17秋 软件工程 结对项目 第二次作业
作业地址
结对成员
- 陈翔, 031502209;
- 李鸣, 031502316.
Github
- Deputy: Department-to-Student bidirectional selection;
- Deputy-generator:generate corresponding input JSON file for Deputy.
数据生成程序, Deputy-generator
一个生成的数据:input_data.json.
原理
程序主要由两大部分组成:
- class infoGenerator: 用于生成学生、部门的信息;
- class inputJsonGenerator: 用于将生成的学生、部门信息转换为JSON文件。
这里不针对如何将学生、部门信息转换为JSON文件做更多解释(jsoncpp足以处理),源码:inputJsonGenerator.cpp。
生成部门、学生信息的代码:infoGenerator.cpp,数据结构有:
- "string interest_tags[20]" 存放兴趣标签;
- "students student[310]" 结构体数组,存放生成的学生信息;
- "departments department[25]" 结构体数组,存放生成的部门信息。
主要由以下几类方法模块组成:
时间工具类模块:
static int generateWeekday()生成空闲时间段的星期数,如0代表星期日(Sun.),1代表星期一(Mon.)等等;static int generateStartTime()生成空闲时间段的起始时间,返回开始时间的分钟数,如8:00开始,返回480(mins);static int generateEndTime(int base)生成空闲时间段的结束时间,返回结束时间的分钟数,如21:00结束,返回1260(mins);static string generateTimeString(int weekday, int startTime, int EndTime)将星期数、空闲时间段开始时间(分钟数)、空闲时间段结束时间(分钟数)作为输入,生成对应的空闲时间段字符串,如输入"1, 960, 1080",返回Mon.16:00~18:00。
其他工具类模块:
static int generateTagHandle(int randomBase)用于随机选取一个兴趣标签,方法是随机生成某一个标签对应的index,通过"interest_tags[index]"获取对应标签;static int generateLimitation(int randomBase)随机生成部门人数限制,在[10, 15]范围内。
生成信息模块:
void infoGenerator::generateStudentInfo()生成300个学生信息;void infoGenerator::generateDepartmentInfo()生成20个部门信息。
生成学生信息的原理:
首先为300个学生生成除部门意愿外的所有基本信息:
- 按序生成学生学号(001-300);
- 对于每一个学生,生成总数在范围[2, 8]之间的空闲时间段,分布一周7天,每个空闲时间段不超过3个小时,空闲时间段开始时间在[480, 1260],即早上八点到晚上九点之间;避免一天之内的空闲时间段的重叠,方法是将之前的时间段作为约束来生成下一时间段;
- 随机选择兴趣标签数目,不作约束;
- 生成数量在范围[1, 5]之间的部门意愿数目。
接着生成部门意愿:
- 在[2, 4]之间生成热门部门数量n,并将拥有[0, n-1]部门编号的部门视作热门部门;
- 为热门部门分配权值10,为其余20-n个冷门部门分配权值4,计算随机数基值
y = 10*n+(20-n)*4; - 为每一个学生分配他的部门意愿:生成每一个部门意愿,首先都生成一个范围在[0, y-1]之间的随机数z,判断z是否在[0, 10*n-1]内(该意愿在热门部门中选取),如果是则选择第
z/10个部门;如果不是(该意愿在相对冷门部门中选取),选择第(z-(10*n-1))/4+n+1个部门,上述方法基于几何概率;此外,增加学生部门意愿判重,即避免了同一个学生在不同意愿中选择相同部门的情况,方法是记录先前意愿情况进行判断,如果重复则选择最临近的部门。
生成部门信息的原理:
为20个部门生成所有基本信息:
- 按序生成部门编号(01-20);
- 对于每一个部门,生成总数在范围[2, 5]之间的空闲时间段,分布一周7天,每个空闲时间段不超过3个小时,空闲时间段开始时间在[480, 1260],即早上八点到晚上九点之间;避免一天之内的空闲时间段的重叠,方法是将之前的时间段作为约束来生成下一时间段;
- 随机生成范围在[10, 15]之间的人员限制;
