
数据库—Mysql
今天跟大家来聊聊Mysql,首先介绍一下它的历史:
Mysql是一个关系型数据库管理系统,最先由瑞典的MySQL AB公司开发,后来被sun公司收购,后因sun公司又被Oracle公司收购,致使MySQL现在成为Oracle旗下产品,MySQL数据库现在被业界广泛使用。
使用方法和案列:
1) MySQL的部署结构
MySQL分别部署在服务器端和客户端软件上,服务器端负责存储和维护数据,而客户端负责向服务器端发起命令请求。
2) 安装和使用MySQL数据库
在这里推荐大家使用xampp,它是一个功能强大的建站集成软件包,可以在Windows、Linux、Solaris、Mac OS X等多种操作系统下安装使用,并且支持多种语言。在百度上就可以下载,不是很大,默认安装在C盘就好,不会占用多少空间的,接下来就是MySQL的使用了。
首先打开xampp,开启Mysql服务器,默认端口3306,如图:
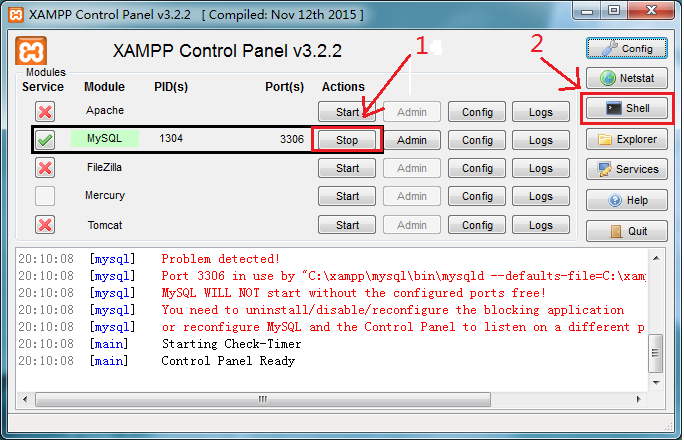
红色1箭头所指打开服务器端口,然后点击红色2箭头所指打开客户端命令行界面,这里我们一般打开两个,方便后面运行方便。
打开后界面如图所示:
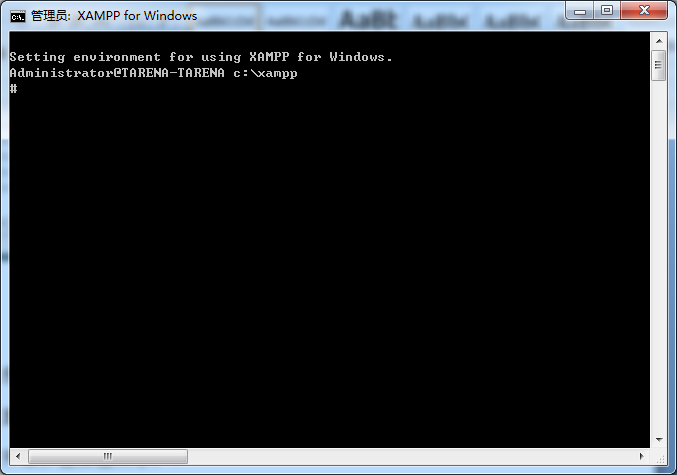
输入:mysql.exe -h127.0.0.1 –P3306 –uroot –p
在这里,可以简写为mysql –uroot 直接进入,切记不要在最后输入分号,虽然也可以进去,但是此时你进入的身份就会变为客人身份而不是超级管理员身份。
接来下介绍一些常用的MySQL管理命令:
quit; 退出
show databases; 显示服务器上所有数据库
use+数据库名; 进入指定的数据库
show+tables ; 显示当前数据库所有的表格
desc+表名; 描述表中有哪些列(表头)
