
软工第五次作业-结对作业2
Github地址:https://github.com/qwe8/pair-project
队友博客: https://www.cnblogs.com/SororTina/p/9768837.html
分工
林志华: 完成爬虫及将第一次作业C++代码转化为JAVA代码
王焕仁: 使用JAVA实现其余功能
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 60 |
| · Estimate | · 估计这个任务需要多少时间 | 7(d) | 14(d) |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 3(d) | 5(d) |
| · Design Spec | · 生成设计文档 | 10 | 10 |
| · Design Review | · 设计复审 | 10 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| · Design | · 具体设计 | 60 | 60 |
| · Coding | · 具体编码 | 2(d) | 4(d) |
| · Code Review | · 代码复审 | 1(d) | 2(d) |
| · Test | · 测试(自我测试,修改代码,提交修改) | 1(d) | 2(d) |
| Reporting | 报告 | 60 | 60 |
| · Test Repor | · 测试报告 | 60 | 60 |
| · Size Measurement | · 计算工作量 | 30 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 60 | 60 |
| | 合计 | 7(d) | 14(d)
解题思路与设计
这次作业我们选择用JAVA来写,是经过深思熟虑的。其一是觉得用C++来写爬虫的话,对我们来说都没有接触过,而且听说很麻烦的。其二是觉得需要学习一下JAVA的用法,毕竟是现在最火的语言。其三,是我其实大一下学期有自学过JAVA,但长时间没用变得很生疏,现在重新拾起来感觉也不错。由上三点我们选择了JAVA来解题。
-
爬虫使用
这次的爬虫我们并没有使用爬虫工具,而是我们自己写的。
具体如下:
我使用jsoup用来解析网页的HTML。一开始是利用jsoup的connect函数来获取网站的html存放到Document对象中,后来我发现用这个方法爬取到的论文数量只有501篇,后面的所有论文全都消失了,十分奇怪,我debug了很长一段时间,都没发现自己的问题,后来我查阅了一下资料,发现jsoup爬取的html其实是静态的,比如说有些网站一开始是只加载一部分内容的,等一段时间或则你把滚动条往下拉它才会加载下面的内容,很不幸,要求爬取的论文网站就是这样子的,所以如果只使用jsoup来爬取的话肯定会出现只爬取到501篇论文这样的问题。
对于这样的问题,我的解决方法是用httpclient来动态爬取论文网站的html,然后再使用jsoup来解析html。如何使用httpclient爬网站的html这里我就不详细讲了,毕竟都烂大街了。我详细讲一下如何使用jsoup。
首先我们用浏览器打开CVPR2018官网,然后找到论文标题所在的位置,右键复制标题的CSS选择器,复制之后随便找个地方黏贴一下,dt.ptitle:nth-child(1) > a:nth-child(2)。
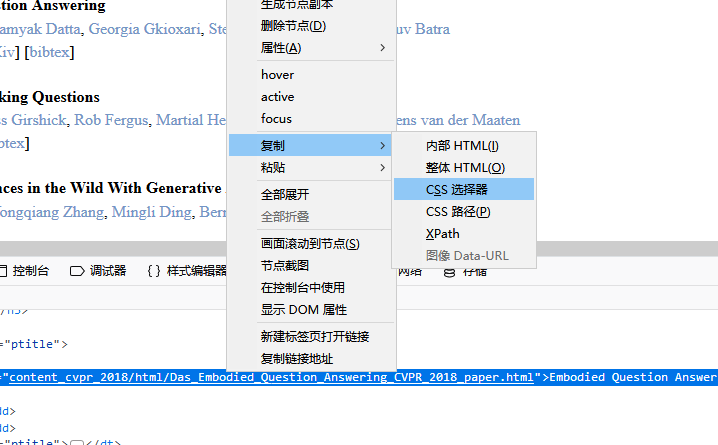
从单单这个标题我们还看不出什么东西,我们再复制一下下一篇论文的CSS选择器:dt.ptitle:nth-child(4) > a:nth-child(2),可以发现第一个选择参数的括号里的值增加了三,那么再多复制几个,即可发现所有标题的选择器是dt.ptitle:nth-child(1+3n) > a:nth-child(2)。所以我们即可利用下面的代码来爬取所有标题:
Elements test=document.select("dt.ptitle:nth-child(1)").select("a:nth-child(2)");
String str=test.text();//返回的是标题
String url2=test.attr("href"); // 爬取
爬取到标题后,可以用爬取标题的超链接,然后爬取这个超链接指向的网站,使用上述的方法继续爬取即可。
String url2=test.attr("href");//爬取标题的 href 值
Document document2 = Jsoup.connect("http://openaccess.thecvf.com/"+ url2).userAgent("Mozilla/4.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)").timeout(50000).get();//下个网页可以直接使用jsoup来爬取html。
-
代码组织与内部实现设计
我们把所有的功能都封装成一个类,结构图如下:
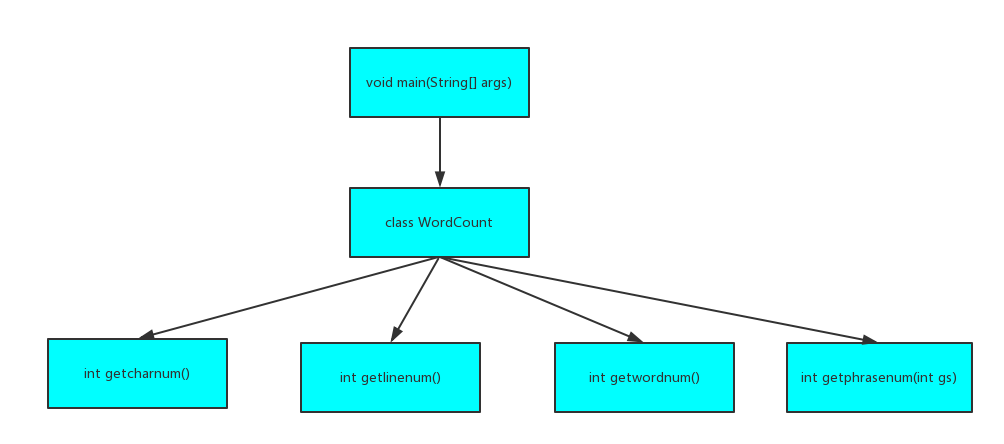