- 选择数目在[2, 5]之间的兴趣标签。
考虑因素
生成学生信息的原理基于我们平时参与部门的经验来进行判断:
- 1.一周之内可能用于部门的空闲时间段不超过8个,对部门活动失去耐心的阈值为3个小时;
- 2.多才多艺的人确实很多;
- 3.大部分人只会选择1-2个感兴趣的部门并参与面试,很少出现同时参与5个部门的情况(包括参与面试)。
生成部门信息的原理基于多次对某部门美女部长的采访:
- 1.一周之内部门的活动时间最多不超过5次,每一天的活动次数不超过2次,每一次的活动时间不超过3个小时;
- 2.部门的标签通常不超过5个,换言之,出现"多才多艺"的部门的情况很少;
- 3.部门的活动时间一般在早上8:00到晚上21:00之间开始。
此外,我们考虑了热门部门的情况:在20个部门中,总会有几个炙手可热的部门(比如数计文娱部,不要问我为什么),炙手可热体现在申请、填报它的人数非常多(校级部门有可能会超过100个人),因此我们决定对学生申请部门的意愿进行设定,提升热门部门被学生申请的概率。
匹配程序思路
学生部门双向选择的实现源码: matchAlgorithm.cpp。
步骤
(1)将学生分为两类,为有选志愿的和没选志愿的,有选志愿的进入步骤二,没有选择的学生表明没有任何想去的部门,不进入下述步骤。以下步骤中所述学生均有填报部门。
(2)遍历每一个学生,当前学生有1-5个部门志愿,以下两个子步骤的操作:
- 1.假设部门A是当前学生的第N志愿,将部门A的学生第N志愿数目+1并记录在二维数组2-1中;比如,学生会是同学甲的第一志愿,那么学生会的学生第一志愿数加一;
- 2.计算当前学生和当前部门的匹配值,匹配值越大表明学生与部门越匹配,否则越不匹配,记录在二维数组2-2中。该部分的详细描述见下文"部门与学生之间的匹配值计算"。
(3)首先阐述原理:如果一个部门很受欢迎,则很多学生很想选择该部门,且根据该部门的学生第N志愿数计算得到的受欢迎程度较高;比如文娱部很受欢迎,那么有很多男学生想选择它,并且它的学生第一/二志愿总数是比较高的,计算得到的受欢迎程度也是比较高的。此步骤根据上述原理及步骤二得到的二维数组2-1得到每一个部门的受欢迎程度,然后sort排序,得到部门之间的优先选择次序,越热门的部门越优先选择学生。
(4)按照步骤三计算得到的部门的优先选择顺序让部门依次选择学生,当前部门选择学生的方法是:对步骤二生成的300个学生与当前部门匹配值进行排序,匹配值最大的前limitation个学生加入该部门,其中limitation是当前部门的招生人数。
至此匹配算法结束。
部门与学生之间的匹配值计算
我们考虑了以下三个因素:
- 1.学生选该部门是第几个志愿,同时也要考虑学生一共有几个志愿,判断该部门在学生心中的权重(很想去 还是 想去);
- 2.学生兴趣标签和部门标签的匹配程度,部门在选择学生的时候可以根据兴趣标签判断某个学生是否对口;
- 3.学生的业余时间和部门固定活动时间的匹配程度。
我们通过以下方法,基于上述因素计算某一个部门与某一个学生的匹配值,匹配值越大表明学生与部门越匹配,否则越不匹配:
1.学生选该部门是第几个志愿,同时也要考虑学生一共有几个志愿,判断该部门在学生心中的权重(很想去 还是 想去):
显然越前面的志愿分值越高,学生选的志愿越少分值也会越高,同时为了使志愿之间的占比不是线性的(因为线性的区分度太低),这里就采用了取平方的方法。而学生志愿越少得分越高则想到了利用倒数的方法,而经过多次计算不同的值得到的结果,确定分子为2的时候,结果比较满意。计算公式如下:
value1 = (2/student_instance.applications_department_number)*(5-k)*(5-k)
其中student_instance.applications_department_number是学生的志愿总数,k表明该志愿是学生的第几志愿。
2.学生兴趣标签和部门标签的匹配程度,部门在选择学生的时候可以根据兴趣标签判断某个学生是否对口:
学生与部门标签的匹配度乘上某个数就是该部分的得分,而考虑了第一因素,发现第一因素的最高分为50,所以给第二因素的常量也为50。计算公式如下:
value2 = (match_tags/department_instance.tag_number)*50
其中match_tags是学生与部门标签的匹配的条数,department_instance.tag_number是部门的标签总数。
3.学生的业余时间和部门固定活动时间的匹配程度:
根据现实情况,学生的业余时间越多越好,这样部门能更好的管理部员,而这个因素不能占太多的比重,毕竟头两个因素才是重点,所以这个因素是用来当做附加分的,分值也不高,大概在5分左右。计算公式如下:
value3 = times*stu_weekday_num/dep_weekday_num