大家应该注意到这些语句的后面都添加了分号(英文状态下),没错,就是要添加的,不然你运行不了。
插一下SQL语法规范:
A) 每条语句必须以英文分号结尾,一条语句可以跨域多行,见到分号认为语句结束。
B) 若第N条语句语法错误,则此语句以及后续的所有语句都不再执行。
C) SQL命令不区分大小写。习惯上数据库关键字都用大写,非关键字都小写。
再下面给大家说一下Mysql常用SQL命令(SQL:Structured Query Language,结构化查询语言,用于操作关系型数据库服务器中的数据),SQL语言最早由IBM提出,后提交给ISO最终成为了数据库行业的标准语言,分为多个版本:SQL-87、SQL-92、SQL-99等,当前标准的SQL命令可以被绝大部分关系型数据库所支持。
SQL语句的两种执行方式:
1) 交互模式:客户端输入一行,点击回车,服务器执行一行,适合临时性的查看数据。
2) 脚本模式:客户端把多行要执行的命令编写在一个文本文件中,一次提交给服务器执行。适用于批量的增删改查数据。
提交方式:mysql –uroot < 路径 回车 (路径太长可以直接把文件拖进去)
下面是SQL语句中最常用的增删改查,例子:创建班级数据库class 班级数据库里有student 表,表里有表头(sid SMALLINT,sname VARCHAR,sex CHAR,sage TINYINT,score FLOAT),通过SQL语句插入若干学生记录。因为要写的语句蛮多,这里我们将SQL两种执行方式结合使用,首先在电脑任意位置新建demo.sql (这里可以先建一个文本文档,然后将其扩展名改为.sql),这里值得注意的是这个文件的路径一定要是英文路径,不要出现中文或者空格,否则将会运行出错。然后将其拖进EditPlus(一款很好用的编辑器,网上直接下载即可,2M大小),接下来写SQL脚本文件,如图:
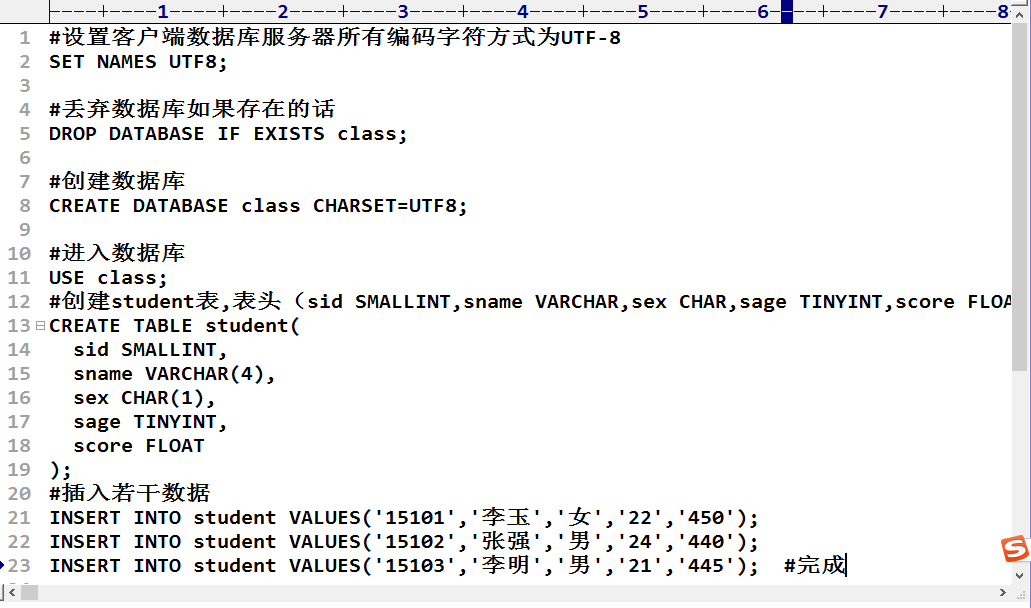