类中具体函数如下:
public class WordCount {
private static List<HashMap.Entry<String, Integer>> words = null; //存放单词
private static List<HashMap.Entry<String, Integer>> phrases = null; //存放词组
public WordCount(File fileIn); // 类构造函数
public int getcharnum(); // 获取字符数
public int getlinenum(); // 获取行数
public int getwordnum(); // 获取单词数
public int getphrasenum(int gs); //获取词组数
}
-
说明算法的关键与关键实现部分流程图
关键代码解释
爬虫部分:
public static void main(String []args)throws IOException{
String URL="http://openaccess.thecvf.com/CVPR2018.py";
String content= getHtmlByUrl(URL); //使用httpclient 爬取网页html
Document document = Jsoup.parse(content); //使用Jsoup来解析html
String num,left="dt.ptitle:nth-child(",right="a:nth-child(2)"; //设定CSS选择器
int t=1,nb=0; //t为left的参数
File f=new File("result.txt");
PrintWriter pw=new PrintWriter( new FileWriter(f,true) );
while(t<=2935){
num=t+"";
Elements test=document.select(left+num+")" ).select(right);//利用CSS选择器来抓取标题那部分的html
String str=test.text();// 获取标题
String url2=test.attr("href"); //获取标题的超链接
//根据超链接利用jsoup爬取下个网页的html
Document document2 = Jsoup.connect("http://openaccess.thecvf.com/"+ url2).userAgent("Mozilla/4.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)").timeout(50000).get();
