数据规整化:pandas 求合并数据集(交集并集等)
数据集的合并或连接运算是通过一个或多个键将行链接起来的。这些运算是关系型数据库的核心。pandas的merge函数是对数据应用这些算法的这样切入点。
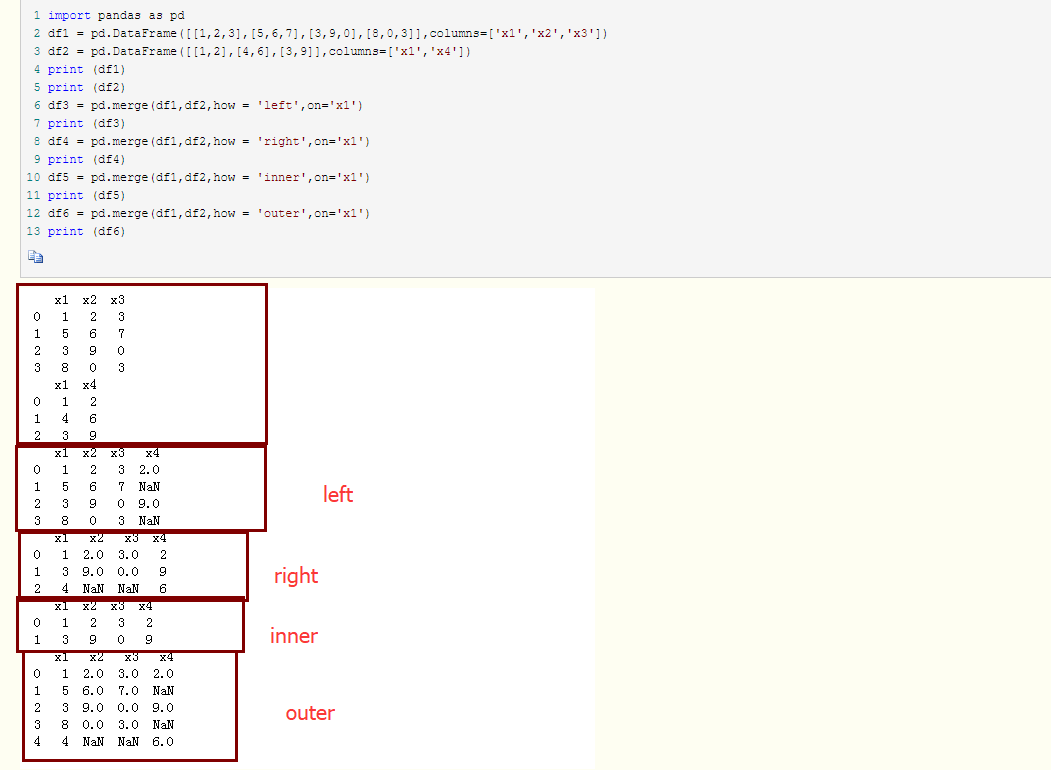
默认是交集, inner连接
列名不同可以分别指定:

其他方式还要‘left’、‘right’以及“outer”。外链接求取的是键的并集, 组合了左连接和右连接的效果。

how 的作用是合并时候以谁为标准,是否保留NaN值
多对多

多对多 连接产生的行的笛卡尔积。由于左边的DataFrame有3个‘b’行, 右边的有2个,所以最终结果中
就有6个‘b’行。

根据多个键进行合并, 传入一个由列明组成的列表即可:

left = DataFrame( {"key1": ['foo', 'foo', 'bar'], "key2": ['one', 'two', 'one'], "lval": [1, 2, 3] } ) right = DataFrame( {"key1": ['foo', 'foo', 'bar', 'bar'], "key2": ['one', 'one', 'one', 'two'], "rval": [4, 5, 6, 7] } ) print(left) print(right) pm = pd.merge(left, right, on=["key1", "key2"], how="outer") print(pm)


on与left_on 和right_on的区别

这个是left_on 和right_on

去重或更改后缀

merge函数的参数

索引上的合并

merge方法求取连接键的并集

对于层次化索引的数据
这个时候必须以列表的形式指明用作合并键的多个列(注意对重复索引的处理)
lefth = DataFrame({'key1':[ 'Ohio', 'Ohio', 'Ohio','Nevada', 'Nevada',],
"key2":[2000, 2001, 2002,2001, 2002],
"data":np.arange(5.)
})
righth = DataFrame(np.arange(12).reshape((6, 2)),
index=[['Nevada', 'Nevada', 'Ohio', 'Ohio', 'Ohio', 'Ohio'],
[2001, 2000, 2000, 2000, 2001, 2002]],
columns=['event1', 'event2']
)
print(lefth)
print(righth)
pm = pd.merge(lefth, righth,left_on=['key1', 'key2'], right_index=True)
print(pm)

索引并集

DataFrame.join实例方法
它能更为方便地实现索引合并。它还可用于和合并多个带有相同或相似索引的DataFrame对象, 而不管他们
之间有重叠的列。

print(left1.join(right1, how='inner'))
left2.join([1, 2], how='outer') #多个
作者:沐禹辰
出处:http://www.cnblogs.com/renfanzi/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接。
出处:http://www.cnblogs.com/renfanzi/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接。

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步