
第二章——机器学习项目完整案例(End-to-End Machine Learning Project)
本章通过一个例子,介绍机器学习的整个流程。
2.1 使用真实数据集练手(Working with Real Data)
国外一些获取数据的网站:
- Popular open data repositories:
- Meta portals (they list open data repositories):
- Other pages listing many popular open data repositories:
国内的一些数据源:
- 深圳市:http://opendata.sz.gov.cn/
- 贵州省:http://www.gzdata.gov.cn/
- 北京市:http://www.bjdata.gov.cn/
- 上海市:http://www.datashanghai.gov.cn/
- 青岛市:http://data.qingdao.gov.cn/
- 广州市:http://www.datagz.gov.cn/
本章选择了加州房价数据集,代码可以从https://github.com/ageron/handson-ml获取。
2.2 分析整体情况(Look at the Big Picture)
我们的目的是使用加州的人口普查数据,建立模型,预测加州各区域的房价中位数。
训练数据的特征包括加州各区域的人口、收入中位数、房价中位数等。
2.2.1 问题构建(Frame the Problem,提出问题,给出框架,提出假设)
首先问清楚老板的商业目的,以及当前的解决方案(如果有的话)。比如,了解到了当前方案的错误率大概15%,我们就要奋斗目标了。
接下来就可以分析,这是一个有监督学习、无监督学习、还是增强学习?分类任务还是回归任务,或者别的什么?应该使用批量学习(batch learning)还是在线学习(online learning)?
如果数据量巨大,可以使用MapReduce技术,将数据分给多个服务器处理。也可是使用在线学习。
2.2.2 选择性能衡量指标(Select a Performance Measure)
回归问题典型的衡量指标选择均方根误差(Root Mean Square Error,RMSE),它揭示了预测值的标准偏差(standard deviation)。
\begin{align*}
RMSE(X,h) = \sqrt{\frac{1}{m}\sum_{i=1}^{m}(h(X^{(i)}) - y^{(i)})^2}
\end{align*}
有时候样本中存在很多离群点(outlier) ,我们可能就会使用绝对误差(Mean Absolute Error,MAE)。
\begin{align*}
RMSE(X,h) = \frac{1}{m}\sum_{i=1}^{m}\left | h(x^{(i)}) - y^{(i)} \right |
\end{align*}
RMSE和MAE都是向量距离的度量方式(预测值向量和目标值向量)。向量的距离,也可以为称为向量的模(norm),有以下性质:
- RMSE对应于欧氏距离,也被称作$l_2$距离,记做$\left \| \cdot \right \|_2$(或$\left \| \cdot \right \|$)。
- MAE对应于$l_1$距离,记做$\left \| \cdot \right \|_1$。
- 一般的,具有$n$的元素的向量$v$,$l_k$距离定义为$\left \| v \right \|_k = (\left | v_1 \right |^k + \left | v_2 \right |^k + \cdots + \left | v_n \right |^k)^{\frac{1}{k}}$。$l_0$仅仅给出向量的基数(比如非零元素的个数),$l_\infty$给出向量中最大元素的绝对值。
