
利用thinking sphinx实现全文检索
随便抄几段介绍一下Sphinx。
- Sphinx支持高速建立索引(可达10MB/秒,而Lucene建立索引的速度是1.8MB/秒)
- 高性能搜索(在2-4 GB的文本上搜索,平均0.1秒内获得结果)
- 高扩展性(实测最高可对100GB的文本建立索引,单一索引可包含1亿条记录)
- 支持分布式检索
- 支持基于短语和基于统计的复合结果排序机制
- 支持任意数量的文件字段(数值属性或全文检索属性)
- 支持不同的搜索模式(“完全匹配”,“短语匹配”和“任一匹配”)
- 支持作为Mysql的存储引擎
Thinking Sphinx是其Ruby接口,既然railscasts.com的Ryan都推荐,我们没有理由不去试试这个热门插件。
安装支持
git clone git://github.com/freelancing-god/thinking-sphinx.git vendor/plugins/thinking_sphinx
如果是gem安装
config.gem( 'freelancing-god-thinking-sphinx', :lib => 'thinking_sphinx', :version => '1.1.12' )
务必在你的rails项目的根目录的Rakefile文件中添加,插件方式则免去这一步!
require 'thinking_sphinx/tasks'
至于sphinx可到这里下载, http://download.csdn.net/source/1510659,密码为nasamidesu。(支持中文分词,官网的要自己打补丁才行!)
解压后,记得把Sphinx的bin目录添加到系统变量中。
定义索引
class Topic < ActiveRecord::Base
#……………………………………………………其他实现………………………………………………………………
#如果想重新建立索引,在控制台输入rake ts:in INDEX_ONLY = true
#=======================搜索部分=====================
define_index do
indexes :title,:sortable => true
indexes first_post.body,:as => :body,:sortable => true
indexes author
has :created_at,:updated_at,:forum_id,:digest
end
#……………………………………………………其他实现………………………………………………………………
end
class Post < ActiveRecord::Base
#……………………………………………………其他实现………………………………………………………………
#如果想重新建立索引,在控制台输入rake ts:in INDEX_ONLY = true
#=======================搜索部分=====================
define_index do
indexes topic(:title),:as => :title ,:sortable => true
indexes body,:sortable => true
indexes author
has :created_at,:updated_at,:forum_id
end
#……………………………………………………其他实现………………………………………………………………
end
与Ferret相比,它不能实时更新索引(亦即不能在我们创建更新删除一个模型,不能重新索引相关数据)。幸好,Delta Indexes(增量索引)的出现解决了这问题。实现增量索引有三种方式:实时索引,定时索引与延时索引。
实时索引
最常用的就是实时索引,它要求我们在被索引的模型中增加一个属性,名为delta。
ruby script/generate migration AddDeltaToTopic delta:boolean
class AddDeltaToTopic < ActiveRecord::Migration
def self.up
add_column :topics, :delta,:boolean, :default => true, :null => false
add_column :posts, :delta,:boolean, :default => true, :null => false
end
def self.down
remove_column :topics, :delta
remove_column :posts, :delta
end
end
define_index do
indexes :title,:sortable => true
indexes first_post.body,:as => :body,:sortable => true
indexes author
has :created_at,:updated_at,:forum_id,:digest
#声明使用实时索引
set_property :delta => true
end
define_index do
indexes topic(:title),:as => :title ,:sortable => true
indexes body,:sortable => true
indexes author
has :created_at,:updated_at,:forum_id
#声明使用实时索引
set_property :delta => true
end
定时索引
注:这个非我们项目的流程,作为小知识记一记就是!