Elements test2=document2.select("#abstract"); // 选择abstract部分
String str2=test2.text();
System.out.println("输出到第"+nb+"个");
pw.write(""+nb);pw.write("\r\n");
pw.write("Title: "+ str);pw.write("\r\n");
pw.write("Abstract: "+str2);pw.write("\r\n\r\n\r\n");
t+=3;nb++;
}
pw.close();
System.out.println("爬取完成");
}
词组统计部分:
public int getphrasenum(int gs) {
if(gs == 0) return -1; // gs为限定词组所包含单词的个数,gs为0时不进行词组统计
int phrasenum = 0, quan = 1;
String temp;
/*将contents字符串数组根据分隔符切割成若干个单词,并以全部为小写字母的形式存入contents1中*/
String[] contents1 = content.toLowerCase().split("[^0-9A-Za-z]");
/*枚举以第i个单词为开头的词组*/
for(int i = 0; i <= contents1.length - gs; i++) {
bool flag = true; // flag标志着该词组是否符合要求
temp = "";
/*根据要求设置每个单词的权重*/
if(contents1[i].equals("title")) {quan = (use_quan == true ? 10 : 1);continue;}
if(contents1[i].equals("abstract")) {quan = 1; continue;}
/*判断后m-1个单词是否能够满足要求*/
for(int j = 0; j < gs; j++) {
if(contents1[i + j].equals("abstract") || contents1[i + j].equals("title")) {flag = 0; break;}
if(contents1[i + j].length()>=4){
if(Character.isLetter(contents1[i + j].charAt(0))){