其中times是学生与部门的时间匹配数,stu_weekday_num是学生的课余时间总数,dep_weekday_num是部门的固定活动时间总数。
综上所述,我们根据三个因素的公式,计算得到部门与学生之间的匹配值value,公式如下:
value = value1+value2+value3
代码规范
本次项目统一使用Github进行源代码管理,两人统一使用Wasdns账号进行提交。我们在结对过程中遵循以下规范:
- 1.良好的注释习惯:对于每一个代码模块(一行或者多行,函数或者类)都进行详细的注释,保证队友能够理解;
- 2.参考"驼峰命名法"对变量进行命名,要求每一个变量的命名都是有意义的,且能够清楚地通过变量名了解该变量的作用;
- 3.进行异常的判断及处理。
代码佐证:
/*
* The following codes are used to:
*
* 1.update studentWishes to calculate the order among departments.
*
* 2.calculate studentDepValues(student vs department) to find out
* that if the student is matched against the department or not.
* And for the following codes(i.e.L79), the studentDepValues is
* used to help the department choose students.
*
*/
for (int i = 0; i < algorithmTool.eagerStudentNumber; i++) {
// current index of eagerStudents
int currentStudent = i;
// the total number of departments
// that chosen by the current student
int depTotal = algorithmTool.eagerStudent[currentStudent].applications_department_number;
// j: the number of departments
// k: the number of student wishes
// for each of the departments
for (int j = 0; j < 20; j++) {
int currentDepartment = j;
// the number of current department
string currentDepartment_str = department[currentDepartment].department_number;
// check if the department
// is the chosen one or not
for (int k = 0; k < depTotal; k++) {
// the k wish of current student
string kwish = algorithmTool.eagerStudent[currentStudent].applications_department[k];
// if matched, means that
// the student want this department
if (kwish == currentDepartment_str) {
// add 1 to studentWishes[department_number: currentDepartment][wishes: k]
algorithmTool.studentWishes[currentDepartment][k]++;
// calculate the value between current student
// and current department based on k
// (the current number of wishes), the student instance
// and the department instance
int stuDepValue = algorithmTool.matchedLevelValue(k, algorithmTool.eagerStudent[currentStudent], department[currentDepartment]);
assert(stuDepValue != -1);
// record the stuDepValue
// calculated by matchedLevelValue(...)
