


谈谈评价指标中的宏平均和微平均
谈谈评价指标中的宏平均和微平均
今天在阅读周志华老师的《机器学习》一书时,看到性能度量这一小节,里面讲到了宏平均和微平均的计算方法,这也是我一直没有很清晰的一个概念,于是在看了之后又查阅了一些资料,但是还是存在一些问题,想和大家分享一下。
(1)召回率、准确率、F值
对于二分类问题,可将样例根据其真实类别和分类器预测类别划分为:
-
真正例(True Positive,TP):真实类别为正例,预测类别为正例。
-
假正例(False Positive,FP):真实类别为负例,预测类别为正例。
-
假负例(False Negative,FN):真实类别为正例,预测类别为负例。
-
真负例(True Negative,TN):真实类别为负例,预测类别为负例。
然后可以构建混淆矩阵(Confusion Matrix)如下表所示。
|
真实类别 |
预测类别 |
|
|
正例 |
负例 |
|
|
正例 |
TP |
FN |
|
负例 |
FP |
TN |
准确率,又称查准率(Precision,P):
(1) 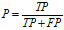
召回率,又称查全率(Recall,R):
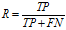 (2)
(2)
F1值:
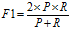 (3)
(3)
F1的一般形式 :
:
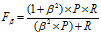 (4)
(4)
如果只有一个二分类混淆矩阵,那么用以上的指标就可以进行评价,没有什么争议,但是当我们在n个二分类混淆矩阵上要综合考察评价指标的时候就会用到宏平均和微平均。
(2)宏平均(Macro-averaging)和微平均(Micro-averaging)
宏平均(Macro-averaging),是先对每一个类统计指标值,然后在对所有类求算术平均值。
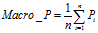 (5)
(5)
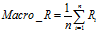 (6)
(6)
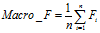 (7)
(7)
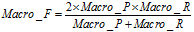 (8)
(8)
微平均(Micro-averaging),是对数据集中的每一个实例不分类别进行统计建立全局混淆矩阵,然后计算相应指标。
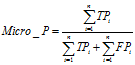 (9)
(9)
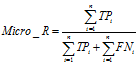 (10)
(10)

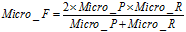 (11)
(11)
从上面的公式我们可以看到微平均并没有什么疑问,但是在计算宏平均F值时我给出了两个公式分别为公式(7)和(8)。这两个公式就是我疑惑的地方,因为我在不同的论文中看到了不同的宏平均F值的计算方法,例如在参考资料的[3][4]。于是我试图查阅宏平均和微平均提出的初始论文。但是可能由于时间比较久远还是某些原因,我并没有找到最早提出的论文,而大多数论文使用它们的时候引用比较多的是(Yang 1999)的这篇论文,论文中也未明确给出宏平均F值的计算公式,但是根据其描述:
"For evaluating performance average across categories, there are two conventional methods, namely macro-averaging and micro-averaging. Macro-averaged performance scores are computed by first computing the scores for the per-category contingency tables and then averaging these per-category scores to compute the global means. Micro-averaged performance scores are computed by first creating a global contingency table whose cell values are the sums of the corresponding cells in the per-category contingency tables, and then use this global contingency table to compute the micro-averaged performance scores"
可以看到论文里的宏平均F值应该按照公式(7)计算。但是在不少论文中我也看到了公式(8)的计算方法,所以在这可能并没有一个定论,我也比较困惑。
在参加评测中,评价指标计算都是由主办方制定并进行计算,一般会有明确的计算公式,我在这里想说的是在不少论文中使用宏平均F值时并未给出明确的计算公式,可能会存在两种不同的算法,在论文进行结果比较时,可能会有所差异。
参考资料:
1. 周志华. 机器学习.清华大学出版社
2. Yang Y. An evaluation of statistical approaches to text categorization[J]. Information retrieval, 1999, 1(1-2): 69-90.
3. 杨杰明. 文本分类中文本表示模型和特征选择算法研究. 吉林大学博士论文.
4. 廖一星. 文本分类及其特征降维研究. 浙江大学博士论文.