写完后通过打开命令行(shell)窗口执行,之前说过一次性打开两个方便我们执行,如图:

没有报错,切入第二个窗口开始进行交互模式 如图:
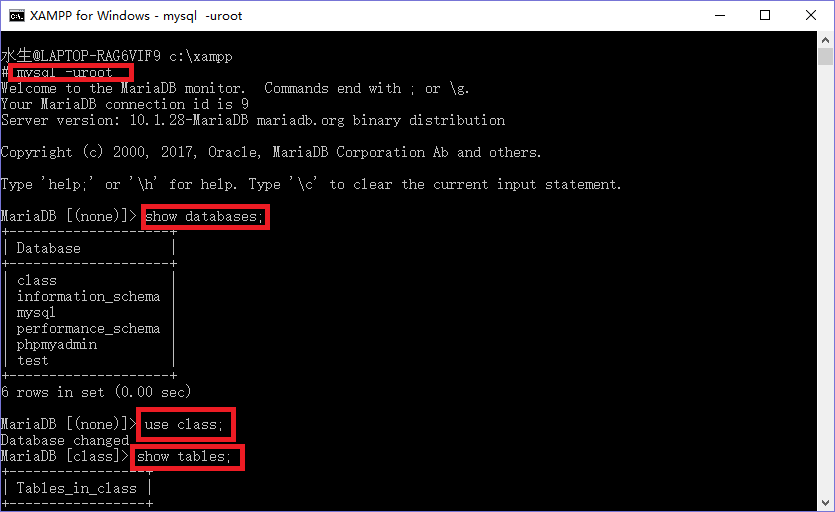

成功!
这里再提一下我们之前用的命令操作:
mysql -uroot 以管理员身份进入客户端数据库
show databases; 显示当前服务器中的所有数据库
use + 数据库名 ; 进入该数据库
show tables ; 显示当前数据库中的所有表
select * from + 表名 查询此表中所有列的记录
接下来我们来修改表中的数据:我们将student 表中的李明的分数改为480 如图:
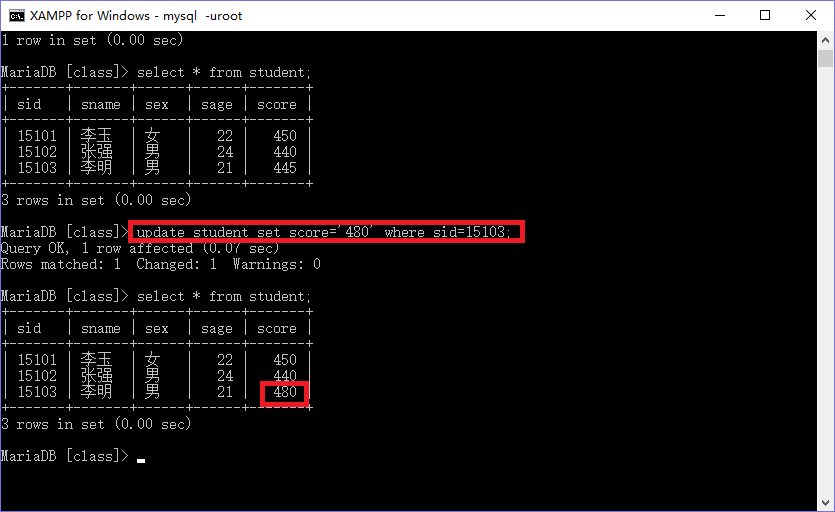
我们可以看到更改成功。
接下来我们再删除名字叫张强学生的记录如图:
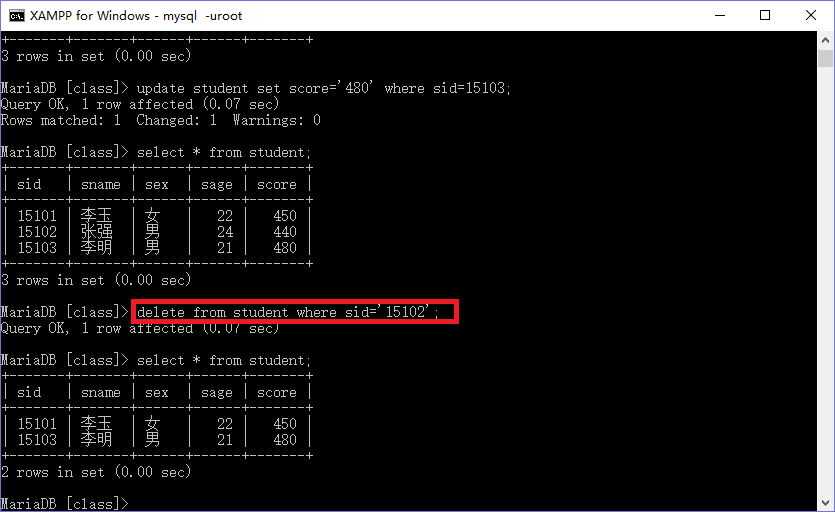
我们可以看到成功删除数据。
今天说的只是Mysql的一点点知识和一些基本的操作,日后我会继续更新,尽请期待,希望对您有用。 date:12/4
————————————————————————————分割线—————————————————————————————
今天和大家说说数据库的乱码问题、常用数据类型和列约束。
首先说说乱码问题,如图:
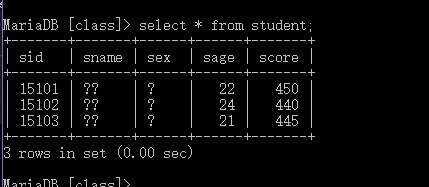
可以看到图中sname 和 sex 列的数据都出现了乱码,这是为什么呢?
