
各种ORM框架对比(理论篇,欢迎来观摩,并且纠正部分错误,防止误区)
各种ORM框架对比
目前框架有以下
PetaPoco
轻量级,以前单文件,目前有维护形成项目级别,适合多个数据库,开发入手比较快,二次开发扩展简单,模型Emit映射,数据交互需要Code,并且需要编写脚本,接口上有自动翻页,支持多对象查询返回
使用示例:
//保存对象 db.Save(article); db.Save(new Article { Title = "Super easy to use PetaPoco" }); db.Save("Articles", "Id", { Title = "Super easy to use PetaPoco", Id = Guid.New() }); //获取一个对象 var article = db.Single<Article>(123); var article = db.Single<Article>("WHERE ArticleKey = @0", "ART-123"); //删除一个对象 db.Delete(article); db.Delete<Article>(123); db.Delete("Articles", "Id", 123); db.Delete("Articles", "ArticleKey", "ART-123");
Dapper.NET
轻量级,单文件,支持多数据库,模型Emit反射,数据交互需要Code,开发入手也比较快,二次开发扩展简单,支持多对象查询返回,优势在于写入数据比PetaPoco更加灵活,但编码性工作要求会更多
使用示例:
注意:所有扩展方法假定连接已打开,如果连接关闭,它们将失败
//IDbConnection扩展查询 public static IEnumerable < T > Query < T >(this IDbConnection conn,string sql,object param = null,SqlTransaction transaction = null,bool buffered = true)
- 单个查询:
public class Dog { public int? Age { get; set; } public Guid Id { get; set; } public string Name { get; set; } public float? Weight { get; set; } public int IgnoredProperty { get { return 1; } } } //简单查询 var guid = Guid.NewGuid(); var dog = connection.Query<Dog>("select Age = @Age, Id = @Id", new { Age = (int?)null, Id = guid }); //验证统计数量 dog.Count() .IsEqualTo(1); //验证属性是否为null dog.First().Age .IsNull(); //验证属性是否匹配 dog.First().Id .IsEqualTo(guid);
- 多个查询,并且返回一个动态列表:
//查询两行数据
var rows = connection.Query("select 1 A, 2 B union all select 3, 4");
//行一数据 ((int)rows[0].A) .IsEqualTo(1); ((int)rows[0].B) .IsEqualTo(2); //行二数据 ((int)rows[1].A) .IsEqualTo(3); ((int)rows[1].B) .IsEqualTo(4);
- IDbConnection扩展执行
public static int Execute(this IDbConnection cnn, string sql, object param = null, SqlTransaction transaction = null)
- 执行一个插入操作
connection.Execute(@" set nocount on create table #t(i int) set nocount off insert #t select @a a union all select @b set nocount on drop table #t", new {a=1, b=2 }) .IsEqualTo(2);
- 同一张表插入多个数据
注意:如果是大批量插入不建议这么使用,请用ADO.NET自带的BatchInsert
connection.Execute(@"insert MyTable(colA, colB) values (@a, @b)", new[] { new { a=1, b=1 }, new { a=2, b=2 }, new { a=3, b=3 } } ).IsEqualTo(3);
Massive
非单文件,但也是轻量级,项目在持续维护,支持多数据库,和dapper和PetaPoco运用有点截然不同;它是用类对象继承DynamicModel来模拟实体对象的查询和写入,似乎没有看到多对象多表联合查询和返回,局限性还是比较小
代码示例
public class Products:DynamicModel { public Products():base("northwind", "products","productid") {} } var table = new Products(); var products = table.All(); //获取查询字段和搜索条件 var productsFour = table.All(columns: "ProductName as Name", where: "WHERE categoryID=@0",args: 4); //分页查询 var result = tbl.Paged(where: "UnitPrice > 20", currentPage:2, pageSize: 20); var poopy = new {ProductName = "Chicken Fingers"}; //更新 Product对象到表, 条件 ProductID = 12 ,设置 ProductName of "Chicken Fingers" table.Update(poopy, 12) //插入数据 var table = new Categories(); var inserted = table.Insert(new {CategoryName = "Buck Fify Stuff", Description = "Things I like"}); //插入成功后得到返回新对象 var newID = inserted.CategoryID;
Simple.Data
- ADO-based access to relational databases, with providers for:
- SQL Server 2005 and later (including SQL Azure)
- SQL Server Compact Edition 4.0
- Oracle
- MySQL 4.0 and later
- SQLite
- PostgreSQL
- SQLAnywhere
- Informix
- MongoDB
- OData
项目已经比较老,目前已经4-5年未更新代码,里面类文件比较多,算不上轻量级,运用上比较简单
以下是代码截图
![image]()


Chain
