
Python知识点复习
一、第一行代码:
在 /home/dev/ 目录下创建 hello.py 文件,内容如下:
1 print("hello,world")
执行 hello.py 文件,即: python hello.py
python内部执行过程如下:
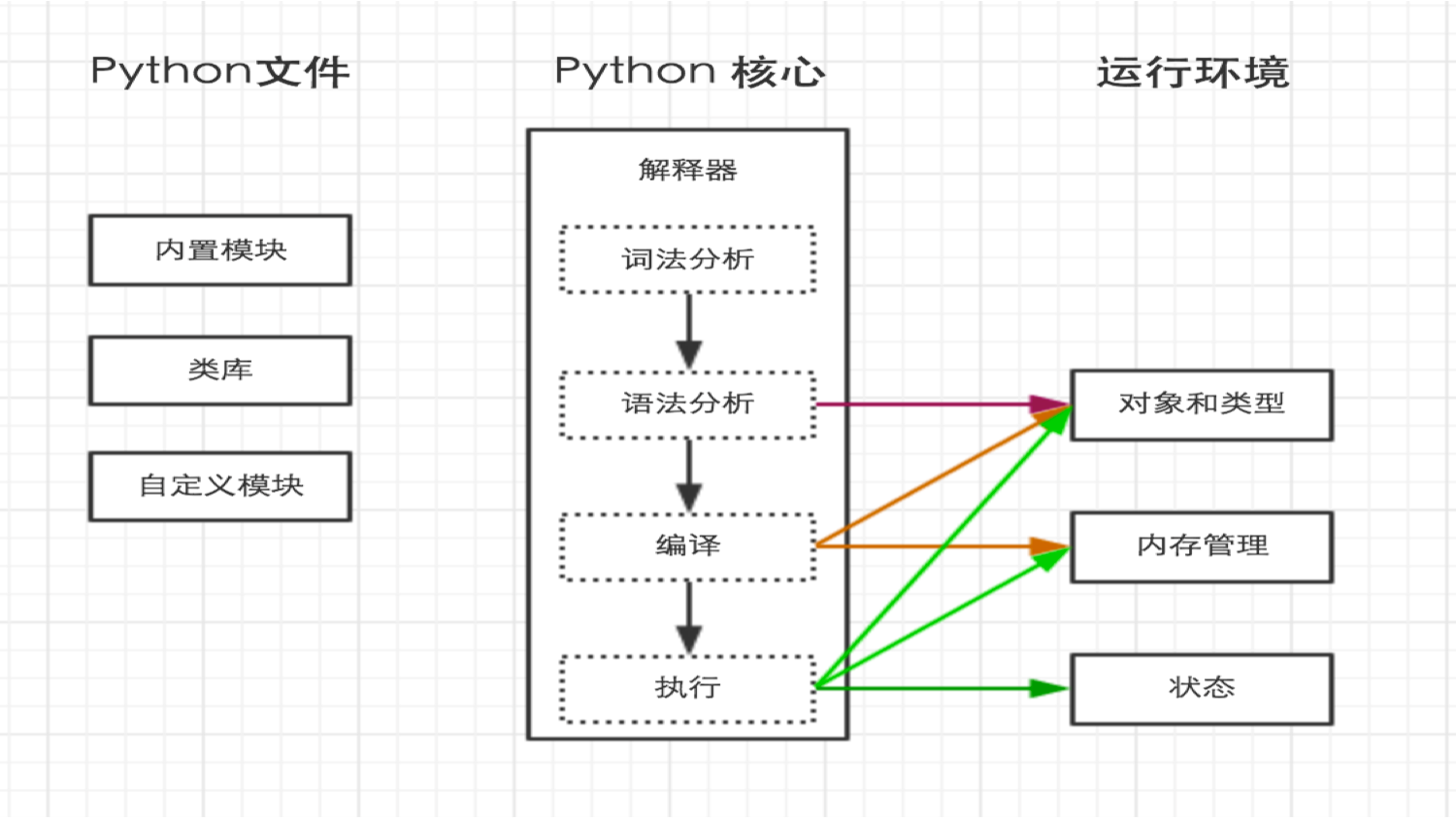
二、解释器:
上一步中执行 python hello.py 时,明确的指出 hello.py 脚本由 python 解释器来执行。
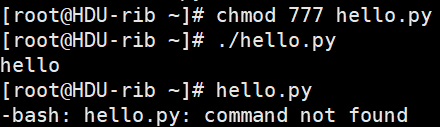
如果想要类似于执行shell脚本一样执行python脚本,例: ./hello.py ,那么就需要在 hello.py 文件的头部指定解释器,如下:
1 #!/usr/bin/env python
2
3 print("hello,world")
如此一来,执行: ./hello.py 即可。
ps:执行前需给予 hello.py 执行权限,chmod 755 hello.py 默认是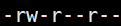 ,可读可写不可执行
,可读可写不可执行
文件开头指定解释器并且赋予权限后就可以直接运行:
python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill)
三、pyc 文件:
执行Python代码时,如果导入了其他的 .py 文件,那么,执行过程中会自动生成一个与其同名的 .pyc 文件,该文件就是Python解释器编译之后产生的字节码。
ps:代码经过编译可以产生字节码;字节码通过反编译也可以得到代码。
四、万恶的字符串拼接:
字符串格式化输出:
name = "alex"
print("i am %s " % name)
#输出: i am alex
PS: 字符串是 %s;整数 %d;浮点数%f
字符串常用功能:
- 移除空白 strip():把头和尾的空格去掉
- 分割 a.split():字符串分割函数
- 长度 len(a)
- 索引 a[0]
- 切片 a[1:2]
a = 'hello world' print(a.split('o')) -->['hell', ' w', 'rld'] a = ' hello world ' print(len(a)) b=a.strip() print(len(b)) -->13 11
