离散化和面元划分(可以理解为划分段)
为了便于分析, 连续数据常常被离散化或拆分为“面元”(bin)。假设有一组人员数据, 而你希望将他们划分为不同的年龄组:
ages = [20, 22, 25, 27, 21, 23, 37, 31, 61, 45, 41, 32]
接下来将这些数据划分为“18到25”, 26-35, 35-60, 60以上几个面元。要实现该功能,需要pandas的cut函数:
cut
ages = [20, 22, 25, 27, 21, 23, 37, 31, 61, 45, 41, 32] bins = [18, 25, 35, 60, 100] cats = pd.cut(ages, bins) print(cats)
pandas返回的是一个特殊的Categorical对象。你可以将其看作一组表示面元名称的字符串。实际上它含义一个表示不同分类名称的levels数组以
及一个为年龄数据进行标号的labels属性。, 以及各个阶段人的数量统计
特别注意,已经取消的levels,而且labels将被替换成codes
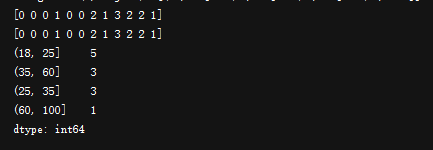
print(cats.labels)
print(cats.codes)
print(pd.value_counts(cats))
调整区间符号
跟“区间”的数学符号一样, 圆括号表示开端, 而方括号表示闭端(包括)。哪边是闭端可以通过right=False进行修改:

自定义面元名称--可以结合value_counts使用
自定义面元名称, 将labels选项设置为一个列表或数组即可:
ages = [20, 22, 25, 27, 21, 23, 37, 31, 61, 45, 41, 32] bins = [18, 25, 35, 60, 100] print(pd.cut(ages, bins, labels=[i for i in "abcd"]))

如果不确定面元切面怎么办
如果向cut传入的是面元数量而不是确切的面元边界, 则它会根据数据的最小值和最大值计算等长面元。看例子, 分4组
data = np.random.rand(20) ret = pd.cut(data, 4, precision=2) print(ret)

qcut 是一个非常类似于cut的函数, 它可以根据样本分位数对数据进行面元划分。
data = np.random.randn(1000) #正泰分布 cats = pd.qcut(data, 4) #按四分位数进行切割 print(cats) print(pd.value_counts(cats))

感觉那里怪怪的,下面这个

作者:沐禹辰
出处:http://www.cnblogs.com/renfanzi/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接。
出处:http://www.cnblogs.com/renfanzi/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接。