set_property :delta => :datetime, :threshold => 1.hour
一小时索引一次,实际上是重建所有索引,所以注意间隔时间不要短于建立索引的时间。
默认使用updated_at,这样就不用给被索引模型添加delta属性了。
需要结合的重建索引的命令为rake thinking_sphinx:index:delta或rake ts:in:delta
延时索引
set_property :delta => :delayed
待到搜索时才重建索引。
sphinx索引速度在所有开源搜索引擎中是最快,能应对这种需求。
需要结合的重建索引的命令为rake thinking_sphinx:delayed_delta或rake ts:dd
建立索引
注:非流程的小知识
以下任一个命令都可以,下面的基本上是上面的简写。
rake thinking_sphinx:index #将生成配置文件 rake thinking_sphinx:index INDEX_ONLY=true #不生成配置文件 rake ts:index rake ts:in
重建索引
注:非流程的小知识
以下任一个命令都可以,下面的基本上是上面的简写。
rake thinking_sphinx:rebuild rake ts:rebuild
设置Thinking Sphinx配置文件
这个可有可无。虽然推崇COC,但对于某些场合中配置文件还是必不可少的。thinking_sphinx会根据我们提供的配置文件生成sphinx的配置文件,利用后者指导引擎去建立索引。在config下新建一文件sphinx.yml
一个简单的模板
development: &my_settings enable_star: 1 min_prefix_len: 0 min_infix_len: 2 min_word_len: 1 max_results: 70000 morphology: none listen: localhost:3312 exceptions: D:/Louvre/log/sphinx_exception.log chinese_dictionary: I:/sphinx/bin/xdict test: <<: *my_settings production: <<: *my_settings
生成Sphinx配置文件
以下随便选一个。
rake thinking_sphinx:configure rake ts:conf rake ts:config
随便运行上面一个,就可以看到config文件夹中多出一个文件development.sphinx.conf
修改
searchd
{
address = 127.0.0.1:3312
port = 3312
…………………………………………………………
}
为
searchd
{
listen = 127.0.0.1:3312
…………………………………………………………
}
搜索charset_type = utf-8,在其下面添加下面添加chinese_dictionary = I:/sphinx/bin/xdict,chinese_dictionary是指定分词词典的选项,包括路径和文件名。有几个charset_type = utf-8,就添加几个chinese_dictionary = I:/sphinx/bin/xdict(通常位于index XXXX_core中)
到这里我们就可以执行索引了
rake ts:in INDEX_ONLY=true
注意,一定要使用NDEX_ONLY=true
索引成功,没有报错,大抵是这个样子。
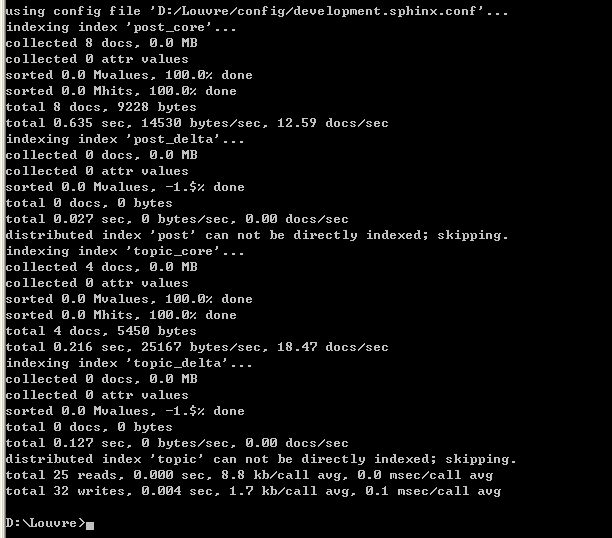
它索引的速度非常快。单一索引最大可包含1亿条记录,在1千万条记录情况下的查询速度为0.x秒(毫秒级)。Sphinx创建索引的速度为:创建100万条记录的索引只需3~4分钟,创建1000万条记录的索引可以在50分钟内完成,而只包含最新10万条记录的增量索引,重建一次只需几十秒。
建立Search模块
ruby script/generate controller search index
添加路由规则
map.online '/seach', :controller => 'seach', :action => 'index'
修改控制器。
class SearchController < ApplicationController
def index
@class = params[:class] || "topic"
@query = params[:query] || ''
unless @query.blank?