五、数据类型转换:
以下几个内置的函数可以执行数据类型之间的转换。这些函数返回一个新的对象,表示转换的值。

str()便于程序员理解,repr()便于interpreter理解(大多数博文也这么说)
同:对于数值、列表、字典等类型,二者具有完全相同的输出。以上类型的共同特征是:与人们理解的意思没有特别不同的表达(也就是说当程序员能理解,interpreter也能理解的时候,二者具有相同输出)
异:对于字符串和浮点数,二者输出明显不同。
举个例子 >>> s = 'hello,world!' >>> str(s) 'hello,world!' >>> repr(s) "'hello,world!'" >>> s1 = 'hello,world!\n' >>> str(s1)//字符串还是字符串,没变 'hello,world!\n' >>> print str(s1)//输出字符串内容且有换行,符合人们理解 hello,world! >>> repr(s1)//注意双斜杠,即多了转义符,且字符串外围又有引号 "'hello,world!\\n'" >>> print repr(s1)//将机器看到的内容原样打印出来,无换行 'hello,world!\n' >>> str(1000L) '1000' >>> repr(1000L) '1000L' >>> str(0.001) '0.001' >>> repr(0.001) '0.001' >>> str(0.00000001) '1e-08' >>> repr(0.00000001) '1e-08' >>>

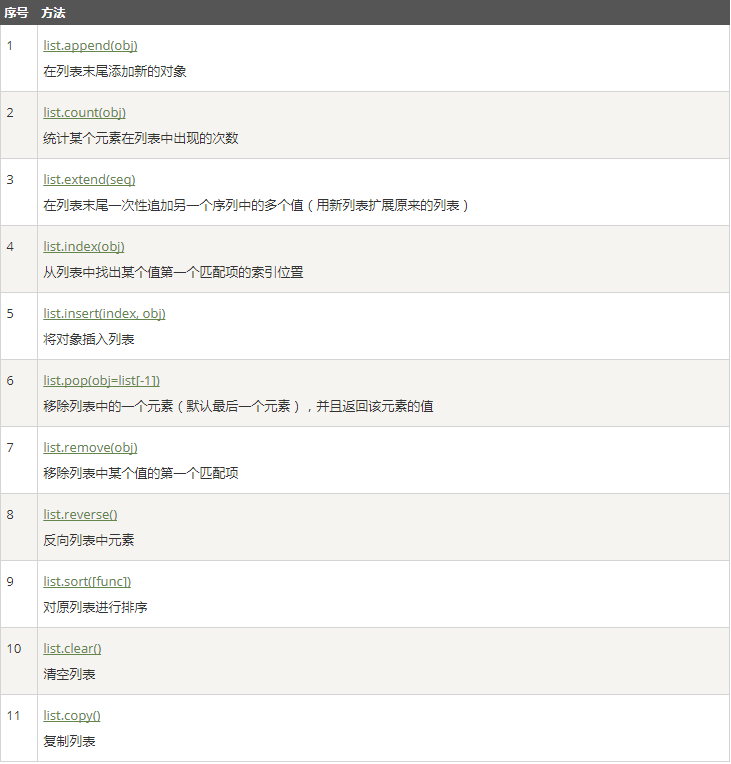
六、列表|元组|字典:
想取最后一个值时,结束位不能是-1,因为结束位的元素不包括,所以只能留空
元组:
用途:一般情况下用于自己写的程序能存下数据,但是又希望这些数据不会被改变,比如:数据库连接信息等
元组只能查和统计,但是可以拼接,创建一个新的数组
tup3 = tup1 + tup2;
字典:
1、字典是无序的;
2,字典的key是唯一的,不允许同一个键出现两次。创建时如果同一个键被赋值两次,后一个值会被记住,如下实例:
