT= 33
ANONYMOUS_GTID_LOG_EVENT= 34
PREVIOUS_GTIDS_LOG_EVENT= 35
到这里后,我们就可以写个脚本来实践以下,通过常量的偏移位来分析binlog里面到底记录了些什么了:
reader = open(mysql_binlog,'rb') #打开binlog文件 chunk = reader.read(4) # 往后移动4个字节,4个字节数据为.bin result = struct.unpack("=4c",chunk) print(result) chunk = reader.read(19) # 往后读取19个字节,常量EVENT_HEADER_LEN result = struct.unpack('<IBIIIH', chunk) #根据IBIIIH格式来读取数据,详细请查看python struct的用法,注意在binlog里面数据是倒序存储的所以使用'<',这里可以取得日志的开始时间 #数据类型15,server_id,该event的长度119,下一个事件的开始位置123, print("head:" ,result) chunk = reader.read(56) # 往后读取56个字节,常量read_format_desc_event_length result = struct.unpack("H50sI",chunk) print("head:", result) chunk = reader.read(119-19-56) # 往后读取44个字节,该event的长度119-头文件长度-常量read_format_desc_event_length chunk = reader.read(19) # 往后读取19个字节,常量EVENT_HEADER_LEN result = struct.unpack('<IBIIIH', chunk) #通过读取头文件信息,可以获取当前事件的长度为111,下一个事件开始位置234,当前事件类型为35 print("head:", result) event_length = int(result[3]) reader.read(event_length - 19) # 读取该事件的数据信息,注意这里利用该事务的长度减去常量EVENT_HEADER_LEN获得 chunk = reader.read(19) # 往后读取19个字节,常量EVENT_HEADER_LEN result = struct.unpack('<IBIIIH', chunk) # 通过读取头文件信息,可以获取当前事件的长度为65,下一个事件开始位置299,当前事件类型为33 print("data:", result) event_length = int(result[3]) reader.read(1) uuid = reader.read(16) # 往后读取16字节,获得uuid gtid = "%s%s%s%s-%s%s-%s%s-%s%s-%s%s%s%s%s%s" % tuple("{0:02x}".format(ord(c)) for c in uuid) gno_id = struct.unpack('Q', reader.read(8)) # 往后读取8字节 print("data:%s:%d" % (gtid,gno_id[0])) reader.read(event_length - 1 - 16 - 8 - 19) chunk = reader.read(19) # 往后读取19个字节,常量EVENT_HEADER_LEN result = struct.unpack('<IBIIIH', chunk) # 通过读取头文件信息,可以获取当前事件的长度为215,下一个事件开始位置514,当前事件类型为2 print(result) chunk = reader.read(13) # 通过常量binlog_event_fix_part=13 result = struct.unpack('=IIBHH', chunk) # 获得thread_id = 4 表名长度为8个字节,保留字节为45个 print(result) reader.read(45) # 平移45个字节 chunk = reader.read(8) # 根据上面的表名长度 database_name, = struct.unpack('8s', chunk) # 读取8个字节,获得表名 print(database_name) statement_length = 215 - 13 - 19 - 45 - 8 - 4 # 获得数据段字节长度,event_length215 - binlog_event_fix_part13 - binlog_event_header_len 19 # - 保留字节45 - 表名8 - 常量binlog_quer_event_stern4 chunk = reader.read(statement_length) _a, sql_statement, = struct.unpack('1s%ds' % (statement_length - 1), chunk) print(_a, sql_statement) reader.read(4) # 平移4字节 chunk = reader.read(19) # 通过读取头文件信息,可以获取当前事件的长度为65,下一个事件开始位置579,当前事件类型为33 result = struct.unpack('<IBIIIH', chunk) print(result) event_length = int(result[3]) reader.read(1) uuid = reader.read(16) # 往后读取16字节,获得uuid gtid = "%s%s%s%s-%s%s-%s%s-%s%s-%s%s%s%s%s%s" % tuple("{0:02x}".format(ord(c)) for c in uuid) gno_id = struct.unpack('Q', reader.read(8)) # 往后读取8字节 print("data:%s:%d" % (gtid, gno_id[0])) reader.read(event_length - 1 - 16 - 8 - 19) chunk = reader.read(19) # 通过读取头文件信息,可以获取当前事件的长度为76,下一个事件开始位置655,当前事件类型为2 result = struct.unpack('<IBIIIH', chunk) print(result) chunk = reader.read(13) # 通过常量binlog_event_fix_part=13 result = struct.unpack('=IIBHH', chunk) # 获得thread_id = 4 表名长度为8个字节,保留字节为26个 print(result) reader.read(26) chunk = reader.read(8) # 根据上面的表名长度 database_name, = struct.unpack('8s', chunk) # 读取8个字节,获得表名 print(database_name) statement_length = 76 - 13 - 19 - 26 - 8 - 4 chunk = reader.read(statement_length) _a, sql_statement, = struct.unpack('1s%ds' % (statement_length - 1), chunk) print(_a, sql_statement) reader.read(4) # 平移4字节 chunk = reader.read(19) # 通过读取头文件信息,可以获取当前事件的长度为77,下一个事件开始位置732,当前事件类型为19 result = struct.unpack('<IBIIIH', chunk) print(result)
执行结果是这样的:

到这里,抛砖引玉完了,大伙应该基本就知道该怎么分析出binlog的信息了吧?


