Flume学习之路 (一)Flume的基础介绍
一、背景
Hadoop业务的整体开发流程:
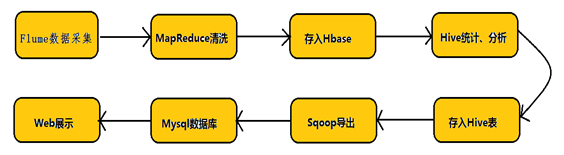
从Hadoop的业务开发流程图中可以看出,在大数据的业务处理过程中,对于数据的采集是十分重要的一步,也是不可避免的一步.
许多公司的平台每天会产生大量的日志(一般为流式数据,如,搜索引擎的pv,查询等),处理这些日志需要特定的日志系统,一般而言,这些系统需要具有以下特征:
(1) 构建应用系统和分析系统的桥梁,并将它们之间的关联解耦;
(2) 支持近实时的在线分析系统和类似于Hadoop之类的离线分析系统;
(3) 具有高可扩展性。即:当数据量增加时,可以通过增加节点进行水平扩展。
开源的日志系统,包括facebook的scribe,apache的chukwa,linkedin的kafka和cloudera的flume等。
二、Flume的简介
flume 作为 cloudera 开发的实时日志收集系统,受到了业界的认可与广泛应用。Flume 初始的发行版本目前被统称为 Flume OG(original generation),属于 cloudera。
但随着 FLume 功能的扩展,Flume OG 代码工程臃肿、核心组件设计不合理、核心配置不标准等缺点暴露出来,尤其是在 Flume OG 的最后一个发行版本 0.9.4. 中,日
志传输不稳定的现象尤为严重,为了解决这些问题,2011 年 10 月 22 号,cloudera 完成了 Flume-728,对 Flume 进行了里程碑式的改动:重构核心组件、核心配置以
及代码架构,重构后的版本统称为 Flume NG(next generation);改动的另一原因是将 Flume 纳入 apache 旗下,cloudera Flume 改名为 Apache Flume。
Flume是Apache的顶级项目,官方网站:http://flume.apache.org/
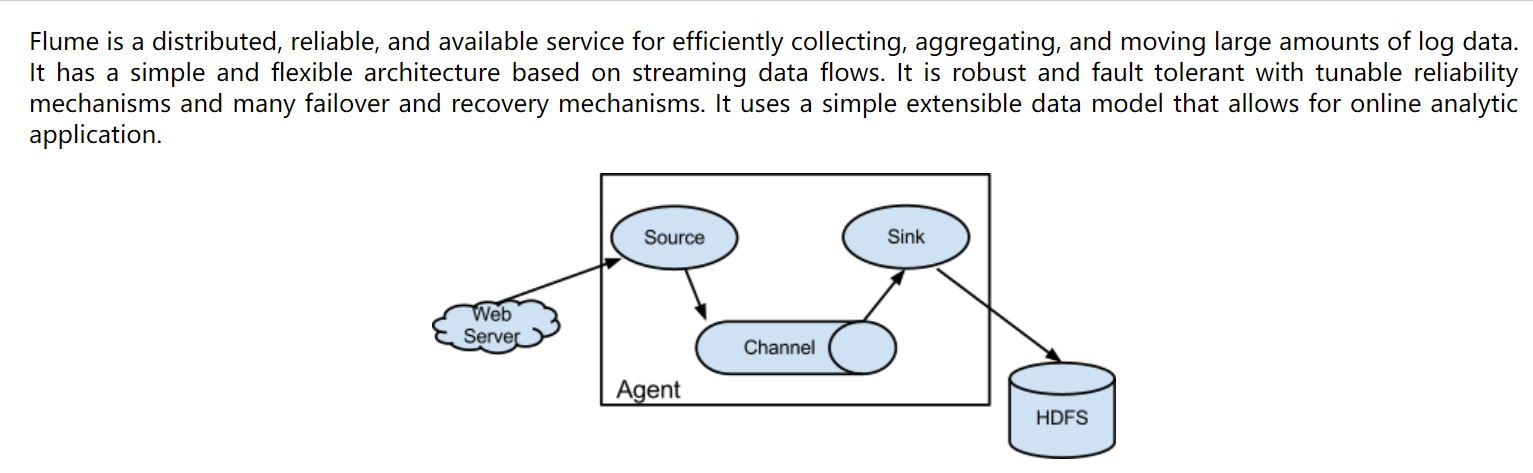
Flume是一个分布式、可靠、高可用的海量日志聚合系统,支持在系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据的简单处理,并写到各种数据接收方的能力。
Flume 在0.9.x and 1.x之间有较大的架构调整,1.x版本之后的改称Flume NG,0.9.x的称为Flume OG。
Flume目前只有Linux系统的启动脚本,没有Windows环境的启动脚本。
三、Flume NG的介绍
3.1 Flume特点
flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(比如文本、HDFS、Hbase等)的能力 。
flume的数据流由事件(Event)贯穿始终。事件是Flume的基本数据单位,它携带日志数据(字节数组形式)并且携带有头信息,这些Event由Agent外部的Source生成,当Source捕获事件后会进行特定的格式化,然后Source会把事件推入(单个或多个)Channel中。你可以把Channel看作是一个缓冲区,它将保存事件直到Sink处理完该事件。Sink负责持久化日志或者把事件推向另一个Source。