要解决这个问题,我们得先弄清楚计算机是怎样存储字符的,大家都知道,电脑是美国人发明的,所以电脑问世的时候美国人只发明了针对储存英文的一套储存标准,就是我们熟知的ASCLL,它对所有的英文字符以及标点符号都进行了编码。但是随着电脑在其他国家的普及,各国制定了本国的编码方式,这就导致乱码产生,乱码的本质是:存储字符数据和读取字符数据所用的编码方案不一致。后来国际标准委员会为解决这一问题,制定了一套统一标准Unicode:对世界上主流语言的常用字符进行了编码,兼容ASCII,具体存储是可以采用UTF-8、UTF-16、UTF-32等存储方案。
所以要解决Mysql数据库中的乱码问题需要做到“三个统一”
1)SQL脚本文件另存为所用的编码
2)客户端连接服务器所用的编码
3)数据库本身存储数据用的编码
所以当我们在编写数据库脚本语言的时候首先要申明编码方式为UTF-8,同时在创建数据库的时候也要设定编码方式,如图:


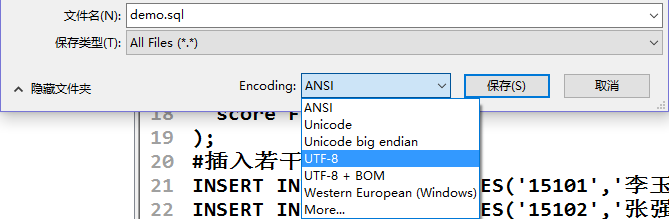
另外Mysql脚本文件的保存方式也应改为UTF-8。如图:
OK,下面我们来谈谈数据库保存数据的常用数据类型,
1.数值类型
TINYINT:微整数,占用1个字节,-128~127
SMALLINT:小整数,占用2个字节,-32768~32767
INT:整数:占用4个字节,-2147483648~2147483647
BIGINT(M,D):大整数,占用8个字节
FLOAT(M,D):单精度浮点小数,占用4个字节,3.4E38,范围远大于INT,但精度不如INT
DOUBLE(M,D):双精度浮点小数,占用8个字节,1.79E308,范围远大于BIGINT,但精度不如BIGINT,可能产生极端误差。
DECIMAL(M,D):定点小数,不会产生计算舍入误差。M代表总有效位数,D代表小数点后面允许有效位数。
BOOL:布尔类型,只能取值为:TRUE、FALSE
2.时间类型—必须用单引号
DATE:日期类型
TIME:时间类型
DATETIME:日期时间类型
3.字符串类型—必须用单引号
CHAR(M):定长字符串,可能产生空间浪费问题,操作速度快,M不能超过255.
