

HBase介绍
HBase介绍
HBase是Hadoop生态系统中一个重要的NOSQL存储,它一些设计思想来自于Google的Bigtable,因此在Key-Value存储结构上与同出一门的Cassandra有相似之处。
一,HBase出现的背景
随着数据规模越来越大,大量业务场景开始考虑数据存储水平扩展,使得存储服务可以增加/删除,而目前的关系型数据库更专注于一台机器。
海量数据量存储成为瓶颈,单台机器无法负载大量数据。
单台机器IO读写请求成为海量数据存储时候高并发,大规模请求的瓶颈。
当数据进行水平扩展时候,如何解决数据IO高一致性问题。
结合Map/Reduce计算框架进行海量数据的离线分析。
二,应用场景
HBase与同时代的cassandra,mongoDB相比,其是一个重量级的nosql存储系统。根据一些信息来源,目前实际产线中cassandra最大部署规模在400台左右,Mongodb则实际应用少见。其它例如memcache,redis,实际上很难说它是个nosql存储,只能说是缓存存储,存储数据量有限。
cassandra出现这样的一个重要问题在于随着集群规模越来越大,由于缺乏master节点导致缓存命中率可能非常差。
而HBase在facebook部署有上千台规模。
HBase一个最重要的特性在于,其在满足海量存储规模的前提下,数据读写IO变化幅度并不是特别明显,延迟性变化幅度相对较小。
与cassandra不同的是,cassandra满足CAP原则的高可用性,分区可容忍性原则,而HBase则满足了分区可容忍性,高一致性原则,对于高可用性,HBase由于HMaster单点失败问题而无法满足。
另外一个重要特性在于,HBase与hadoop HDFS,Map/Reduce的天然结合,这是其他NOSQL存储无法比拟的优势。
例如在hadoop0.20.2 map/reduce new API中,对于海量数据全局排序,由于缺乏TotalOrderPartitioner对new API支持,甚至直接都可以使用HBase库中的TotalOrderPartitioner包进行处理。
HBase与hadoop平台能够结合的一个最大优势在于,HBase分布式存储后数据分块的replication由hadoop HDFS自动分发完成。HBase是一个读写延迟性相对较低的nosql存储,与hadoop HDFS存储相比,HBASE更专注于单条数据交互读写,低延迟性;而HADOOP HDFS则更专注于批量数据的读写,更专注于高吞吐量,导致其延迟性较高。
因此对于在线业务应用场景产生的数据,需要进行离线分析时,直接对HADOOP HDFS操作,将使得前期工作更为复杂,需要考虑数据提前合并,避免HADOOP 小文件存储对NameNode editlog产生的影响,同时还要考虑文件追加写入,这恰恰是Hadoop HDFS不具有的功能。
因此HBase能够在Hadoop 生态系统中出现,是有一定原因,它弥补了hadoop上述的缺陷,使得hadoop生态系统服务更加全面。
三,HBase部署的简单描述。
HBase部署相对是一个较大的动作,其依赖于zookeeper cluster,hadoop HDFS。
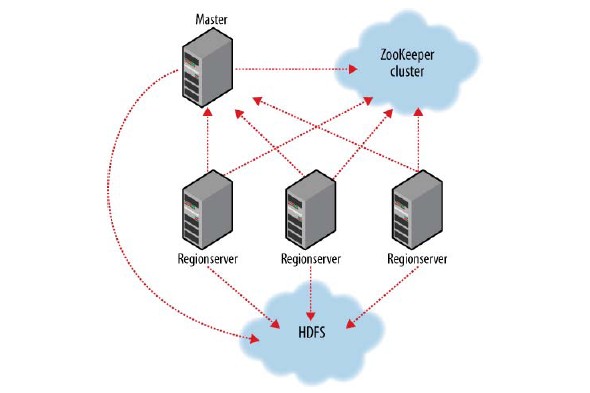
其中Zookeeper作用在于:
1,hbase regionserver 向zookeeper注册,提供hbase regionserver状态信息(是否在线)
2,hmaster启动时候会将hbase 系统表-ROOT- 加载到 zookeeper cluster,通过zookeeper cluster可以获取当前系统表.META.的存储所对应的regionserver信息。
HMaster主要作用在于,通过HMaster维护系统表-ROOT-,.META.,记录regionserver所对应region变化信息。此外还负责监控处理当前hbase cluster中regionserver状态变化信息。
hbase regionserver则用于多个/单个维护region。
region则对应为hbase数据表的表分区数据维护。
posted on 2012-03-22 17:40 reck for zhou 阅读(3178) 评论(1) 编辑 收藏 举报


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步