

开源项目IPProxys的使用
前几天看了一下github上,IPProxys开源项目(https://github.com/qiyeboy/IPProxys)快100star了,看来大家对这个项目还是比较感兴趣的。最近一直没更新文章,主要是忙实验室的工作和写一个之前给大家提到新的开源项目,我将它命名为PowerProxy,写的过程中遇到了很多问题,算是一个不错的学习经历,对sock5协议,windows内核有了一定的理解。开源的日期还没确定,需要将一些关键问题解决,大家敬请期待。
看到大家对IPProxys项目挺感兴趣,下面就介绍一下它的使用方式。(我的新书《Python爬虫开发与项目实战》出版了,大家可以看一下样章)
IPProxys使用
项目依赖
ubuntu,debian下
-
安装sqlite数据库: apt-get install sqlite sqlite3
-
安装requests库: pip install requests
-
安装lxml: apt-get install python-lxml
windows下
-
下载sqlite,路径添加到环境变量
-
安装requests库: pip install requests
-
安装lxml: pip install lxml或者下载lxml windows版
如何使用
-
将项目目录clone到当前文件夹
$ git clone
-
切换工程目录
$ cd IPProxys
-
运行脚本
python IPProxys.py
API 使用方法
模式
GET /
参数
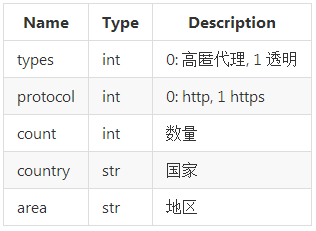
例子
IPProxys默认端口为8000
如果是在本机上测试:
-
获取5个ip地址在中国的高匿代理:http://127.0.0.1:8000/?types=0&count=5&country=中国
-
响应为JSON格式,按照响应速度由高到低,返回数据:
[{"ip": "220.160.22.115", "port": 80}, {"ip": "183.129.151.130", "port": 80}, {"ip": "59.52.243.88", "port": 80}, {"ip": "112.228.35.24", "port": 8888}, {"ip": "106.75.176.4", "port": 80}]
示例代码:
import requests import json r = requests.get('http://127.0.0.1:8000/?types=0&count=5&country=中国') ip_ports = json.loads(r.text) print ip_ports ip = ip_ports[0]['ip'] port = ip_ports[0]['port'] proxies={ 'http':'http://%s:%s'%(ip,port), 'https':'http://%s:%s'%(ip,port) } r = requests.get('http://ip.chinaz.com/',proxies=proxies) r.encoding='utf-8' print r.text
TODO
-
可自主选择添加squid反向代理服务器,简化爬虫配置
-
重构HTTP API接口
-
增加更多代理网站和数据库适配

