
数据库架构简要解析
1. 场景描述
Greenplum用了大半年了,要给部门其他同事做下分享,写了个ppt,其中看到“ Greenplum是一款典型的Shared-Nothing 分布式数据库系统。”,看到Shared-Nothing架构,以前只从字面上知道就是不共享,但是对数据库架构了解的不多,怕别人问起来就尴尬了,就补了下课,记录下吧。
2. 解决方案
数据库构架设计中主要有:Shared Everthting、Shared Disk、Shared Nothing等。
2.1 Shared Everthting
一般是单体主机,共享cpu/memory/io,单节点 的sqlsever、mysql、oracle等关系型数据库都是Shared Everthting,实例或者机器出故障了,整个服务就停用了,可用性差点。
2.2 Shared Disk
感觉这个概念就是针对oracle RAC来的,简单来说就是多个实例共享数据(磁盘),架构图:
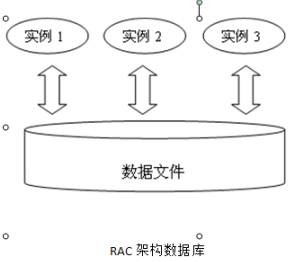
说明: 应用实例可以有多个,可以是服务器,也可以是一个服务器多个服务,简单说这种情况下,实例只要不是全部挂了,就还能访问,但是数据库磁盘挂了,整个服务就不可用了。
2.3 Shared Nothing
大数据时代的到来,一般都是这个套路了,就是各玩各的(cpu、内存、存储都不共享),最后汇总展示。
2.3.1 hadoop
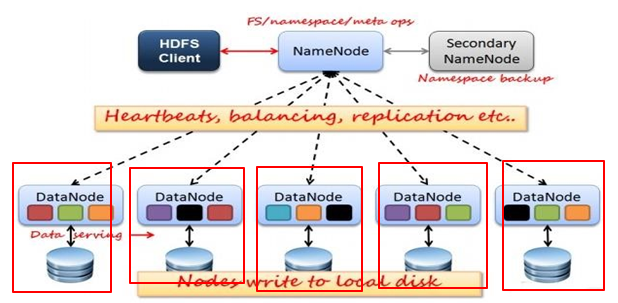
(2)说明
(a)namenode,名字节点,要管理元数据信息(Metadata),注意,只存储元数据信息。
(b) datanode,数据节点。用于存储文件块。为了防止datanode挂掉造成的数据丢失,对于文件块要有备份,一个文件块有三个副本。
hadoop默认是三个副本,这样即使其中一个datanode出故障了,也没关系,还能正常提供服务。
2.3.2 言归正传,Greenplum
(1)Greenplum架构图
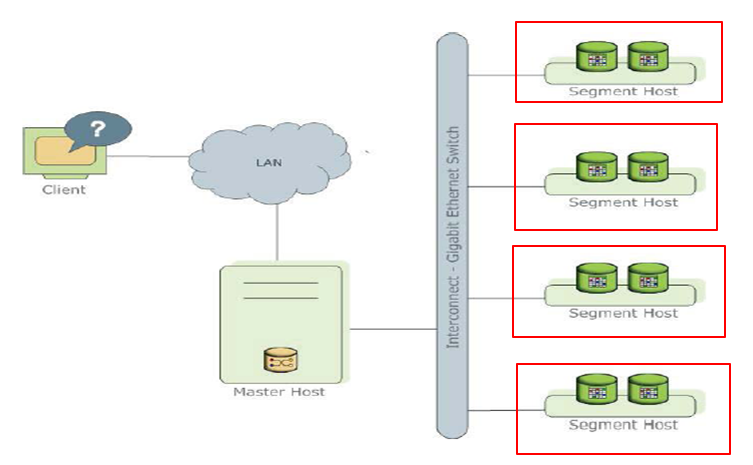
(2)说明
(a)Master主机负责:建立与客户端的连接和管理;SQL的解析并形成执行计划;执行计划向Segment 的分发收集Segment的执行结果;Master不存储业务数据,只存储数据字典。
(b)Segment主机负责:业务数据的存储和存取;用户查询SQL的执行。
示例中假如有400万数据,4个segment host各自存储100万数据,cpu、内存、数据都不共享,根据master执行计划,返回数据到master节点,由master节点汇总返回client,另外greenplum是双备份机制。
说明: 其实这些都是概念性的东西,只是方便大家快速理解而已,不用太纠结,再说了现在mysql、oracle rac等也好多都集群部署了,有点混合的意思了。
I’m 「软件老王」,如果觉得还可以的话,关注下呗,后续更新秒知!欢迎讨论区、同名公众号留言交流!


