
ansj原子切分和全切分
ansj第一步会进行原子切分和全切分,并且是在同时进行的。
所谓原子,是指短句中不可分割的最小语素单位。例如,一个汉字就是一个原子。
全切分,就是把一句话中的所有词都找出来,只要是字典中有的就找出来。例如,“提高中国人生活水平”包含的词有:提高、高中、中国、国人、人生、生活、活水、水平。
接着以“提高中国人生活水平”为例,调用ansj标准分词:
String str = "提高中国人生活水平" ; Result result = ToAnalysis.parse(str); System.out.println(result.getTerms());
Analysis类的analysisStr(String temp)会对几句话进行分词。先不考虑用户自定义词典,直接看这两几代码:
if (startOffe < gp.chars.length ) {
analysis(gp, startOffe, gp.chars.length);
}
经过这里的analysis处理后,就完成了原子切分和全切分,如下图所示:
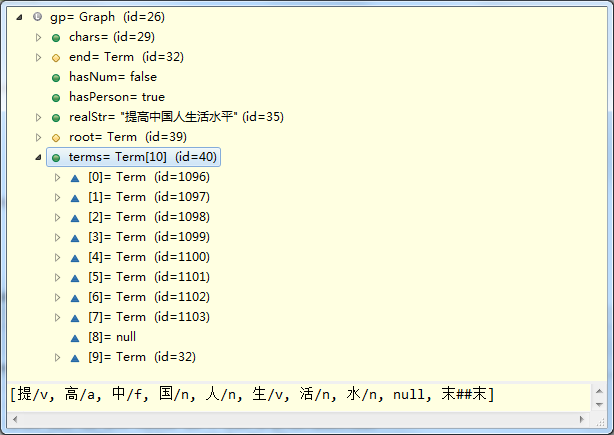
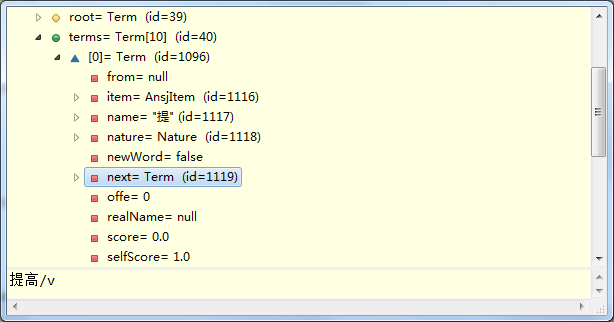
其中,terms[0]是“提”,terms[0].next是“提高”。由于“提高中”不再是个词,所以terms[0].next.next是null。
类似的,terms[1]是“高”,terms[1].next是“高中”,terms[1].next.next是null。
至于terms[9]为什么是null,这是因为“水平”是个词,但可以继续,比如“水平面”、“水平线”;而且,“平”也可以继续,比如“评价”、“平凡”。如果把例句换成“提高中国人民生活水平啊”,就不会出现null。这里先不做深入讨论。
看着一行行代码,挺多挺复杂的。真正debug一遍,发现很多代码都执行不到。看来有大量的代码,是用来处理少数特殊情况的。
涉及到的几个类及基本介绍(只看与本节内容相关的属性和方法,不然太多了):
1、Analysis
基本分词+人名识别的一个抽象类。
(1)、analysis(Graph gp, int startOffe, int endOffe)
该方法用于对一句话进行分词。
对于switch语句switch (status(chars[i])),
case 4:英文字母
case 5:阿拉伯数字或者小数点
以上两种情况,处理逻辑都比较简单,重头戏是default。
在default中,start是本轮分词的起始位置,end是本轮分词的终止位置。start和end之间只能是汉子或者标点符号。先下面这几行核心代码:
gwi.setChars(chars, start, end);
while ((str = gwi.allWords()) != null) {
Term term = new Term(str, gwi.offe, gwi.getItem());
gp.addTerm(term);
}
这几行代码就实现了将一句汉语,一个一个地分词。每分出一个词,就实例化一个Term,并加入到图(也就是变量gp)中。实例化Term的参数,str是该词的汉字表示;gwi.offe是该词在句子中起始位置的偏移量(这个参数很重要,保证了新的Term可以被插入正确的位置。);gwi.getItem()是该词在字典中的一些信息。
ansj的早期版本,只有上面这几行代码。目前的版本(5.1.2)多了下面这几行代码:
int len = term.getOffe() - max;
if (len > 0) {
for (; max < term.getOffe();) {
