数据仓库之数据仓库环境——读书笔记
数据仓库是一个面向主题的,集成的,非易失的,随时间变化的用来支持管理人员决策的数据集合。
数据仓库的数据通常以批量方式载入与访问,但在数据仓库环境中并不进行数据更新。数据仓库中
的数据在进行装载时是以静态快照的格式进行的。当产生后继变化时,一个新的快照记录就会写入
数据仓库。这样,数据仓库中就保存了数据的历史状况。
数据仓库的结构
数据仓库环境中数据存在不同的细节层
- 早期细节层
- 当前细节层
- 轻度综合数据层(数据集市层)
- 高度综合数据层
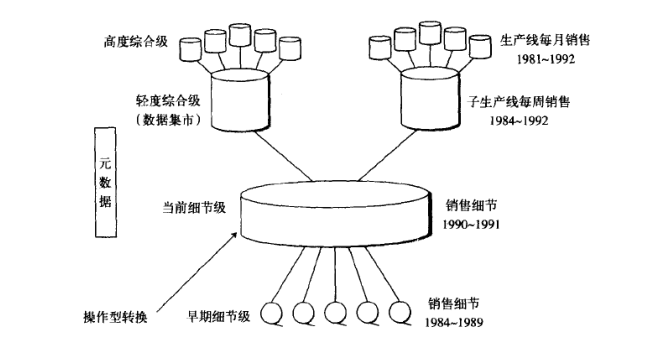
数据由操作型环境导入数据仓库。相当数量的数据转换通常发生在数据由操作层向数据仓库层传输的过程中。
面向主题
数据仓库面向在高层企业数据模型中已经定义好的企业主题,如顾客,产品,交易或活动,政策,索赔,账目。
DASD: 直接存储设备 direct access device
一个主题会以星形模式的方式联系起来,如顾客主题都是以顾客 ID 联系起来的。
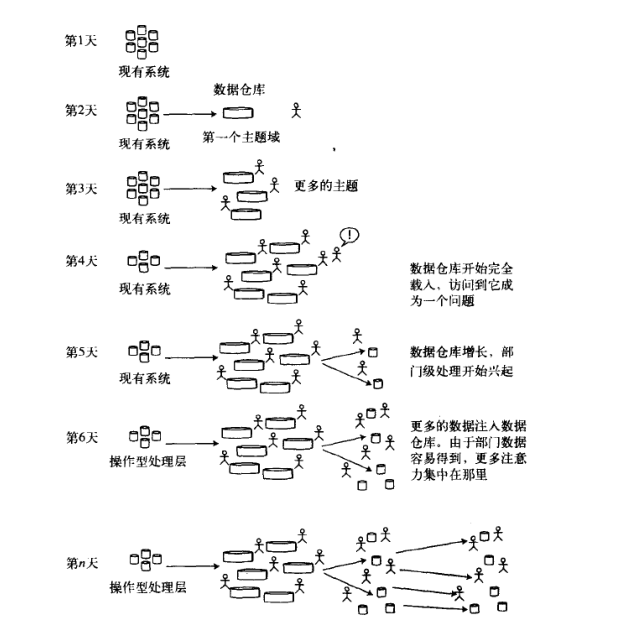
第 1 天到第 n 天的现象
数据仓库只能一步一步的进行设计并载入数据,也就是说它是进化的,而非革命性的。
粒度
粒度是数据仓库中数据单元的细节程度或者综合程度的级别。
细节程度越高,粒度级就越低;细节程度越低,粒度级就越高。
在数据仓库环境中粒度之所以是最重要的设计问题,是因为它会深刻影响存放在数据仓库中的数据量的大小
以及数据仓库所能回答的查询类型。粒度级别越低,查询范围越广泛,反之,粒度级别越高,查询越少。
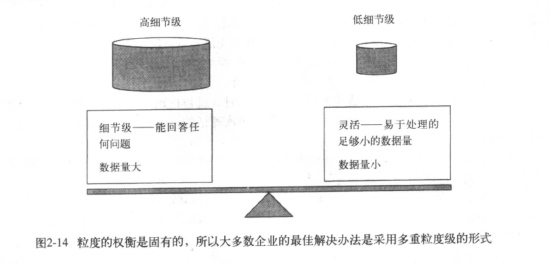
当一个企业或者组织的数据仓库拥有大量数据时,在细节部分采用双重或者多重粒度级别是很有意义的。
活样本数据库
是从数据仓库取得真实档案数据或轻度综合数据的一个子集,其中样本是指它是一个大的数据库的一个子集,活是指这个数据库需要进行周期刷新。
活样本数据用来作统计分析和观察发展趋势,当数据必须以整体观察时,活样本数据库能提供非常理想的结果,但绝不适用于处理单个数据记录。
分区设计方法
数据分区是指将数据分散到可以独立处理的分离物理单元中去。
数据仓库环境中的问题是如何对当前细节数据进行分区
数据仓库的数据组织
1. 简单堆积数据
2. 轮转综合数据
3. 简单直接文件
4. 连续文件
数据仓库中数据的生命周期包含了数据的清理。
数据清理或数据细节转化主要有下面几种方式
- 数据加入到失去原有细节的一个轮转综合文件中
- 数据从高性能的介质 如 DASD 转移到大容量介质上
- 数据从系统中被真正清除
- 数据从体系结构的一个层次转到另一个层次

