


注意力机制(Attention Mechanism)在自然语言处理中的应用
注意力机制(Attention Mechanism)在自然语言处理中的应用
近年来,深度学习的研究越来越深入,在各个领域也都获得了不少突破性的进展。基于注意力(attention)机制的神经网络成为了最近神经网络研究的一个热点,本人最近也学习了一些基于attention机制的神经网络在自然语言处理(NLP)领域的论文,现在来对attention在NLP中的应用进行一个总结,和大家一起分享。
1 Attention研究进展
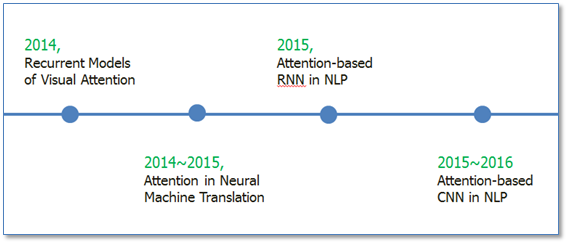
Attention机制最早是在视觉图像领域提出来的,应该是在九几年思想就提出来了,但是真正火起来应该算是google mind团队的这篇论文《Recurrent Models of Visual Attention》[14],他们在RNN模型上使用了attention机制来进行图像分类。随后,Bahdanau等人在论文《Neural Machine Translation by Jointly Learning to Align and Translate》 [1]中,使用类似attention的机制在机器翻译任务上将翻译和对齐同时进行,他们的工作算是是第一个提出attention机制应用到NLP领域中。接着类似的基于attention机制的RNN模型扩展开始应用到各种NLP任务中。最近,如何在CNN中使用attention机制也成为了大家的研究热点。下图表示了attention研究进展的大概趋势。
2 Recurrent Models of Visual Attention
在介绍NLP中的Attention之前,我想大致说一下图像中使用attention的思想。就具代表性的这篇论文《Recurrent Models of Visual Attention》 [14],他们研究的动机其实也是受到人类注意力机制的启发。人们在进行观察图像的时候,其实并不是一次就把整幅图像的每个位置像素都看过,大多是根据需求将注意力集中到图像的特定部分。而且人类会根据之前观察的图像学习到未来要观察图像注意力应该集中的位置。下图是这篇论文的核心模型示意图。