if @class == "topic"
@results = Topic.search @query
else
@results = Post.search @query
end
end
end
end
修改相应视图
thinking sphink现在还不支持摘要与高亮,不过我们还可以用一些取巧的方法来取代它们,如用truncate缩短显示的结果,利用rails自带的highlight方法实现高亮。
<% form_tag '/search', :method => :get ,:style => "margin-left:40%" do %>
<input type="radio" name="class" value = "topic" <%= @class == "topic"? 'checked="checked"':'' %>>仅主题贴
<input type="radio" name="class" value = "post" <%= @class == "post"? 'checked="checked"':'' %>>所有贴子<br>
<p>
<%= text_field_tag :query, @query %>
<%= submit_tag "搜索", :name => nil %>
</p>
<% end %>
<%- if defined? @results -%>
<style type="text/css">
.hilite{
color:#0042BD;
background:#F345CC;
}
</style>
<div id="search_result">
<%- @results.each do |result| -%>
<h3 style="text-align:center;color:red"><%= highlight h(result.title),@query, '<span class="hilite">\1</span>' %></h3>
<div><%= highlight simple_format(result.body), @query, '<span class="hilite">\1</span>'%></div>
<%- end -%>
</div>
<%- end -%>
现在可以测试一下,但务必先启动rake ts:start才能进行搜索!关闭时一定要使用rake ts:stop,sphinx是后台运行的。关闭netBeans时不会像mongrel那样一同关闭,由于忘记关闭再又再开启一个sphinx进程,会导致各种奇怪的错误。
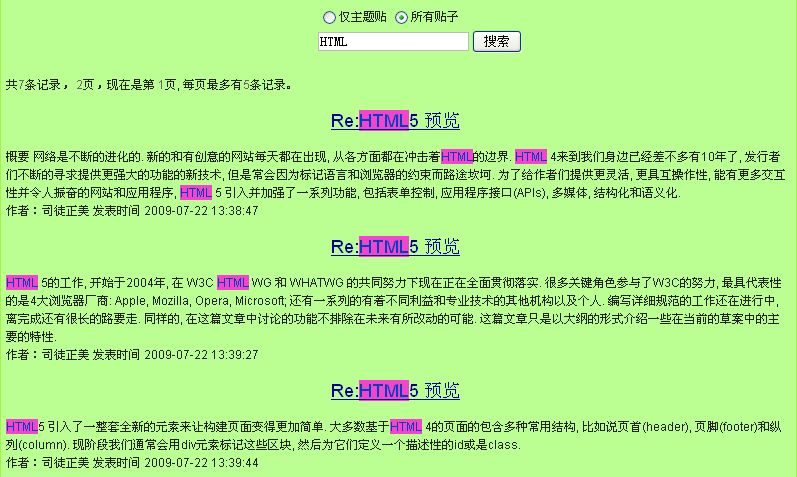
这时,我们搜索到的结果应该是这个样子。

分页
Thinking sphinx是原生支持will_paginate,默认每页为20条记录。我们可以修改一下。
@results = Topic.search params[:search], :page => (params[:page] || 1),:per_page => 5
生成的结果是个特殊的集合(!seq:ThinkingSphinx::Collection ),拥有以下属性:
- @results.total_entries:总记录数
- @results.total_pages:总页数
- @results.current_page:当前页数
- @results.per_page:每页的记录数
AJAX分页
这要用到局部模块。我们新建模板_topic.html,并把功能扩展一下
<h3 style="text-align:center;color:red"><%= highlight h(topic.title),@query, '<span class="hilite">\1</span>' %></h3> <div><%= highlight simple_format(topic.body), @query, '<span class="hilite">\1</span>'%></div> <p>作者:<%= highlight h(topic.author),@query, '<span class="hilite">\1</span>' %> 发表时间 <%= topic.created_at.to_s(:db) %></p>
局部模板_post.html.erb同上!