- 指数k最大,向量中最大元素的贡献就越大。这就是为什么相对于MAE,RMSE对离群点更敏感。但如果误差是指数级稀少(exponentially rare)的,例如钟形曲线(bell-shaped curve),RMSE的表现很好,也是通常的选择。
2.2.3 检查假设(Check the Assumptions)
我们最好跟同事确认一下假设。例如,我们的房价预测值是给下游系统使用的。如果下游系统要把价格转换为类别(例如高、中、低),那么我们的问题就成了分类。
2.3 获取数据(Get the Data)
下面就开始动手操作了,代码位于https://github.com/ageron/handson-ml。
2.3.1 创建工作空间(Create the Workspace)
安装Python、安装Jupyter Notebook
2.3.2 下载数据
fetch_housing_data函数负责,代码里面有。
2.3.3 浏览数据(Take a Quick Look at the Data Structure)
介绍了pandas DataFrame里面的一些函数:head()、info()、describe()、value_counts()(针对类别属性,列出各个类别,以及类别数量)。
Matplotlib里面的hist()函数绘制直方图。
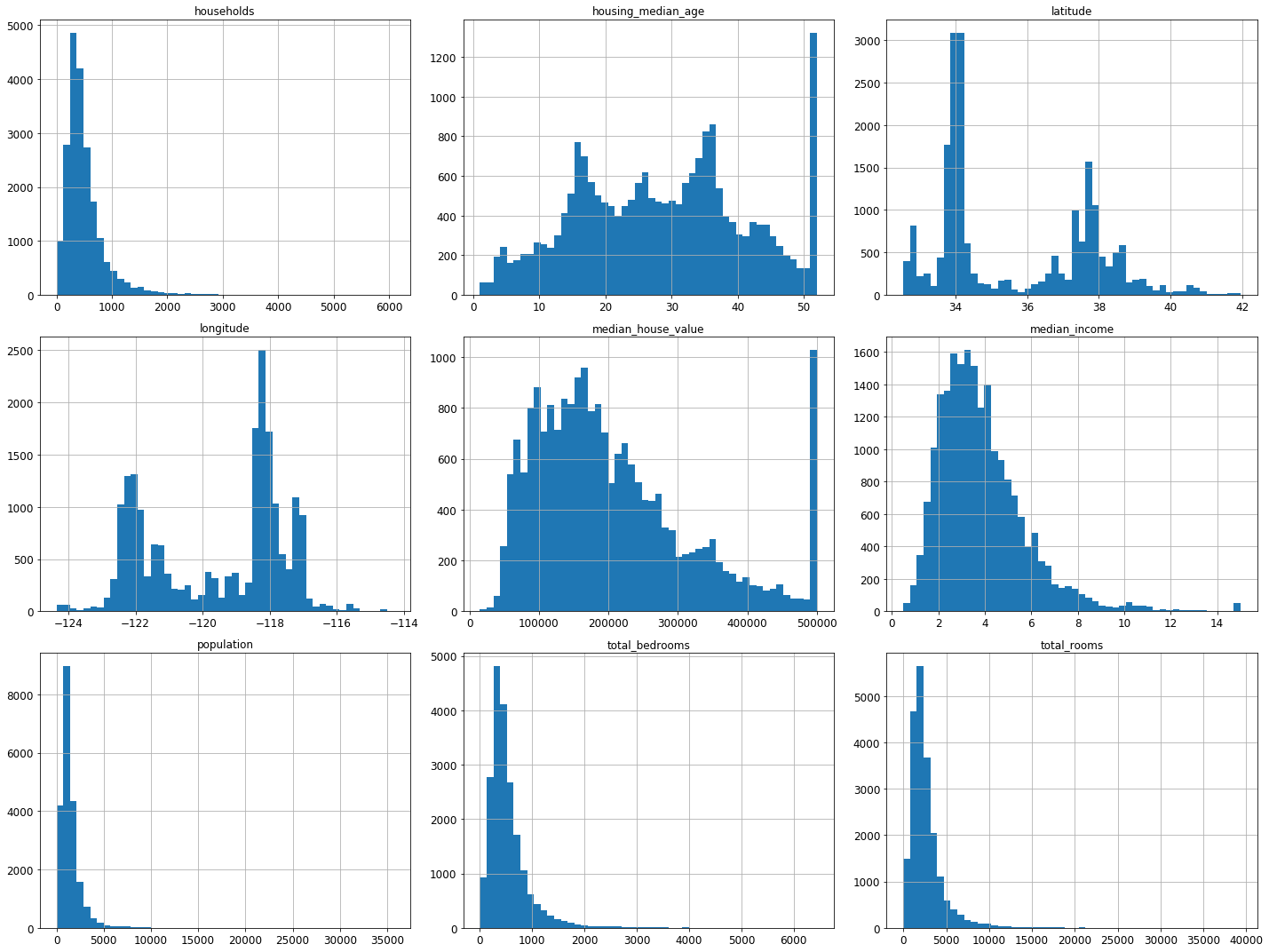
我们可以从直方图中发现以下几点:
- 收入中位数(median income)并不是以美元为单位的,而是经过了预处理。最高一致被设置为了大概15(高于某一值的数据,都被设置为了15,即使它可能是25),最低值被设置为0.5(低于某一值的都被设置为0.5)。这在机器学习中很常见,也没什么问题。
- 房龄中位数(housing median age)和房价中位数(median house value)也被处理过了。例如后者,房价高于500,000的,都被设置为500,000,即使真实房价800,000。这就是为什么它们所对应的直方图,最右列突然增高。但由于房价中位数是我们的目标属性,如果我们需要预测真实的房价,可能会高于500,000,这就存在问题了。那么有两种主要的解决方案:a、收集真实的房价。b、丢掉房价高于500,000的样本。
- 这些属性具有不同的取值范围。这将在下文探索特征缩放是进行讨论。
- 本多直方图呈现重尾分布(tail heavy):左侧距离中位数要远于右侧。这不利于一些机器学习算法进行模式识别(tail heavy)。后面将进行转换,使这些属性更符合钟形分布(bell-shaped distributions)。
2.3.4 创建测试集(Create a Test Set)
在进一步分析数据之前, 应该创建一个测试集,并将其丢在一边,不去分析。
这是为了防止过拟合,防止数据探测法偏见(data snooping bias)。
只需要随机选择20%的数据作为测试集即可。
具体怎么随机选择,作者介绍了很多实践经验比如可以用如下代码实现:
from sklearn.model_selection import train_test_split # random_state = 42 to make this notebook's output identical at every run train_set, test_set = train_test_split(housing, test_size=0.2, random_state=42)