VARCHAR(M):变长字符串,M不能超过65535,不会产生空间浪费问题。操作速度慢
TEXT(M):大型变长字符串,,M不能超过2G
各种类型结合实际使用。
今天的最后我们来说说列约束
约束就是Mysql 可以对插入表中的数据进行特定的检验,但只有满足条件的数据才能插入成功。
a)主键约束—— PRIMARY KEY
申明为主键的列上不能插入重复的值,也不能插入NULL值。表中的记录会自动按照主键列上的值由小到大排列。一个表只能有一个主键。
案列写法如图:

直接在要约束的类型后面写就OK。
b)唯一约束——UNIQUE
声明了唯一约束的列上不能插入重复的值,但可以插入NULL值,NULL可以是多个。
其写法和主键约束一样,在要约束的列的数据类型后直接添加即可。
c)非空约束—— NOT NULL
声明了非空约束的列上不能插入NULL值,但可以重复。
例如用户填入密码时不能为空,但是不同的用户可以有相同的密码。
不知道你们可想到了PRIMARY KEY 和 UNIQUE NOT NULL 效果是一样的了,但是它俩之间也是有区别的PRIMARY KEY 和 UNIQUR NOT NULL 的区别,前者会自动排序,而后者不会排序,前者在一个表内只能出现一次,后者可以出现多次。
今天就更新到这里,后期我将不停期更新,如果对您有用,请点个赞喔~谢谢 date:12/5
————————————————————————————分割线—————————————————————————————
昨天更新完今天发现没有说完,尴尬,今天先接着补充一下昨天的列约束。
d)默认值约束——DEFAULT:
可以使用DEFAULT 关键字为声明默认值,有两种方法可以应用到默认值
第一种:
INSERT INTO +表名 VALUES(
10,'联想',DEFAULT
);
第一种:
INSERT INTO +表名(fid,fname) VALUES(
10,'联想',DEFAULT
);
e)检查约束:CHECK—MySQL不支持(它会降低插入和更新的效率),检查约束可以对输入的数据范围进行检验。
示例:CREATE TABLE stu(age TINYINT CHECK(age>=18 AND age<=60));
这个约束用的比较少,原因就是会降低插入和更新的效率,所以不推荐使用。
f)外键约束——FOREIGN KEY
声明了外键约束的列,取值必须在另一个表的主键列上出现过。可以出现重复值或者NULL。
FOREIGN KEY(取值表) REFERENCES 表名(对照列)
这个外键在创建表单时用的还是比较多的,大家可以注意一下。
接下来跟大家重点谈谈SQL中的查询,在这之前,我得先统一一下我们接下来需要做示例查询的表,如图所示:
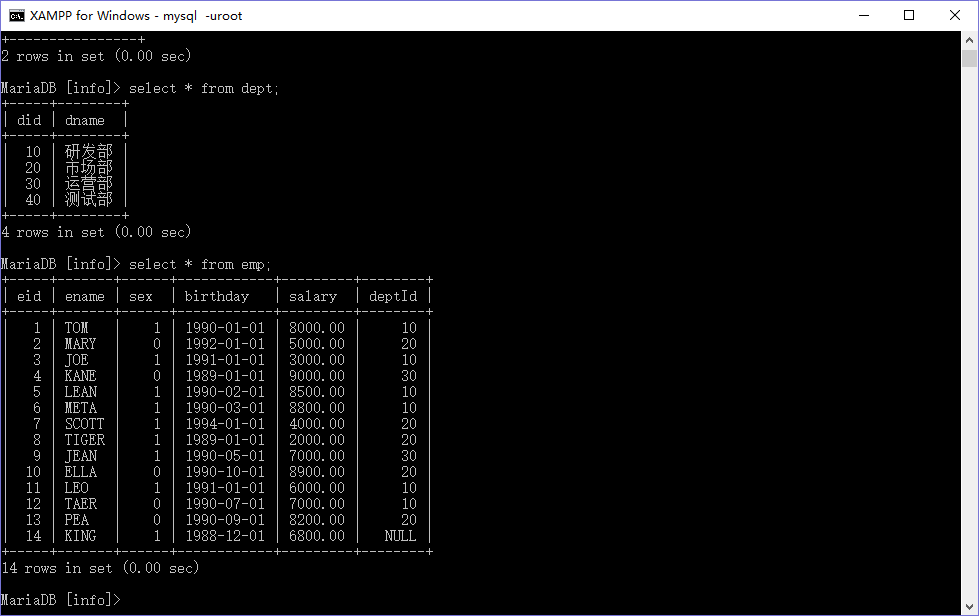
两张表如图所示,一张部门表(dept),一张员工信息表(emp),这个数据库我百度云分享给大家,方便大家练习,链接:https://pan.baidu.com/s/1jIw2YV0 密码:1wkw
数据库部署进入就是之前脚本模式方法,截个图给大家看一下

没有报错就OK,进去数据库的方式我就不说了,前面也有具体说明的。
OK,进入正题,首先是简单查询,在此声明一下,我不会每条查询都截图给大家看,我挑一些重点的,大家看我查询语句自己在自己的电脑里运行多练练就OK,下面的这些语句基本满足了我们的工作和日常需求,全是干货。