该模型是在传统的RNN上加入了attention机制(即红圈圈出来的部分),通过attention去学习一幅图像要处理的部分,每次当前状态,都会根据前一个状态学习得到的要关注的位置l和当前输入的图像,去处理注意力部分像素,而不是图像的全部像素。这样的好处就是更少的像素需要处理,减少了任务的复杂度。可以看到图像中应用attention和人类的注意力机制是很类似的,接下来我们看看在NLP中使用的attention。
3 Attention-based RNN in NLP
3.1 Neural Machine Translation by Jointly Learning to Align and Translate [1]
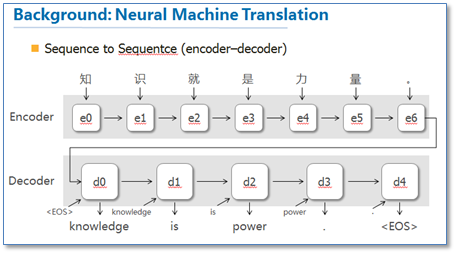
这篇论文算是在NLP中第一个使用attention机制的工作。他们把attention机制用到了神经网络机器翻译(NMT)上,NMT其实就是一个典型的sequence to sequence模型,也就是一个encoder to decoder模型,传统的NMT使用两个RNN,一个RNN对源语言进行编码,将源语言编码到一个固定维度的中间向量,然后在使用一个RNN进行解码翻译到目标语言,传统的模型如下图:
这篇论文提出了基于attention机制的NMT,模型大致如下图:
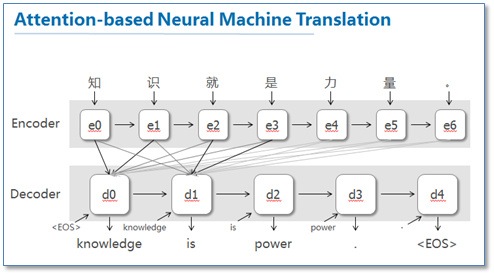
图中我并没有把解码器中的所有连线画玩,只画了前两个词,后面的词其实都一样。可以看到基于attention的NMT在传统的基础上,它把源语言端的每个词学到的表达(传统的只有最后一个词后学到的表达)和当前要预测翻译的词联系了起来,这样的联系就是通过他们设计的attention进行的,在模型训练好后,根据attention矩阵,我们就可以得到源语言和目标语言的对齐矩阵了。具体论文的attention设计部分如下:
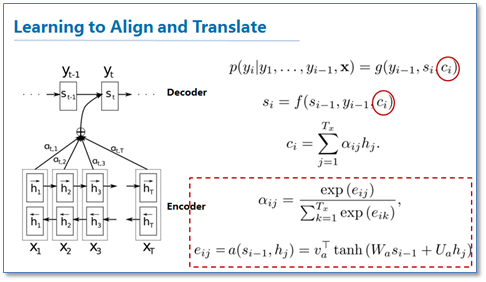
可以看到他们是使用一个感知机公式来将目标语言和源语言的每个词联系了起来,然后通过soft函数将其归一化得到一个概率分布,就是attention矩阵。
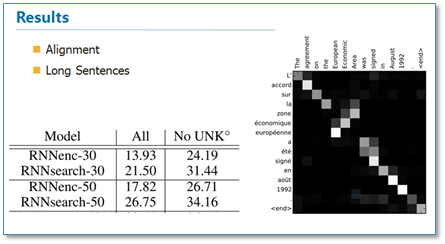
从结果来看相比传统的NMT(RNNsearch是attention NMT,RNNenc是传统NMT)效果提升了不少,最大的特点还在于它可以可视化对齐,并且在长句的处理上更有优势。
3.2 Effective Approaches to Attention-based Neural Machine Translation [2]
这篇论文是继上一篇论文后,一篇很具代表性的论文,他们的工作告诉了大家attention在RNN中可以如何进行扩展,这篇论文对后续各种基于attention的模型在NLP应用起到了很大的促进作用。在论文中他们提出了两种attention机制,一种是全局(global)机制,一种是局部(local)机制。
首先我们来看看global机制的attention,其实这和上一篇论文提出的attention的思路是一样的,它都是对源语言对所有词进行处理,不同的是在计算attention矩阵值的时候,他提出了几种简单的扩展版本。
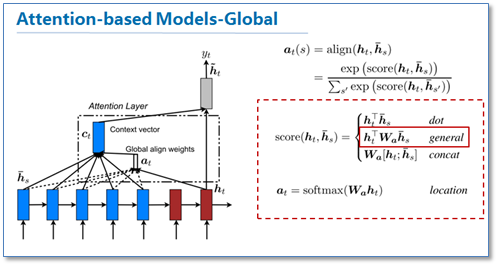

在他们最后的实验中general的计算方法效果是最好的。
我们再来看一下他们提出的local版本。主要思路是为了减少attention计算时的耗费,作者在计算attention时并不是去考虑源语言端的所有词,而是根据一个预测函数,先预测当前解码时要对齐的源语言端的位置Pt,然后通过上下文窗口,仅考虑窗口内的词。

里面给出了两种预测方法,local-m和local-p,再计算最后的attention矩阵时,在原来的基础上去乘了一个pt位置相关的高斯分布。作者的实验结果是局部的比全局的attention效果好。
这篇论文最大的贡献我觉得是首先告诉了我们可以如何扩展attention的计算方式,还有就是局部的attention方法。
4 Attention-based CNN in NLP
随后基于Attention的RNN模型开始在NLP中广泛应用,不仅仅是序列到序列模型,各种分类问题都可以使用这样的模型。那么在深度学习中与RNN同样流行的卷积神经网络CNN是否也可以使用attention机制呢?《ABCNN: Attention-Based Convolutional Neural Network for Modeling Sentence Pairs》 [13]这篇论文就提出了3中在CNN中使用attention的方法,是attention在CNN中较早的探索性工作。
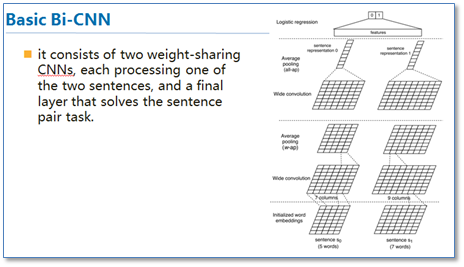
传统的CNN在构建句对模型时如上图,通过每个单通道处理一个句子,然后学习句子表达,最后一起输入到分类器中。这样的模型在输入分类器前句对间是没有相互联系的,作者们就想通过设计attention机制将不同cnn通道的句对联系起来。
第一种方法ABCNN0-1是在卷积前进行attention,通过attention矩阵计算出相应句对的attention feature map,然后连同原来的feature map一起输入到卷积层。具体的计算方法如下。

