处理缺失数据
简介
缺失数据(missing data)在大部分数据分析应用中都很常见。pandas的设计目标之一就是让缺失数据的处理任务尽量轻松。
例如, pandas对象上的所有描述统计都排除了缺失数据。
pandas使用浮点值NaN(not a Number)表示浮点和非浮点数组中的缺失数据。它只是一个便于被检测出来的标记而已
由于Numpy的数据类型体系中缺乏真正的NA数据类型或定位模式, 所以它是我能想到的最佳解决方案
NA处理方法

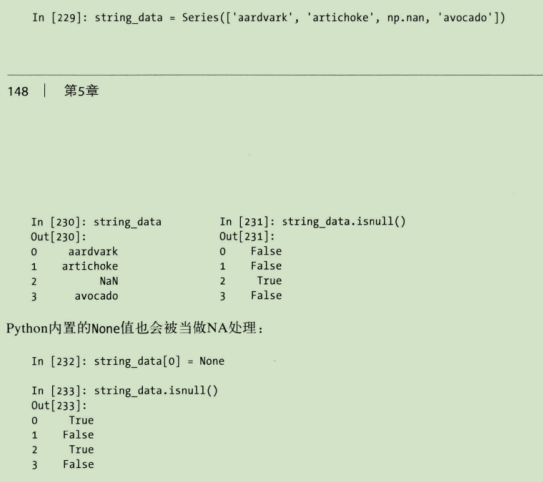
判断缺失数据, isnull()
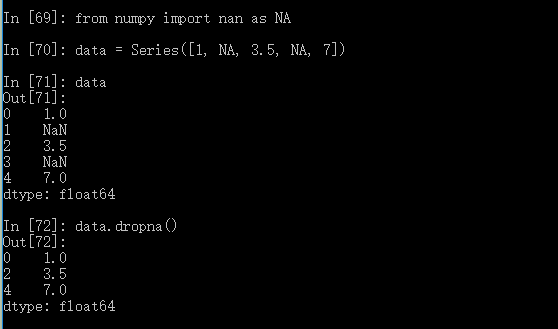
滤除缺失数据, dropna()
布尔类型索引取值

DataFrame
面对DataFrame对象, 事情变得复杂了。 你可能希望丢弃全NA或含有NA的行货列。drop默认丢弃任何含有缺失值的行:
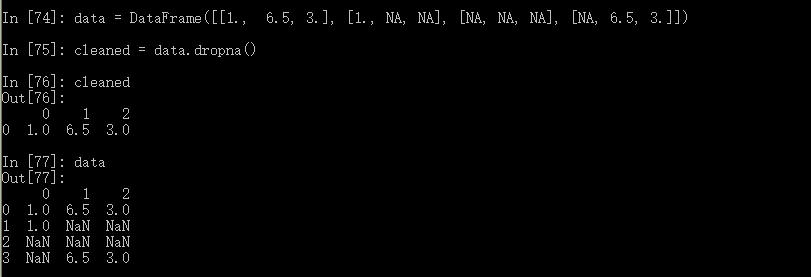
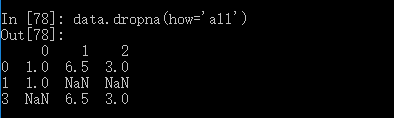
丢弃全为NA的行:
丢弃全为NA的列:

翻滚数据

填充缺失数据 fillna() ,fillna(0, inplace=True)对现有对象修改

fillna value调用一个字典{}作为标量值用于填补缺失值。





作者:沐禹辰
出处:http://www.cnblogs.com/renfanzi/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接。
出处:http://www.cnblogs.com/renfanzi/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接。

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步