一种基于函数式编程理念的Fluent ORM,项目今年少有更新,运用上几乎不写脚本,类似EF的数据对应模型开发,和我们常规面向对象开发有点差异,我对它的获知来源也是在InfoQ上得知,
//插入数据 public int Insert(Employee employee) { return m_DataSource.Insert("HR.Employee", employee).ToInt32().Execute(); } //更新数据 public void Update(Employee employee) { m_DataSource.Update("HR.Employee", employee).Execute(); } //初学者更新实体(但容易出问题,如果对应的漏写了一个属性的赋值) public void Update(Employee employee) { using (var context = new CodeFirstModels()) { var entity = context.Employees.Where(e => e.EmployeeKey == employee.EmployeeKey).First(); entity.CellPhone = employee.CellPhone; entity.FirstName = employee.FirstName; entity.LastName = employee.LastName; entity.ManagerKey = employee.ManagerKey; entity.MiddleName = employee.MiddleName; entity.OfficePhone = employee.OfficePhone; entity.Title = employee.Title; context.SaveChanges(); } } //中级者更新 public void Update(Employee employee) { using (var context = new CodeFirstModels()) { context.Entry(employee).State = EntityState.Modified; context.SaveChanges(); } } //获取指定表全部数据 public IList<Employee> GetAll() { return m_DataSource.From("HR.Employee").ToCollection<Employee>().Execute(); }
压测截图
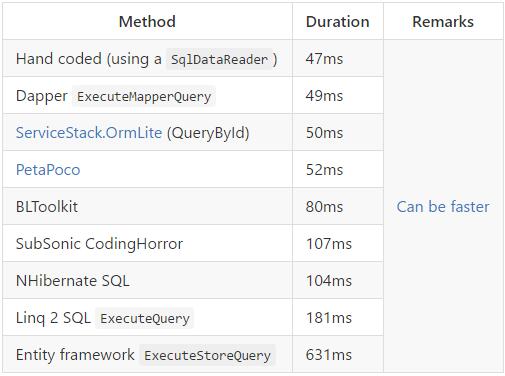
这个压测图是截图Dapper官方代码库里的,估计有点老,下面评论的朋友也纠正了这点,谢谢,所有先忽略这个EF的压测参考,等我实际压测后,会具体分享出优缺点
在博客园里发现这篇软文对EF VS Dapper 的测试:http://www.cnblogs.com/so9527/p/5674498.html#!comments ,那其实我也不用测试压力差距,唯一告诉我们EF也有自身的优势,微软这个产品迭代这么久的版本肯定一直在提升自己,如果有兴趣可以关注 Core 版本的性能,据说很快;如果熟悉DDD构架模式也知道利用EF这两者也是相当的默契度
由于网友:我是so 的要求,我也简单测试一下他的产品,代码如下,就只考虑单线程
Console.WriteLine($"开始Chloe测试");
using (MsSqlContext msSqlContext = new MsSqlContext("server=(local);user id=test;password=test;database=TestDb;"))
{
IQuery<Order> query = msSqlContext.Query<Order>();
//预热,因为我没去查阅你的源码,默认考虑预热
query.FirstOrDefault();
Stopwatch stopwatch = Stopwatch.StartNew();
IList<long> tmsList = new List<long>();
for (int i = 0; i < 10; i++)
{
stopwatch.Restart();
var data = query.ToList();
stopwatch.Stop();
var tms = stopwatch.ElapsedMilliseconds;
tmsList.Add(tms);
Console.WriteLine($"耗时:{tms}");
}
Console.WriteLine($"平均:{tmsList.Average()}");
Console.ReadKey();
}
Console.WriteLine($"开始Dapper测试");
using (IDbConnection connection = new SqlConnection("server=(local);user id=test;password=test;database=TestDb;"))
{
//也进行预热
connection.QueryFirst("SELECT TOP 1 OrderId,OrderNo FROM [Order]");
Stopwatch stopwatch = Stopwatch.StartNew();
IList<long> tmsList = new List<long>();
for (int i = 0; i < 10; i++)
{
stopwatch.Restart();
var data = connection.Query<Order>("SELECT OrderId,OrderNo FROM [Order]"); ;
stopwatch.Stop();
var tms = stopwatch.ElapsedMilliseconds;
tmsList.Add(tms);
Console.WriteLine($"耗时:{tms}");
}
Console.WriteLine($"平均:{tmsList.Average()}");
Console.ReadKey();
}
100万数据读取,模型包含两个字段,在DEBUG模式下单线程测试,单位:毫秒,由于每个人机器配置不同仅供参考
测试最终结果:
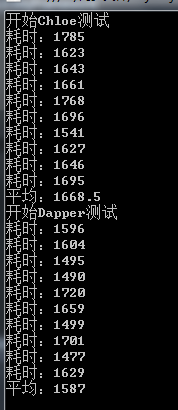
最后分析对比表,如果有异议,欢迎纠正
| ORM框架 | 难易度 | 开源 | 轻量级度 | 性能 | 扩展性 | 项目切入 |
| PetaPoco | 容易 | 是 | 是 | 快 | 方便 | 麻烦点(非T4) |
| Dapper | 容易 | 是 | 是 | 快 | 方便 | 麻烦点 |
| Massive | 中 | 是 | 是 | 快 | 还行 | 有点繁琐 |
| Simple.Data | 容易 | 是 | 是 | 快 | 足够用 | 快速 |
| Chain | 容易 | 是 | 是 | 还可以 | 足够用 | 快速 |
| EF | 容易 | 否 | 否 | 还可以 | 足够用 | 快速 |
纠正一下表格,把编码级改成项目切入更合适....
这篇对比文章的产生主要是我们公司的开发框架体系在做调整,需要基础框架来逐步切入到各个项目中,顺便也调研了这些轻量级ORM,到时进行权衡对比后再此基础上二次可能开发一个自己ORM,会考虑后期的读写库分离并且分布式措施,内部集成短期数据缓存机制等功能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号