示例:查询有所员工的姓名、工资、生日
SELECT ename,salary,birthday FROM emp;
给列取别名:查询所有员工的姓名和工资,列名用汉字显示
SELECT ename AS 姓名,salary AS 工资 FROM emp; 这里的AS可以省略不写
效果图:

只显示不同的值/合并相同的值
查询哪些部门下有员工
SELECT DISTINCT deptId FROM emp;
查询公司有哪些性别的员工
SELECT DISTINCT sex FROM emp;
查询时执行计算
查询所有员工的年薪
SELECT salary AS 月薪,salary*12 AS 年薪 FROM emp;
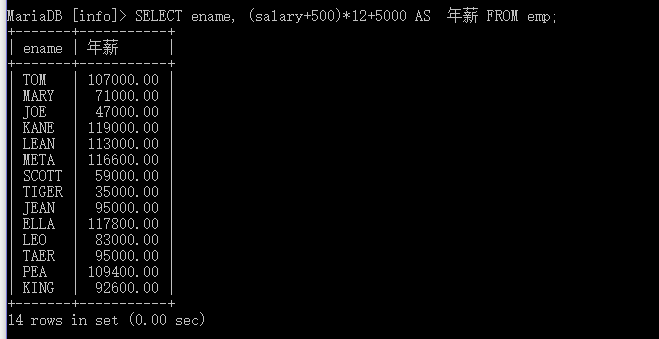
假设每个员工月薪+500,年终每人再给5000年终奖,查询每一个员工的总收入。
SELECT ename, (salary+500)*12+5000 AS 年薪 FROM emp;
查询结果的排序
查询出所有的员工信息,结果按工资由低到高排序
SELECT * FROM emp ORDER BY salary(desc); #descendant
查询所有的员工信息,按年龄由大到小排序
SELECT * FROM emp ORDER BY birthday;(升)
查询所有的员工信息,按年龄由小到大排序
SELECT * FROM emp ORDER BY birthday desc;(降)
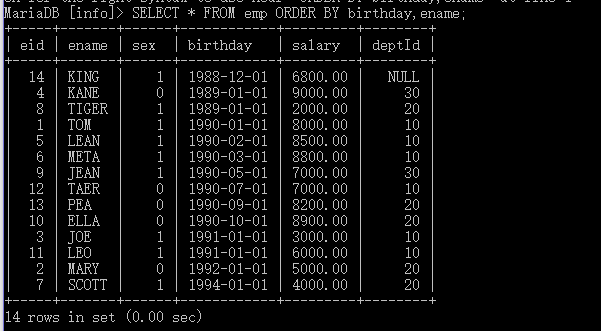
查询所有的员工信息,按生日由小到大排列,若生日相同,再按姓名由小到大排列
SELECT * FROM emp ORDER BY birthday,ename;
查询所有的员工信息,按工资由大到小排列,要求所有女员工必须排在男员工前面
SELECT * FROM emp ORDER BY sex ASC,salary DESC;
条件查询/查询结果集的过滤/筛选
查询出工资大于等于6000的员工的所有信息
SELECT * FROM emp WHERE salary>=6000;
查询出生在1990年之前员工信息
SELECT * FROM emp WHERE birthday<'1990-01-01';
查询出不在10号部门的员工的信息
SELECT * FROM emp WHERE deptId!=10;
AND(并且) OR(或者)
查询出在10号和30号部门的员工的所有信息
SELECT * FROM emp WHERE deptId=10 OR deptId=30;
查询出工资在6000-8000之间的员工的所有信息
SELECT * FROM emp WHERE salary>=6000 AND salary<=8000;
SELECT * FROM emp WHERE salary BETWEEN 6000 AND 8000;
模糊条件查询/模糊匹配查询: "%" 可以匹配任意多个任意字符 " _" 可以匹配任意一个任意字符,两个符号不能与=连用,只能用LIKE连用
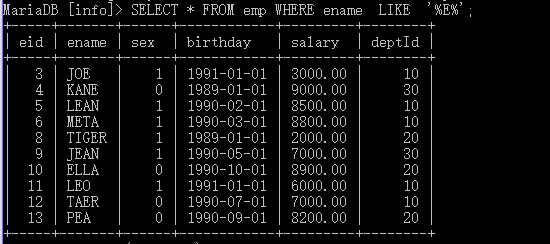
查询出所有姓名中包含字符E的员工信息
