


如何提高Dragonbones骨骼文件的读取速度----Dragonbones4.5版本骨骼文件的二进制解析方案
Dragonbones的默认导出的骨骼文件为xml、json文件。尽管xml、json文件有一些自身的优势,但是在手游上,硬件条件有限的情况下,追求更快的运行速度,xml、json却无法满足需求。尤其是需要一次性加载很多的xml文件时,效率完成暴露出来了。这也就是我为什么写这篇blog的目的。如何提高文件的读取速度,无非就是将骨骼文件转换成二进制文件去解析。
注:本篇blog是基于Dragonbones 4.5的数据格式进行的二进制转换。
如何转换,下面我为大家讲解具体过程:
准备工作
1、这里我们要用到一个google的开源库Flatbuffers,关于Flatbuffers如何使用,大家可以转到c++对象的序列化与反序列化的解决方案----flatbuffers的使用,有具体介绍如何使用。
2、DragonBoneFlatbuffer是我写好的一个dragonbones骨骼数据的转换工具的源代码,这里我主要是介绍如何使用,以方便以后大家自己修改。
工程简介
项目中有两个目录:tools、xmlToBinary 。tools里面主要是flatbuffers的schema定义文件、将schema转换成.h的flatc的可执行文件(mac版本)、还有一个用来执行转换命令的shell脚步文件。xmlToBinary就是我们的主要工程文件,里面有xcode和vs的两个工程,直接打开编译就可以得到我们的工具。
。tools里面主要是flatbuffers的schema定义文件、将schema转换成.h的flatc的可执行文件(mac版本)、还有一个用来执行转换命令的shell脚步文件。xmlToBinary就是我们的主要工程文件,里面有xcode和vs的两个工程,直接打开编译就可以得到我们的工具。
一、Tools目录介绍
dragonbones.fbs文件中有很多的Flatbuffers对象属性,这些属性的定义,我是根据c++中dragonbones对象的属性一一对应创建的。这样保证我的c++对象的每个有用的成员变量都能在Flatbuffers的对象属性中找到与之对应。关于更多关于fbs文件的写法,大家可以看c++对象的序列化与反序列化的解决方案----flatbuffers的使用或是参考官方的文档。
flatc文件是flatc.cpp文件编译得到的。大家可以在下面的连接中找到https://github.com/Relvin/DragonBoneFlatbuffer/tree/master/xmlToBinary/classes/flatbuffers。(当然这里的flatbuffers并不是google官方最新的文件。这个是我为了与cocos2dx中引用的flatbuffers库保持统一,直接从cocos2dx项目中拉出来了。这样我们如果想加入到我们的cocos2dx项目工程中就不需要自己添加Flatbuffers库,而直接引用cocos自带的就可以了。)如果你是windows的用户你就可以在windows平台上编译一个flatc的可执行文件。
generate_code.sh就是用flatc将fbs文件转换成c++可用的头文件的参数选项./flatc -c --no-prefix -o ./../xmlToBinary/Classes ./dragonbones.fbs.
usage: ./flatc [OPTION]... FILE... [-- FILE...] -b Generate wire format binaries for any data definitions. -t Generate text output for any data definitions. -c Generate C++ headers for tables/structs. -g Generate Go files for tables/structs. -j Generate Java classes for tables/structs. -n Generate C# classes for tables/structs. -o PATH Prefix PATH to all generated files. -I PATH Search for includes in the specified path. --strict-json Strict JSON: add quotes to field names. --no-prefix Don't prefix enum values with the enum type in C++. --gen-includes Generate include statements for included schemas the generated file depends on (C++). --proto Input is a .proto, translate to .fbs. FILEs may depend on declarations in earlier files. FILEs after the -- must be binary flatbuffer format files. Output files are named using the base file name of the input,and written to the current directory or the path given by -o. example: ./flatc -c -b schema1.fbs schema2.fbs data.json
二、xmlToBinary项目目录介绍。
这里我主要讲两个文件xmlToBinary.cpp(Classes目录下)和BinaryParser.cpp(Classes/parsers目录下),其他文件都是Dragonbones定义的数据文件和数据解析文件。
1、xmlToBinary.cpp
这个就是如何实现从xml转换成二进制文件的过程(即c++对象的序列化过程)。原理很简单,过程比较繁琐。将xml文件先解析成c++对象,然后将c++对象转换成Flatbuffers对象存到本地。里面的每个转换过程代码都写的很明确,大家可以运行代码,然后断点调试查看。
2、BinaryParser.cpp
将二进制文件读取成c++对象(反序列化的过程)。代码已经写的很明确,都是简单的取值操作,没有很强的逻辑在里面。
注:
如果有比较细心的童鞋可能会发现我的.fbs文件中定义一个PointOption和Vec2Option,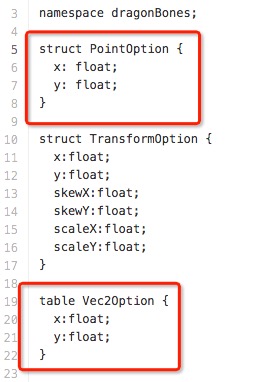 他们两出了类型不一样,其他都一样。这是为什么呢!因为早期我将坐标定义为结构体类型,在后来的扩展过程中没有找到Flatbuffers中压如结构体数组的方法,为了避免对以前代码的改动,我就加了一个坐标对象属性,又来解决Flatbuffers中压结构体数组的问题。如果各位在研究和学习中有解决这个问题,还望告知我。
他们两出了类型不一样,其他都一样。这是为什么呢!因为早期我将坐标定义为结构体类型,在后来的扩展过程中没有找到Flatbuffers中压如结构体数组的方法,为了避免对以前代码的改动,我就加了一个坐标对象属性,又来解决Flatbuffers中压结构体数组的问题。如果各位在研究和学习中有解决这个问题,还望告知我。
谢谢各位的阅读!
各位有什么疑问可以直接在我的blog下留言或者是发送的我的个人邮箱relvin@qq.com。