dict = {'Name': 'QQ', 'Age': 7, 'Name': 'DD'}
print ("dict['Name']: ", dict['Name']) # DD
3、键必须不可变,所以可以用数字,字符串或元组充当,而用列表就不行,如下实例:
dict = {['Name']: 'Runoob', 'Age': 7}
print ("dict['Name']: ", dict['Name']) # TypeError: unhashable type: 'list'
正确的查找姿势:
>>> stu_info = {"zhangsan":23,"lisi":18,"qigao":18}
#存在则返回对应的value
>>> print(stu_info.get("qigao"))
#不存在返回None
>>> print(stu_info.get("wanger"))
None
或者提前查找是否存在key:
>>> stu_info = {"zhangsan":23,"lisi":18,"qigao":18}
>>> "qigao" in stu_info #标准用法,在Python3和Python2.7都可以用
True
items:
# items() 方法以列表返回可遍历的(键, 值) 元组数组。 dict = {'Name': 'Runoob', 'Age': 7} print ("Value : %s" % dict.items()) #Value : dict_items([('Age', 7), ('Name', 'Runoob')])
循环字典
方法1:
for key in dict: print(key,dict[key])
方法2:
for k,v in info.items(): #会先把dict转成list,数据量大时莫用 print(k,v)
注:
①方法1的效率比方法2的效率高很多
②方法1是直接通过key取value
③方法2是先把字典转换成一个列表,再去取值
④当数据量比较大的时候,用第二种方法时,字典转换成列表的这个过程需要花大量的时间老转换,当然数据量不大,没有关系,效率差不多
打印:
print ("var1[0]:", var1[0]) print ("我叫 %s 今年 %d 岁!" % ('小明', 10)) #我叫 小明 今年 10 岁!