上面这样写显得有点乱,我们可以对它进一步封装,分割出一个视图助手(helper)。
def hilight(a,b)
#a为要高亮的字符串,b为高亮部分,默认高亮后的样式为hilite
highlight a,b, '\1'
end
修改刚才的局部模板
<h3 style="text-align:center;color:red"><%= link_to hilight(h(topic.title),@query) ,[topic.forum,topic] %></h3> <div><%= hilight truncate(topic.body,:length => 260), @query%></div> <p>作者:<%= hilight h(topic.author),@query %> 点击率 <%= topic.hits %> 回复 <%= topic.posts_count-1 %> <%= topic.digest == true ? "<span style='color:#f00'>精华贴</span>":"" %> 发表时间 <%= topic.created_at.to_s(:db) %></p>
<h3 style="text-align:center;color:red"><%= link_to hilight("Re:"+h(post.title),@query) ,[post.forum,post.topic,post] %></h3>
<div><%= hilight truncate(post.body,:length => 260), @query%></div>
<p>作者:<%= hilight h(post.author),@query %> 发表时间 <%= post.created_at.to_s(:db) %></p>
<% form_tag '/search', :method => :get ,:style => "margin-left:40%" do %>
<input type="radio" name="class" value = "topic" <%= @class == "topic"? 'checked="checked"':'' %>>仅主题贴
<input type="radio" name="class" value = "post" <%= @class == "post"? 'checked="checked"':'' %>>所有贴子<br>
<p>
<%= text_field_tag :query, @query %>
<%= submit_tag "搜索", :name => nil %>
</p>
<% end %>
<%- if defined? @results -%>
<style type="text/css">
.hilite{
color:#0042BD;
background:#F345CC;
}
</style>
<p>共<span class="quiet"><%= @results.total_entries %></span>条记录,
<span class="quiet"><%= @results.total_pages %></span>页,现在是第
<span class="quiet" id="current_page"><%= @results.current_page %></span>页,
每页最多有<span class="quiet"><%= @results.per_page %></span>条记录。
</p>
<div id="search_result">
<% if @class == "topic" %>
<%= render :partial =>"topic",:collection => @results %>
<% elsif @class == "post" %>
<%= render :partial =>"post",:collection => @results %>
<% end %>
</div>
<%= will_paginate @results ,:previous_label => '上一页 ',:next_label => '下一页' %>
<%- end -%>
修改控制器
class SearchController < ApplicationController
def index
@class = params[:class] || "topic"
@query = params[:query] || ''
unless @query.blank?
if @class == "topic"
@results = Topic.search @query,:page => (params[:page] || 1),:per_page => 5
else
@results = Post.search @query,:page => (params[:page] || 1),:per_page => 5
end
end
if request.xhr?
render :update do |page|
page.select('div.pagination').each do |element|
element.replace "#{will_paginate @results,:previous_label => '上一页 ',:next_label => '下一页',:renderer => 'RemoteLinkRenderer' }"
end
page.replace_html 'search_result',:partial => "#{@class}",:collection => @results
page.replace_html 'current_page',params[:page] || 1
end
end
end
end
在app/helpers中添加remote_link_renderer.rb
class RemoteLinkRenderer < WillPaginate::LinkRenderer
def prepare(collection, options, template)
@remote = options.delete(:remote) || {}
super
end
protected
def page_link(page, text, attributes = {})
@template.link_to_remote(text, {:url => url_for(page), :method => :get}.merge(@remote))
end
end
添加以下javascript
/*对所有模块类名为pagination的div元素中的链接添加ajax支持,实现ajax分页*/
var modules_ajax_paginate = function(){
var target = $$("div.pagination a");
if(target != null){
target.each(function(element){
$(element).observe('click',function(event){
_modules_ajax_paginate(this);
Event.stop(event);
});
});
}
}
/*上面的私有方法*/
var _modules_ajax_paginate = function(element){
var h = element.readAttribute("href");
var s= 'authenticity_token=' + window._token;
new Ajax.Request(h, {
asynchronous:true,
evalScripts:true,
method:'get',
parameters:s
});
}
Event.observe(window, 'load', function() {
modules_ajax_paginate();
})
至此,我们的项目就基本完成了,下面所有的东西都当作小知识学习一下就是!