if(Character.isLetter(contents1[i + j].charAt(1))){
if(Character.isLetter(contents1[i + j].charAt(2))){
if(Character.isLetter(contents1[i + j].charAt(3))){
temp += contents1[i + j];
if(j != gs - 1) temp += " ";
continue;
}
}
}
}
}
flag = false;
}
if(flag == true) { // 满足要求的词组,计算权重后存放在map中进行排序
if(mb.containsKey(temp)) {
int x = (int)mb.get(temp);
mb.put(temp, x + quan);
phrasenum++;
}
else mb.put(temp, quan);
}
}
if(!mb.isEmpty()) phrases = Sort(mb);
return phrasenum;
}
ps:由于当事人的能力不足,这个功能只能简单的以单词都为一个空格为分隔符的基础上,进行词组统计,在之后的学习中,会尽力地完善这个部分让它能够满足大部分的数据。
性能分析与改进
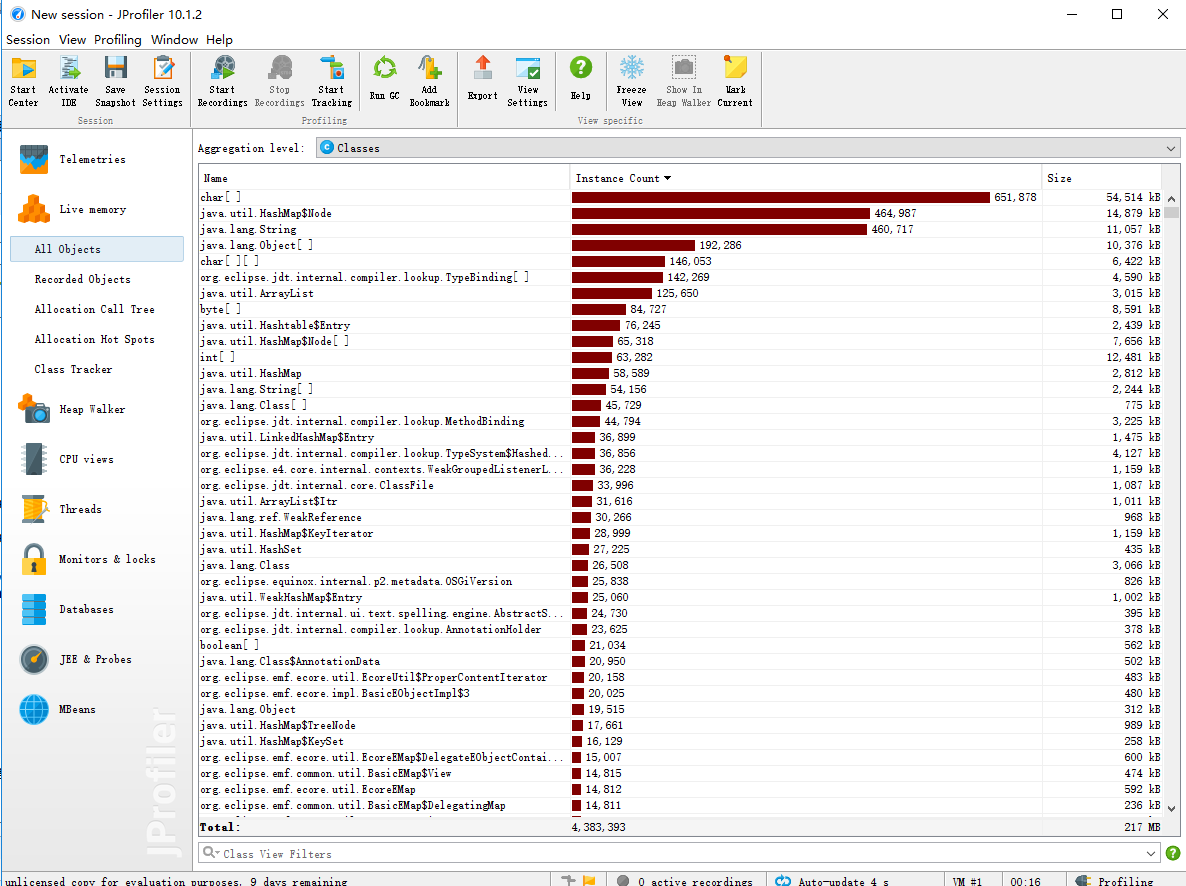
性能分析图如下:
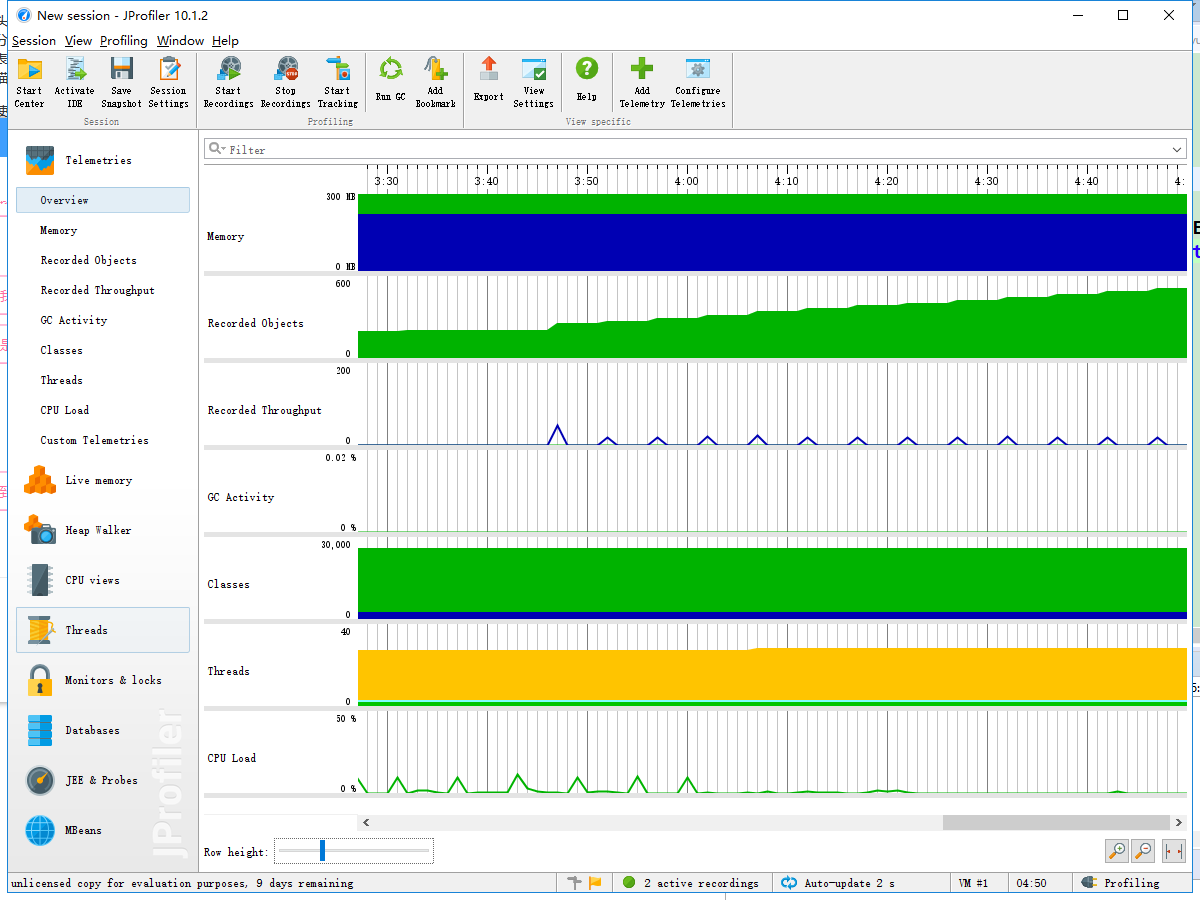
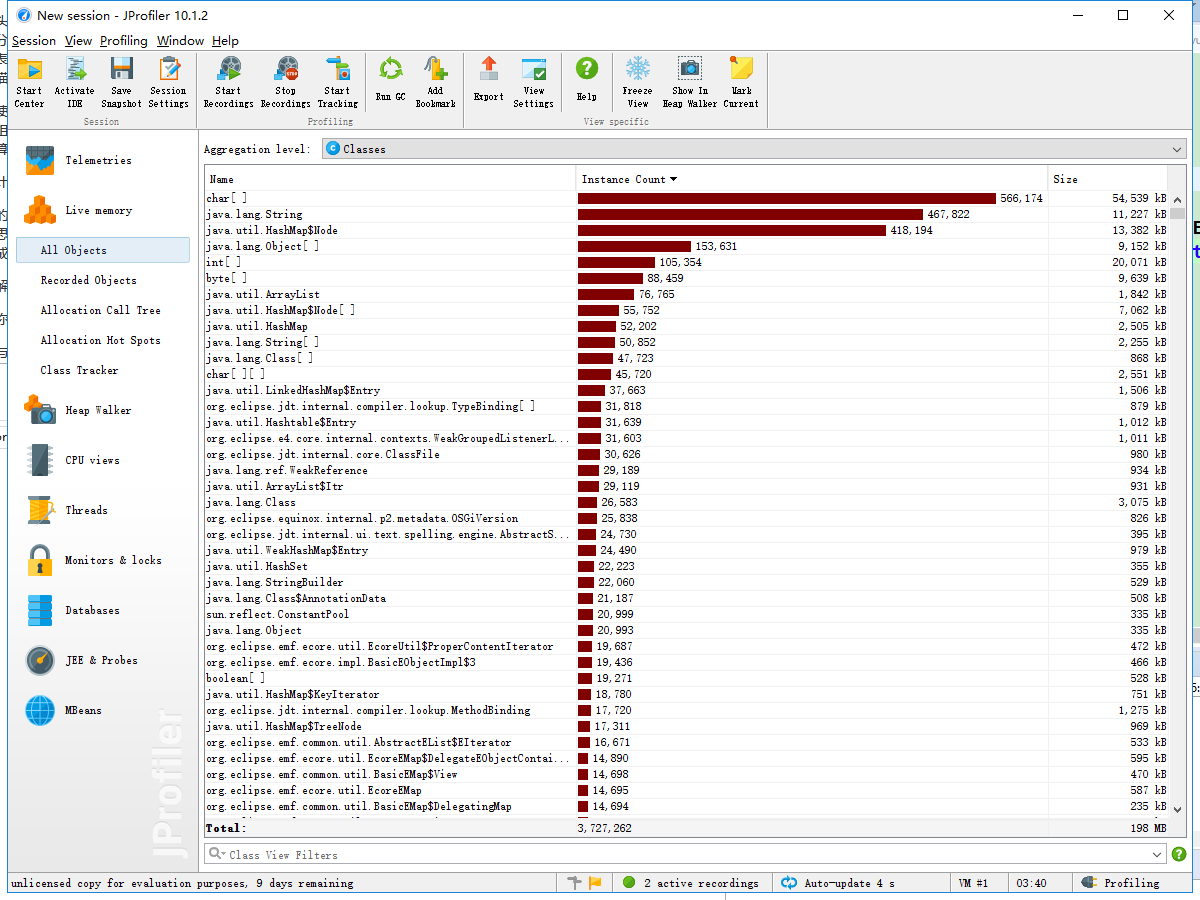
通过性能分析我发现HashMap这个容器使用耗时非常多,后来发现当用户需要经行词组统计时,程序还是会进行单词统计的一些步骤,就是把单词给丢到HashMap中,可实际上这是不需要的。所以我们在类中设置一个boolean参数来表示是要经行单词统计还是要经行词组统计,不统计的那部分就不需要再使用HashMap,理论上这可将时间优化将近一倍。
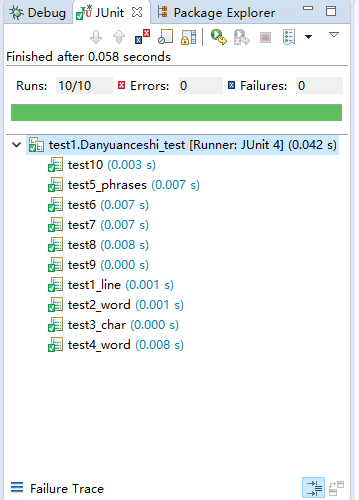
单元测试
十个单元测试如下:
- 1.测试字符数是否正确(去除title,abstrac等等)
- 2.测试行数是否正确
- 3.测试不带权值的单词词频是否正确
- 4.测试带权值的单词词频是否正确
- 5.测试不带权值的词组词频是否正确
- 6.测试带权值的词组词频是否正确
- 7.测试-n限制下输出是否正确
- 8.测试-m限制下输出是否正确
- 9.测试输入文件为空时是否正确