SELECT * FROM emp WHERE ename LIKE '%E%';
查询姓名中第二个字符是E的员工信息
SELECT * FROM emp WHERE ename LIKE '_E%';

分页查询—小难点哦
分页显示:若查询结果集中有太多的记录行,一次显示不完,可以一页一页的显示。分页显示的语句在不同的数据库中实现方法不同,MySQL最简单的。语法:
SELECT ……
FROM ……
WHERE……
ORDER BY ……
LIMIT start(一个数字,指定从结果集中的哪行记录开始读取,默认第一行为第0行),count(指定此次读取的最多行数);
示例:分页查询所有员工信息,假设每页最多显示6条记录,查询出第一页
SELECT * FROM emp LIMIT 0,6;
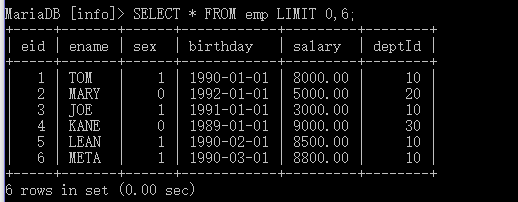
以上就是我整理出来的经常会用到的查询,大家可以对照着我的查询语句练习,我不建议直接复制我的查询语句,因为只有自己练了并思考了才会印象深刻,明天我会继续更新完SQL查询语句复杂部分。谢谢观看,如果对您有用,别忘了点个赞哦~或者有什么不足,欢迎指出。date:12.6
————————————————————————————分割线—————————————————————————————
昨天给大家整理了一些简单的SQL查询语句,今天我想给大家说一些SQL比较复杂但很实用的语句,说复杂其实也不复杂,把前面的语句练熟练了,后面也就很好掌握了。
用来查询的表还是昨天的,没有下载的链接还在那,大家可以去下载一份。
聚合查询/分组查询
MySQL提供了5个函数:COUNT()/SUM()/AVG()/MAX()/MIN() PS:函数:function,功能体,接受若干原始数据,最终导出特定的计算结果。
示例:查询出所有员工的总数量
SELECT COUNT(eid) FROM emp;
SELECT COUNT(*) FROM emp;推荐
查询出10号部门员工的总工资
SELECT SUM(salary) FROM emp WHERE deptId=10;
查询出女员工的平均工资
SELECT AVG(salary) FROM emp WHERE sex=0;
查询出1990年生日的员工工资最大值和最小值
SELECT MAX(salary) FROM emp WHERE YAER(birthday)='1990';
SELECT MIX(salary) FROM emp WHERE YAER(birthday)='1990'; 补充:year(…)/month(…) 获取指定年龄和月份
查询每一个部门的员工数量
SELECT deptId,COUNT(*) FROM emp GROUP BY deptId;
查询出每个部门中的平均工资、最大工资、最小工资
SELECT deptId,AVG(salary),MAX(salary),MIN(salary) FROM emp GROUP BY deptId;
按性别分组,查询出男女员工的人数
SELECT sex,COUNT(*) FROM emp GROUP BY sex;
子查询
示例:查询“研发部”所有员工的信息
步骤1:查询“研发部”的部门编号,假设结果为10
SELECT did FROM dept WHERE dname=’研发部’;—子查询
步骤2:查询部门编号为10的员工所有信息