多模型查询
ThinkingSphinx::Search.search "term", :classes => [Post, User, Photo, Event]
指定匹配模式
SPH_MATCH_ALL模式,匹配所有查询词(默认模式)。
Topic.search "Ruby Louvre",:match_mode => :all Topic.search "Louvre"
PH_MATCH_ANY模式,匹配查询词中的任意一个。
Topic.search "Ruby Louvre", :match_mode => :any
SPH_MATCH_PHRASE模式,将整个查询看作一个词组,要求按顺序完整匹配。
Topic.search "Ruby Louvre", :match_mode => :phrase
SPH_MATCH_BOOLEAN模式,将查询看作一个布尔表达式。
Topic.search "Ruby | Louvre, :match_mode => :boolean
SPH_MATCH_EXTENDED模式,将查询看作一个Sphinx内部查询语言的表达式。
User.search "@name pat | @username pat", :match_mode => :extended
加权
为了提高搜索质量,我们可以对某些模型或字段进行加权,提高它们的优先度。默认都是1
User.search "pat allan", :field_weights => { :alias => 4, :aka => 2 }
ThinkingSphinx::Search.search "pat", :index_weights => { User => 10 }
完整例子,修改我们的编辑器。
unless params[:search].blank?
@q = params[:search]
@results = Topic.search @q,
:page => (params[:page] || 1),
:per_page => 5,
:order => "@relevance DESC,updated_at DESC",
:field_weights => { :title => 20 }
end
修改视图
<% @results.each_with_weighting do |topic, weight| %>
<h3 style="text-align:center;color:red"><%= hilight h(topic.title),@q %></h3>
<div><%= hilight simple_format(topic.body), @q %></div>
<p>作者:<%= hilight h(topic.author),@q %> 发表时间 <%= topic.created_at.to_s(:db) %> 权重:<%= weight %></p>
<% end %>
Weighted MultiModel Search
ThinkingSphinx::Search.search params[:query],
:classes => [Article, Term],
:limit => 1_000_000,
:page => params[:page] || 1,
:per_page => 20,
:index_weights => {
"article_core" => 100,
"article_delta" => 100,
}
相关语法
@results.each_with_weighting do |result, weight| @results.each_with_group do |result, group| @results.each_with_group_and_count do |result, group, count| @results.each_with_count do |result, count| #Any attribute from the result set will work with each_with_blah - so, distances: @result.each_with_geodist do |result, distance|
条件搜索
这有利于缩小搜索的范围,更容易得到我们想要的结果。注意,用作条件的属性必须被索引(以indexes或has方式)
ThinkingSphinx::Search.search :with => {:tag_ids => 10}
ThinkingSphinx::Search.search :with => {:tag_ids => [10,12]}
ThinkingSphinx::Search.search :with_all => {:tag_ids => [10,12]}
User.search :conditions => {:name => "司徒正美",roles => "admin"}
Topic.search :conditions => {:forum_id => 10}
Article.search "East Timor", :conditions => {:rating => 3..5}
User.search :without => {:roles => "user"} #搜索所有高级会员,版主与超版。
User.search :without_ids => 1
通配符搜索
在配置文件sphinx.yml中声明
development: &my_settings enable_star: 1 min_prefix_len: 0 min_infix_len: 2
嘛,我原来给出的模板就有了,所以大家就不要费心了。
Location.search "*elbourn*"
Location.search "elbourn -ustrali", :star => true, :match_mode => :boolean #相当于搜索*elbourn* -*ustrali*
User.search("oo@bar.c", :star => /[\w@.]+/u)#相当于搜索*oo@bar.c*
分组
对时间进行分组。
define_index do
# 其他设置
has :created_at
end
Fruit.search "apricot", :group_function => :day, :group_by => 'created_at'
一些时间函数
# * :day - YYYYMMDD
# * :week - YYYYNNN (NNN is the first day of the week in question, counting from the start of the year )
# * :month - YYYYMM
# * :year - YYYY
有了它我们可以很轻松地统计每个版本一周内的发贴量
通过模型的某个属性进行分组
Fruit.search "apricot", :group_function => :attr, :group_by => 'size'
同一个模型使用多个索引
class User < ActiveRecord::Base #…………其他设置…………………… has_many :user_tags define_index do has user_tags, :as=>:type_ones where "tag_type=0" end define_index do has user_tags, :as=>:type_twos where "tag_type=1" end