print("{:.2f}".format(3.1415926));
七、字符串|字符编码|转码:
变量a值为字符串 "Hello",b变量值为 "Python":
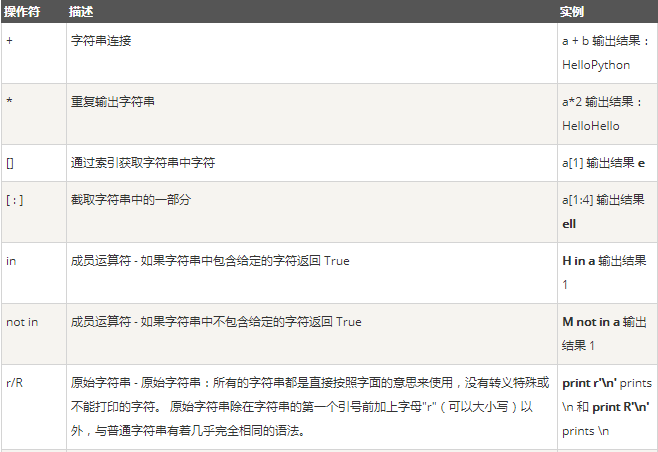
换行在windows上是"\r\n",linux上是'\n'
在python2默认编码是ASCII, python3里默认是unicode
八、copy:
1、数字、字符串的copy:
赋值(=)、浅拷贝(copy)和深拷贝(deepcopy)其实都一样,因为它们永远指向同一个内存地址:
2、列表、元组、字典copy:
赋值(=)
赋值只是创建一个变量,该变量指向原来的内存地址
浅copy:
浅拷贝是指在内存地址中,只拷贝出第一层的内存的地址中的内容形成一个新的地址,第二层还是共用同一个内存地址:
深copy:
浅拷贝是指在内存地址中,拷贝name1第一层和第二层内存地址中的内容形成一个name2的两个新内存地址,两者内存地址不一致,所以无交集
集合
集合是无序的,天生不重复的数据组合
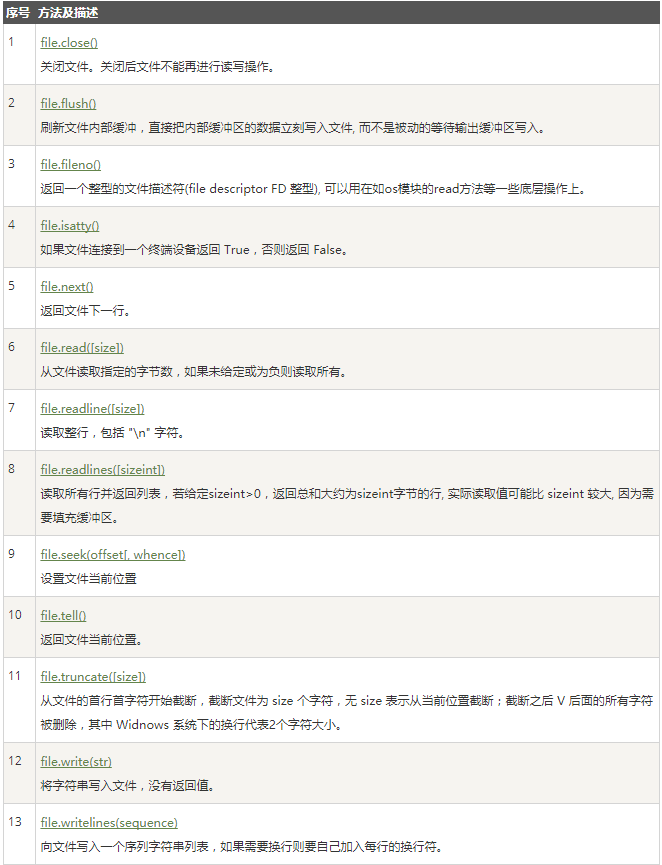
九、文件操作:
1、文件操作的流程:
- 打开文件,得到文件句柄赋值给一个变量
- 通过文件句柄,对文件进行操作
- 关闭文件
#获取文件句柄
f = open("yesterday","r",encoding="utf-8")
注: f 又叫文件句柄,它包含文件的文件名、文件的字符集、文件的大小、文件在硬盘上的起始位置
2、两次读取,第二次读取无内容解疑:
因为在文件中 ,维护一个类似文件指针的一个东西,这个文件指针类似于我们平时操作文件时的光标的东西,所以当第1次读文件后,文件指针已经指向最后一个位置,所以第2次再去读取的时候,是从最后一个位置开始读取的,所以读取的为空。
那怎么再重新读取数据呐?把光标移动到开始位即可
注:在读取文件之前最好导入os模块,判断一下文件是否存在,这是一个好习惯
import os filename = r"C:\Users\HDU-rib\Documents\code\1.txt" if os.path.exists(filename): with open('1.txt','w',encoding='utf-8') as f: f.write('123')
1、with:
为了避免打开文件后忘记关闭,可以通过管理上下文,即:
with open('log','r') as f:
pass
- 形参:指的是形式参数,是虚拟的,不占用内存空间,形参单元只有被调用的时才分配内存单元
- 实参:指的是实际参数,是一个变量,占用内存空间,数据传递单向,实参传给形参,形参不能传给实参
def test(x,y): #x,y是形参 print(x) print(y) test(1,2) #1和2是实参
位置参数|关键字参数
组合使用:位置参数在前,关键字参数在后
注:全局变量的优先级是低于局部变量的,当函数体内没有局部变量,才会去找全局变量
局部变量改成全局变量
- 改前用global先声明一下全局变量
- 将全局变量重新赋值
name = "apple" def test(name): global name #使用global 声明全局变量 print("before change:",name) name = "bananan" #全局变量重新赋值 print("after change:",name) def test1(name): print(name) test(name) test(name1) print(name) #输出 before change: apple after change: bananan bananan bannann