SELECT * FROM emp WHERE deptId =10;—父查询
综合两句:SELECT * FORM emp WHERE deptId=(SELECT did FROM dept WHERE dname=’研发部’);
这里大家一定要多看看,理解透~
查询出工资比TOM高的员工的所有信息
SELECT * FROM emp WHERE salary>( SELECT salary FROM emp WHERE ename=’TOM’);
查询出工资低于全部员工平均工资的员工的信息
SELECT * FROM emp WHERE salary<(SELECT AVG(salary) FROM emp);
查询出于TOM同一年生日的员工的信息
SELECT * FROM emp WHERE YEAR(birthday)=(SELECT YEAR(birthday) FROM emp WHERE ename=’TOM‘) ORDER BY sex;
跨表查询/多表查询
示例:查询所有员工姓名及其所在部门的名称
SELECT ename,dname FROM emp,dept; 错误写法,出现“笛卡尔积”
注意:跨表查询必须防止“笛卡尔积”
SQL-92写法:SELECT ename,dname FROM emp,dept WHERE emp.deptId=dept.did;
无法显示在对方表中没有记录的记录。
SQL-99写法—四种:
内连接 INNER JOIN…ON (与SQL-92效果一样)
SELECT ename,dname FROM emp INNER JOIN dept ON deptId=did;
左外连接 LEFT OUTER JOIN
SELECT ename,dname FROM emp LEFT OUTER JOIN dept ON deptId=did;
作用:显示出“左侧表”中所有的记录,即使右侧表中没有对应的记录。
右内连接 RIGHT OUTER JOIN
SELECT ename,dname FROM emp RIGHT OUTER JOIN dept ON deptId=did;
作用:显示出“右侧表”中所有的记录,即使左侧表中没有对应的记录。
全连接 FULL JOIN —显示左侧表/右侧表中所有的记录。—MySQL不支持MySQL中不支持全连接的解决方案:UNION/UNION ALL 两个查询语句的结果集的合并,可以使用UNION关键字
(集合) UNION (集合) #合并相同项
(集合) UNION ALL (集合) #不合并相同项
使用UNION 查询出所有的员工姓名/部门名称,显示所有的员工和所有的部门。
(SELECT ename,dname FROM emp LEFT OUTER JOIN dept ON deptId=did ) UNION (SELECT ename,dname FROM emp RIGHT OUTER JOIN dept ON deptId=did );
————————————————————————————————————————————————————————————————————————————-
至此我理解的MySQL就是这些了,今天更新完了最后一部分,希望大家多多练习,相信会对你们有所帮助,觉得可以的话就点个支持哦,谢谢~date:12.7