然后作者又介绍了为什么要分层抽样(stratified sampling)。
2.4 数据的探索和可视化(Discover and Visualize the Data to Gain Insights)
这是对数据进一步的探索,写一步不能考虑测试集,只分析训练集。
2.4.1 地理数据可视化(Visualizing Geographical Data)
使用散点图,分析了地理位置、人口、人均收入跟房价的关系。
2.4.2 相关性探索(Looking for Correlations)
计算相关系数(standard correlation coefficient)矩阵,分析其它属性跟房价的相关系数。
相关系数取值-1到1,解决1时说明是正相关,接近-1时说明是负相关。接近0说明非线性相关。下图显示了一些标准数据集的相关系数:

相关系数只能度量线性相关(例如:“如果$x$增长,$y$通常增长/减少。”),这会完全地错过非线性相关(例如:“如果$x$趋近于0,$y$通常增长。”)。例如上图的第三行,这些数据相关系数为0,但它们显然不独立,存在非线性关系。
2.4.3 尝试属性组合(Experimenting with Attribute Combinations)
例如可以增加以下三个属性:
housing["rooms_per_household"] = housing["total_rooms"]/housing["households"] housing["bedrooms_per_room"] = housing["total_bedrooms"]/housing["total_rooms"] housing["population_per_household"]=housing["population"]/housing["households"]
然后可以计算它们跟房价均值的相关系数。
2.5 为机器学习算法准备数据(Prepare the Data for Machine Learning Algorithms)
2.5.1 数据清洗(Data Cleaning)
大部分机器学习算法都无法处理存在控制的属性。前面已经注意到total_bedrooms存在缺失值。修复这一问题有三个选择:
- 去掉相应的样本
- 去掉这一属性
- 使用其它值对缺失值进行填充(0、均值、中位数等等)
这可以通过DataFrame的dropna(), drop(), and fillna()方法实现:
housing.dropna(subset=["total_bedrooms"]) # option 1
housing.drop("total_bedrooms", axis=1) # option 2
median = housing["total_bedrooms"].median()
housing["total_bedrooms"].fillna(median) # option 3
作者也介绍了怎么通过Scikit-Learn的Imputer实现这一目的。
2.5.2 处理文本和类型属性(Handling Text and Categorical Attributes)
ocean_proximity是一个无法计算中位数的文本属性。而大部分机器学习算法智能处理数字,这就需要将文本转为数字。
可以使用Scikit-Learn的LabelEncoder:
>>> from sklearn.preprocessing import LabelEncoder >>> encoder = LabelEncoder() >>> housing_cat = housing["ocean_proximity"] >>> housing_cat_encoded = encoder.fit_transform(housing_cat) >>> housing_cat_encoded array([1, 1, 4, ..., 1, 0, 3])