- 10.测试输出文件未给是否正确
测试结果如下:
以下给出三个测试代码:
@Test
public void test4(){// 测试 不出现-m 的 -w 1
File file = new File("4.txt");
WordCount count = new WordCount(file);//实例话WordCount类
count.set_quan(true);
int wordnum = count.getwordnum();//读取单词数
int linenum = count.getlinenum();//获取有效行数
assertEquals(wordnum, 29);
assertEquals(linenum, 3);
List<HashMap.Entry<String, Integer>> m = count.getWords();
int aa=m.get(0).getValue();
String bb=m.get(0).getKey();
assertEquals( aa , 51);
assertEquals(bb, "embodied");
}
@Test
public void test6(){ // 测试 出现-m 的 -w 1
File file = new File("6.txt");
WordCount count = new WordCount(file);//实例话WordCount类
count.set_quan(true);
int wordnum = count.getwordnum();//读取单词数
int linenum = count.getlinenum();//获取有效行数
int phrasenum = count.getphrasenum(3);//获取有效词组数
assertEquals(wordnum, 29);
assertEquals(linenum, 3);
List<HashMap.Entry<String, Integer>> m = count.getPharses();
int aa=m.get(0).getValue();
String bb=m.get(0).getKey();
assertEquals( aa , 20);
assertEquals(bb, "embodied embodied embodied");
}
@Test
public void test8(){ // 测试 -m 参数 接收
File file = new File("8.txt");
WordCount count = new WordCount(file);//实例话WordCount类