// in studentDepValues[student_instance_index][department_instance_index]
algorithmTool.studentDepValues[currentStudent][currentDepartment] = stuDepValue;
break;
}
}
}
}
结果评估
基于上文给出的Deputy-generator生成的数据:input_data.json,我们通过Deputy生成了结果:example_output.json,结果如下:
- 1.未匹配人数:190人,占比63%;
- 2.未匹配部门:2个,占比10%;
- 3.部门最多招纳人数:10人;
- 4.部门平均招纳人数:5.5人。
我们在测试中对上文"部门与学生之间的匹配值计算"中计算公式的权值进行了调整。上文方法在计算学生空闲时间段与部门活动时间段匹配中数时,使用了一个阈值a,即:当 "学生甲的空闲时间段I 与 部门活动时间段II 的交集时间 / 部门活动时间段II的总时间 >= a" 时,认为 学生甲的空闲时间段I 与 部门活动时间段II 匹配。我们分别使用了下面几个a值来进行测试:
| a | 未匹配人数占总人数比 | 未匹配部门占总部门比 |
|---|---|---|
| 0.4 | 43% | 0% |
| 0.5 | 56% | 1% |
| 0.6 | 63% | 2% |
| 0.7 | 70% | 2% |
综合考虑以下因素之后,我们认为现有的结果是可以接受的,理由如下:
- 1.实际中,部门要求部员全年参与部门活动的比例要高于70%,本程序选取a的比例为60%,接近该要求;
- 2.匹配的过程对"门当户对"进行了较高的要求:在学生选择部门时,我们认为其选择的部门意愿必定是其想去的部门,而且除了其部门意愿之外该学生对其余部门均兴趣不高,即使去了也是热情不高、浪费时间;在部门选择学生时,必然是选择其想要与其相对口的(如兴趣标签匹配情况)。在这样的条件下我们认为结果是合理的;
- 3.输入的文件具有一定的随机性。
结对感受
(1)结对感受:
陈翔:我能够深深体会到这两次结对的作业量,在多件事情并行的情况下国庆假期等于没放假了。这次结对,几天内近几k行的代码量,近百余次的Github项目管理记录(不算什么但是我觉得还是要列一下:D),和我鸣多次的电话讨论确定算法模型,见面敲定解决方案。