多重响应分析,多选题二分法思路

公司开发数据分析模块,此为多选题的, 多重相应二分法
1. 求有效N SELECT COUNT(1) FROM aa where IFNULL(b,N'') or IFNULL(a,N'') 2. 求总数 SELECT COUNT(1) FROM aa 3. 求缺失 2 - 1 = 缺失 4. 响应 SELECT COUNT(1) FROM aa where IFNULL(b,N'')=传的;/响应变量之和 SELECT COUNT(1) FROM aa where IFNULL(b,N'')=传的; SELECT COUNT(1) FROM aa where IFNULL(b,N'')=传的; 5. 个案 SELECT COUNT(1) FROM aa where IFNULL(b,N'')=传的;/有效的和(就是1) SELECT COUNT(1) FROM aa where IFNULL(b,N'')=传的; SELECT COUNT(1) FROM aa where IFNULL(b,N'')=传的;
注意, 小数位数应该保留2位
思路:
举例, 真实数据
P1Q1 P1Q2
1,2,3,4 1,2,3
2,3
=============
最后会拆分成4份
P1Q1_1 P1Q1_2 P1Q1_3 P1Q1_4
1 1 1 1
0 1 1 0
0 ...
1
=============
然后计算频率
百分百 = N / 有效总N
观察百分比 = N / 总N
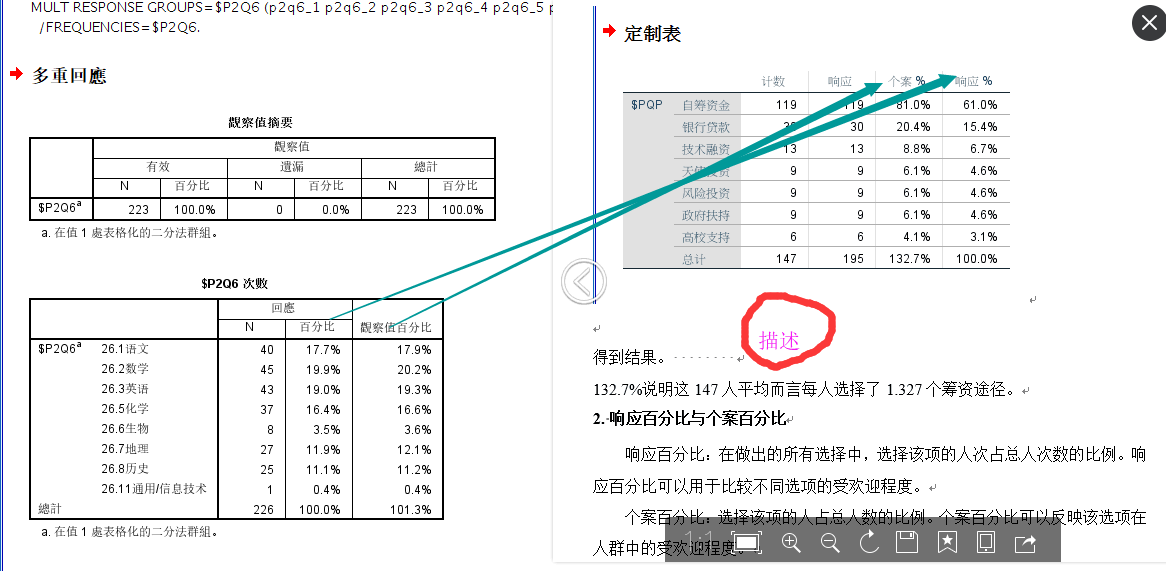
做报告,数据分析时候, 该如何描述
通常百分比用观察值或响应值百分比
python写法
def multiple_choice_percentage(variable_list, table_name): result = read_indexs_by_index(table_name, variable_list) fre_dict_data = {} # fre_percentage_dict_data = {"响应百分比": {}, "个案百分比": {}} # fre_percentage_dict_data = {"个案百分比": {}} fre_percentage_dict_data = {} for i in variable_list: vc = result[i].value_counts() od = sorted(vc.items(), key=lambda d: d[1], reverse=True) # 根据值排序, True 是递减 sub_data = {} for sub_vl in od: aaa = value_labels[variable_list[0]] # {1: '没有建立', 2: '有,但效果不好', 3: '有,效果一般', 4: '有,效果良好'} sub_data[aaa[sub_vl[0]]] = sub_vl[1] fre_dict_data[variable_labels[i]] = sub_data import numpy as np # dropna_count = result[variable_list[0]].dropna().count() dropna_count = result[result.apply(np.sum, axis=1) != 0].dropna(how='all').count()[0] # print(dropna_count) for key, value in value_labels[variable_list[0]].items(): if key == 0: continue fre_percentage_dict_data[value] = {} for j in variable_list: try: fre_percentage_dict_data[value][variable_labels[j]] = float( "%.4f" % (fre_dict_data[variable_labels[j]][value] / dropna_count)) except: fre_percentage_dict_data[value][variable_labels[j]] = float("%.4f" % (0)) return pd.DataFrame(fre_percentage_dict_data)
作者:沐禹辰
出处:http://www.cnblogs.com/renfanzi/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接。
出处:http://www.cnblogs.com/renfanzi/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接。