第二种方法ABCNN-2是在池化时进行attention,通过attention对卷积后的表达重新加权,然后再进行池化,原理如下图。
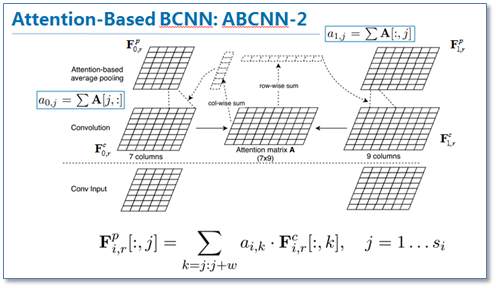
第三种就是把前两种方法一起用到CNN中,如下图

这篇论文提供了我们在CNN中使用attention的思路。现在也有不少使用基于attention的CNN工作,并取得了不错的效果。
5 总结
最后进行一下总结。Attention在NLP中其实我觉得可以看成是一种自动加权,它可以把两个你想要联系起来的不同模块,通过加权的形式进行联系。目前主流的计算公式有以下几种:

通过设计一个函数将目标模块mt和源模块ms联系起来,然后通过一个soft函数将其归一化得到概率分布。
目前Attention在NLP中已经有广泛的应用。它有一个很大的优点就是可以可视化attention矩阵来告诉大家神经网络在进行任务时关注了哪些部分。
不过在NLP中的attention机制和人类的attention机制还是有所区别,它基本还是需要计算所有要处理的对象,并额外用一个矩阵去存储其权重,其实增加了开销。而不是像人类一样可以忽略不想关注的部分,只去处理关注的部分。
参考文献
[1] Bahdanau, D., Cho, K. & Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. Iclr 2015 1–15 (2014).
[2] Luong, M. & Manning, C. D. Effective Approaches to Attention-based Neural Machine Translation. 1412–1421 (2015).
[3] Rush, A. M. & Weston, J. A Neural Attention Model for Abstractive Sentence Summarization. EMNLP (2015).
[4] Allamanis, M., Peng, H. & Sutton, C. A Convolutional Attention Network for Extreme Summarization of Source Code. Arxiv (2016).
[5] Hermann, K. M. et al. Teaching Machines to Read and Comprehend. arXiv 1–13 (2015).
[6] Yin, W., Ebert, S. & Schütze, H. Attention-Based Convolutional Neural Network for Machine Comprehension. 7 (2016).
[7] Kadlec, R., Schmid, M., Bajgar, O. & Kleindienst, J. Text Understanding with the Attention Sum Reader Network. arXiv:1603.01547v1 [cs.CL] (2016).
[8] Dhingra, B., Liu, H., Cohen, W. W. & Salakhutdinov, R. Gated-Attention Readers for Text Comprehension. (2016).
[9] Vinyals, O. et al. Grammar as a Foreign Language. arXiv 1–10 (2015).
[10] Wang, L., Cao, Z., De Melo, G. & Liu, Z. Relation Classification via Multi-Level Attention CNNs. Acl 1298–1307 (2016).
[11] Zhou, P. et al. Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification. Proc. 54th Annu. Meet. Assoc. Comput. Linguist. (Volume 2 Short Pap. 207–212 (2016).
[12] Yang, Z. et al. Hierarchical Attention Networks for Document Classification. Naacl (2016).
[13] Yin W, Schütze H, Xiang B, et al. Abcnn: Attention-based convolutional neural network for modeling sentence pairs. arXiv preprint arXiv:1512.05193, 2015.
[14] Mnih V, Heess N, Graves A. Recurrent models of visual attention[C]//Advances in Neural Information Processing Systems. 2014: 2204-2212.