gp.addTerm(new Term(String.valueOf(chars[max]), max, TermNatures.NULL));
max++;
}
}
这是为了强行将不能为词的单字,插入到terms。
我们可以把上面几行代码注释,然后以“深圳市碧荔花园”为例进行切分,analysis处理后结果如下:
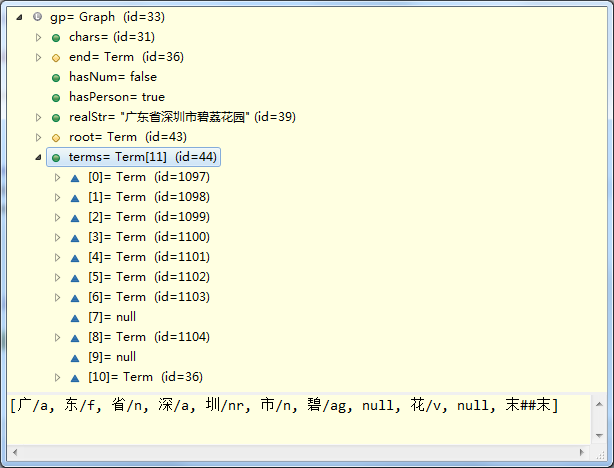
注意上图中,terms[7]是null。正常情况下,terms[7]应该是荔。荔在核心字典中的信息如下:
33620 荔 122986 -1 1 null
state是1,也就是说,“荔”不能单字为词(比如可以组成“荔枝”这个词)。但是“碧荔花园”是个小区名,“荔”不能为词,“荔花”根本就不是个词。这会导致while ((str = gwi.allWords()) != null)这里获取分出的词时,直接跳过“荔”。
上面列出的那几行代码,就是为了解决这种歌特殊情况,解决terms[7]是null的问题。
而在后面这段代码:
int len = end - max;
if (len > 0) {
for (; max < end;) {
gp.addTerm(new Term(String.valueOf(chars[max]), max, TermNatures.NULL));
max++;
}
}
解决的是“荔”这种不能为词的单字,位于句尾的情况。例如“深圳市碧荔花园荔荔荔荔荔”这句话。
这印证了我上面说过的那句话吧,有大量的代码,是用来处理少数特殊情况的。
2、GetWordsImpl
该类用于从核心字典(core.dic)中获取词语。
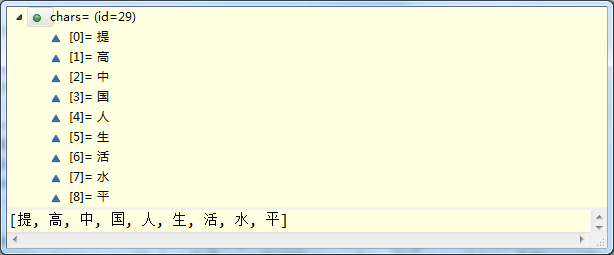
(1)、chars
该属性是一个char型数组,存储了待分词的句子,如下所示:
(2)、offe
该属性表示当前词起始位置的偏移量,是public类型的,可用于外部访问。
例如“深圳市人民政府。”这句话,“深”、“深圳”、“深圳市”三个词的offe都是0。
与offe对于的,还有可以private类型的start,也是当前词起始位置的偏移量。当一个词语结束时,start会比offe多1。
(3)、getStatement()
实现了对双数组前缀树的查询。查询某字或词在核心字典(core.dic)中的状态。
0代表这个字不在词典中。
1代表这还不是个词,需要继续。例如:102029 如日中 79205 140442 1 null
2表示这是个词,但是还可以继续。例如:96274 囫囵 74746 22251 2 {d=0}
3表示这已经是个词了,后面不能继续了。例如:102819 姗姗来迟 65536 102815 3 {i=2}
其中,标点符号的状态也是3。
(4)、allWords()
根据待分词的句子(也就是上面提到的chars属性),一个一个地返回分出的词语。
for (; i < charsLength; i++)这个for循环的i是这个类的属性,并不是一个临时变量,从而实现一个一个地返回分出的词语。
注意这个switch语句:switch (getStatement())
case 0:表示字典中没有这个词。这有两种情况:
1、这是个单字,直接返回这个单子即可,从下一个位置为起点继续分词。
2、这不是个单子,例如“人生活”这个词,在字典中是没有的。这时什么也不返回,从下一个位置为起点去分词。
至于遇到“如日中”这种词,getStatement()返回的是1,switch语句不对这种情况做任何处理,需要接着向后查找。
3、Graph
该类实现了一个图(大学时没好好学图论,没想到应用在这里的)。后面学习最短路径的构建过程时,再来详细讨论这里吧。