虽然不是第一次和别人合作完成项目,但是本次结对依然获益颇多:一是收获了结对编程的经验,有旁边人实时code review的感觉还是很良好的,因为一个人的时候经常是这种情况:"写bug五分钟,debug两小时",在结对编程中就不会有这种情况的发生,避免了大量不必要时间的浪费,提高了整体效率,此外作为一个小团队也学习了一些团队协作的知识,比如编码规范,模块对接等等;二是充实(填满)了整个假期,提升了整体的编码水平,巩固了(再一次预习了)C++的知识,让我了解到很多Linux下编译、编程的知识以及之前未曾涉及到的JSON的解析方法;三是在结对过程中与我鸣多次交流结下了深厚(?)的友谊,虽然不时会被他和他的小可爱虐一脸,可是他幽默风趣、细心可爱、阳光帅气、有担当负责任,是一个不可多得的好搭档,编码过程中思路清晰,纠正了我不少的问题。
我对于我鸣的建议有以下两点:
- 1.编码过程中要时刻注意写注释和代码规范,变量命名时要合理清晰;
- 2.Github commit的习惯,当你上手学会了Github之后,它会是一个非常棒的工具;
3.好好珍惜女朋友,工作的时候女朋友的电话还是要接的。
李鸣:这次结对作业,刚好我和我翔(队友)都是莆田人,所以就算是国庆放假也能够面基结对,整个国庆我们面基了5次,同时还语音结对了3次,可以说是整个国庆都是在结对中度过了,基本上也没消停过,说实话是很难受,毕竟是今年的最后一个法定节假日。但是,在和我翔的结对中也不乏乐趣,经我翔介绍发现了一家很有情趣的咖啡馆,听我翔说买上一杯咖啡可以在这度过一个下午,结对的过程中有让我印象最深的就是我翔的代码规范,真的做的很好,比起我的一团糟代码简直天差地别,这也让我明白了代码规范的重要性,在作业刚开始的时候我翔就自己做好了输入输出的工作,而我的工作主要就是想如何匹配,其他的部分则是我们一起思考,敲代码弄好的,这过程中也发现了结对带来的一个好处就是,敲代码的人头脑可能不会那么清晰,有时候一些小错误发现不了,而一旁的队友一般都会很容易发现这种小错误,节省了很多的时间。总得来说,这次结对是一次不错的体验,唯一的代价估计就是少了个国庆。
番外,注:以下内容与作业无关,可跳过。
工作环境
由于都是同一个地方的人,于是乎在国庆假期面对面编程了3次、电话对接了3次,地点分别在诺丁咖啡馆和麦当劳,这里贴咖啡馆的图(麦当劳的图就不贴了。。)。
我鸣:

近10年的留言墙,便利贴、留言贴满了天花板、墙壁:

店里的黑猫,总是能带来好运:

店内一角:

平时有回家的时候,下午都会花上一杯咖啡钱呆在这里。
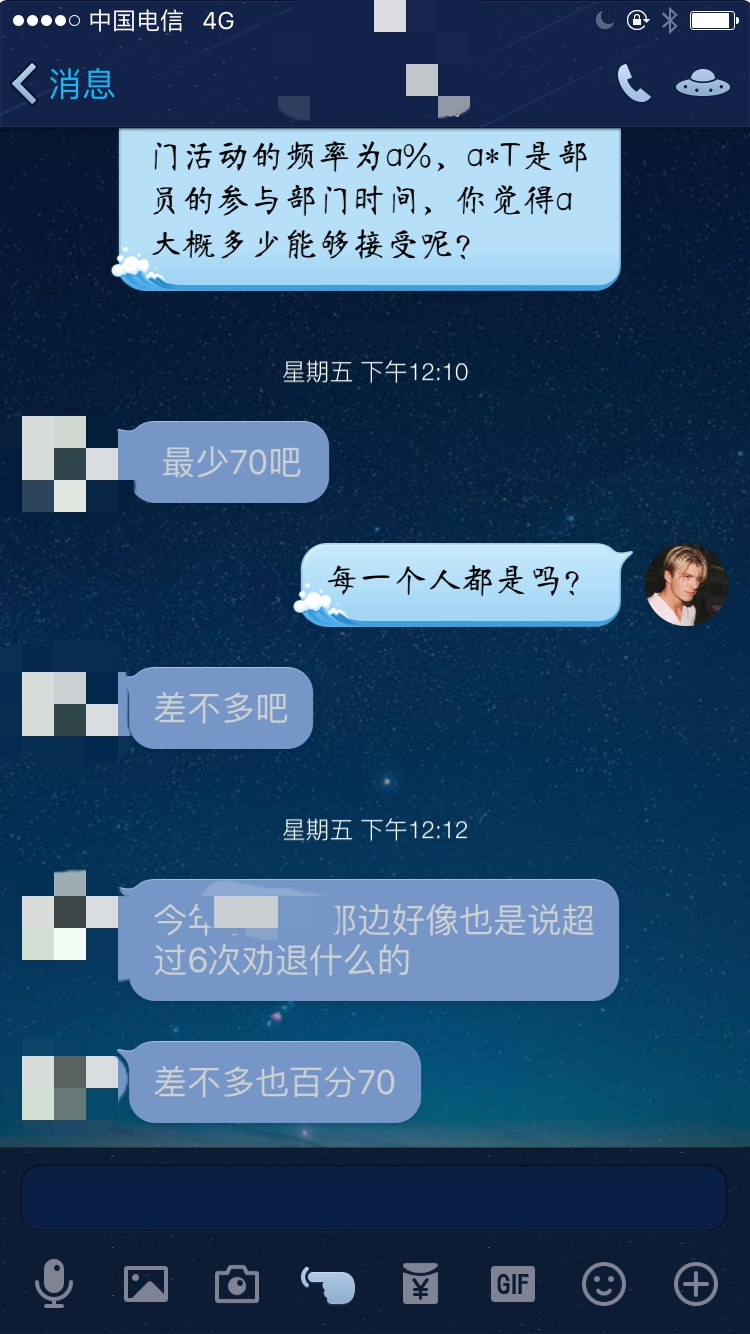
采访
对某部门部长的采访截图:
2017.10


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
2016-10-08 简单排序算法 C++类实现