这将['<1H OCEAN' 'INLAND' 'ISLAND' 'NEAR BAY' 'NEAR OCEAN']五个文本值编码为了0-4。但这样编码存在一个问题:ML算法会假设,靠近的两个数字比间隔远的两个数字更相似。未解决这一问题,可以采用one-hot编码。
2.5.3 自定义转换函数(Custom Transformers)
这一小节作者讲述了如何自定义Scikit-Learn的转换器(transformers)。
2.5.4 特征归一化(Feature Scaling)
最大最小归一化(min-max scaling)和标准化(Standardization)两个方法。前者比后者更容易收到离群点的影响。
2.5.5 转换流水线(Transformation Pipelines)
sklearn提供了一个类Pipeline,使得上述步骤可以进行流水操作。
2.6 选择模型并训练(Select and Train a Model)
作者选择了线性回归、决策树、随机森林三个模型。又介绍了交叉验证。
2.7 模型调整(Fine-Tune Your Model)
2.7.1 网格搜索(Grid Search)
介绍了如何使用Scikit-Learn’s GridSearchCV进行网格搜索,选取最优超参数。
另外,需要注意的是,我们可以把数据预处理阶段的一些操作视为超参数,并使用网格搜索找到最优方案。例如作者定义的CombinedAttributesAdder函数,有一个超参数add_bedrooms_per_room。相似的,使用网格搜索,可以自动寻找处理离群点、缺失值、特征选择等等问题的最优解决方案。
2.7.2 随机搜索(Randomized Search)
如果超参数的组合太少,随机搜索是网格搜索的一个不错的替代方案,也就是RandomizedSearchCV。与GridSearchCV搜索所有可能的参数组合不同,RandomizedSearchCV每次迭代的超参数都随机选取。这有两个好处:
- 如果使用随机搜索迭代1000次,这将对每个超参数探索1000个不同值(网格搜索对每个超参数只会探索很少的几个值)。
- 通过设置迭代次数,就可以方便地控制运算量。
2.7.3 模型融合(Ensemble Methods)
三个臭皮匠顶个诸葛亮,随机森林也好过单独的决策树。由于不同的模型错误类型也可能不同,所有我们可以训练多个模型,将预测结果进行融合。细节将在第7章介绍。
2.7.4 分析最优模型与其错误(Analyze the Best Models and Their Errors)
训练好模型后,可以查到每个属性的重要性,这就可以去掉一些不重要,与目标值不相关的属性。
2.7.5 在测试集上进行评估(Evaluate Your System on the Test Set)
2.8 系统上线、监控、维护(Launch, Monitor, and Maintain Your System)
上线之后,需要定期检查系统表现, 以及在崩溃是可以引发警报。不仅要检测到突发情况,还有检测到系统退化。因为随着时间的推移,系统退化是很常见侧,除非模型经常被最新的数据重新训练。
系统表现评估,可以对系统的预测随机采样并进行评估。一般这是需要人工分析的。可能是领域专家,也可能是众包平台(例如亚马逊的Mechanical Turk或者CrowdFlower)的工作者。无论如何,都要在系统中增加人工处理流水线。
同时要确保输入数据的质量。最好在数据输入时,就监控到异常数据。在线学习上这一点尤其重要。
最后,应该经常使用最新的数据训练模型,这一操作自动化程度越高越好。