4、全局变量定义成列表
names = ['AAAA',"BBBB"] #定义一个列表
def test():
names[0] = "CCCC"
print(names)
print("--------test-----")
test()
print("------打印names--")
print(names)
注:1、只有字符串和整数是不可以被修改的,如果修改,需要在函数里面声明global。2、但是复杂的数据类型,像列表(list)、字典(dict)、集合(set)、类(class)都是可以修改的。
全局变量和局部变量小结:
- 在子程序(函数)中定义的变量称为局部变量,在程序一开始定义的变量称为全局变量。
- 全局变量的作用域是整个程序,局部变量的作用域是定义该变量的子程序(函数)。
- 当全局变量和局部变量同名时:在定义局部变量的子程序内,局部变量起作用;在其他地方,全局变量起作用。
默认参数
def information_register(name,age,sex,country="CN"):
print("----注册信息------")
print("姓名:",name)
print("age:",age)
print("国籍:",country)
print("课程:",course)
对,只需要把创建country这个形参的时候给它传一个实参就可以:country="CN"。这样就成了默认参数,这个参数在调用时不指定,那默认就是CN,指定了的话,就用你指定的值。另外要注意的一点就是 :我把country变成默认参数后,把他的位置放到了最后,这个是因为关键字参数不能放在位置参数前面,这一点我们上一节随笔有举例子验证。
2、非固定位置参数:*args
作用:接收N个位置参数,转换成元组的形式
注意传入列表前面的*
def test(*args): print(args) print("-------data1-----") test() #如果什么都不传入的话,则输出空元组 print("-------data2-----") test(*[1,2,3,4,5]) #如果在传入的列表的前面加*,输出的args = tuple([1,2,3,4,5]) print("-------data3-----") test([1,2,3,4,5]) #如果再传入的列表前不加*,则列表被当做单个位置参数,所以输出的结果是元组中的一个元素 #输出 -------data1----- () -------data2----- (1, 2, 3, 4, 5) -------data3----- ([1, 2, 3, 4, 5],)
3、非固定关键字传参:**kwargs
作用:把N个关键字参数,转换成字典形式
def test(**kwargs): #形参必须以**开头,kwargs参数名随便定义,但是最好按规范来,定义成kwargs print(kwargs) test(name="qigao",age=18) #传入多个关键字参数 #输出 {'name': 'qigao', 'age': 18} #多个关键字参数转换成字典
def test(**kwargs): print(kwargs) test(**{"name":"qigao","age":18}) #传入字典时,一定要在字典前面加**,否则就会报错 #输出 {'name': 'qigao', 'age': 18}