int wordnum = count.getwordnum();//读取单词数
int linenum = count.getlinenum();//获取有效行数
int phrasenum = count.getphrasenum(8);//获取有效词组数
assertEquals(wordnum, 64);
assertEquals(linenum, 3);
List<HashMap.Entry<String, Integer>> m = count.getPharses();
int aa=m.get(0).getValue(),cc=m.get(9).getValue();
String bb=m.get(0).getKey(),dd=m.get(9).getKey();
assertEquals( aa , 4);
assertEquals(bb, "asdf zxcv jklq aaaa asdf zxcv jklq aaaa");
assertEquals( cc , 1);
assertEquals(dd, "aaaa wjoi oifvf nvxlj qwoei jfsiod fdss vffr2f4");
}
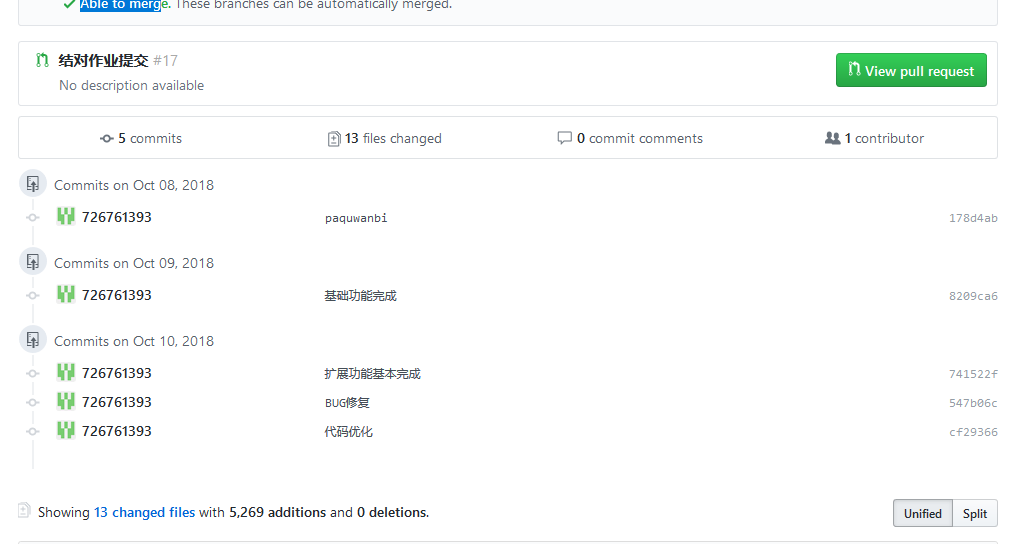
Github的代码签入记录
遇到的代码模块异常或结对困难及解决方法
- 一:原本我们两个作业一都是用C++写的,但由于种种原因(上面提到过了),我们选择了用JAVA写,其中很多语法,还有很多类似STL的那些工具我们之前根本没有接触过,只能临时去学习了一下。
- 二:时间不足,由于临近acm的比赛,有空闲的时间基本被抓去训练了,不像实验室里的其他同学,他们抱到了实验室外大腿,而我们两个都是实验室的成员,这就导致我们两个处境十分尴尬,两人互坑(哈哈),不过还是挤出了时间来完成基本的功能。
- 三:对于爬虫不够熟悉,导致我前期在爬取html出现错误后Debug时间过久,不过还好网上的教程够多,让我及时找到解决方法,具体在上面也提到过了。
评价你的队友
- 值得学习的地方:思维敏捷,学习能力强,可靠。
- 需要改进的地方:有点小拖延症
学习进度条
| 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时 | 重要成长 | |
| - | - | - | - | - |
| 第4周 | 300 | 300 | 5 | JAVA爬虫及语法学习 |
| 第5周 | 300 | 600 | 15 | JAVA爬虫及语法学习 |