(1)flume的可靠性
当节点出现故障时,日志能够被传送到其他节点上而不会丢失。Flume提供了三种级别的可靠性保障,从强到弱依次分别为:end-to-end(收到数据agent首先将event写到磁盘上,当数据传送成功后,再删除;如果数据发送失败,可以重新发送。),Store on failure(这也是scribe采用的策略,当数据接收方crash时,将数据写到本地,待恢复后,继续发送),Besteffort(数据发送到接收方后,不会进行确认)。
(2)flume的可恢复性
还是靠Channel。推荐使用FileChannel,事件持久化在本地文件系统里(性能较差)。
3.2 Flume的一些核心概念
Client:Client生产数据,运行在一个独立的线程。
Event: 一个数据单元,消息头和消息体组成。(Events可以是日志记录、 avro 对象等。)
Flow: Event从源点到达目的点的迁移的抽象。
Agent: 一个独立的Flume进程,包含组件Source、 Channel、 Sink。(Agent使用JVM 运行Flume。每台机器运行一个agent,但是可以在一个agent中包含
多个sources和sinks。)
Source: 数据收集组件。(source从Client收集数据,传递给Channel)
Channel: 中转Event的一个临时存储,保存由Source组件传递过来的Event。(Channel连接 sources 和 sinks ,这个有点像一个队列。)
Sink: 从Channel中读取并移除Event, 将Event传递到FlowPipeline中的下一个Agent(如果有的话)(Sink从Channel收集数据,运行在一个独立线程。)
3.3 Flume NG的体系结构
Flume 运行的核心是 Agent。Flume以agent为最小的独立运行单位。一个agent就是一个JVM。它是一个完整的数据收集工具,含有三个核心组件,分别是
source、 channel、 sink。通过这些组件, Event 可以从一个地方流向另一个地方,如下图所示。
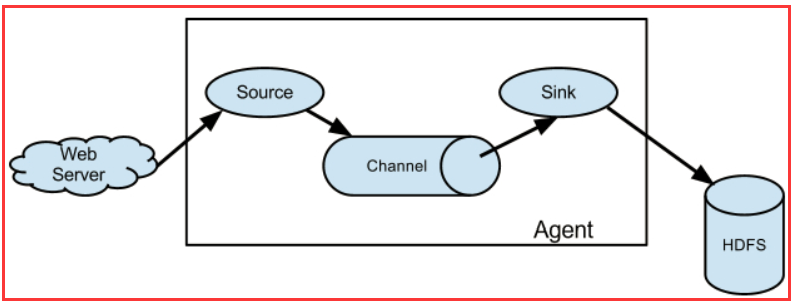
3.4 Source
Source是数据的收集端,负责将数据捕获后进行特殊的格式化,将数据封装到事件(event) 里,然后将事件推入Channel中。
Flume提供了各种source的实现,包括Avro Source、Exce Source、Spooling Directory Source、NetCat Source、Syslog Source、Syslog TCP Source、Syslog UDP Source、HTTP Source、HDFS Source,etc。如果内置的Source无法满足需要, Flume还支持自定义Source。
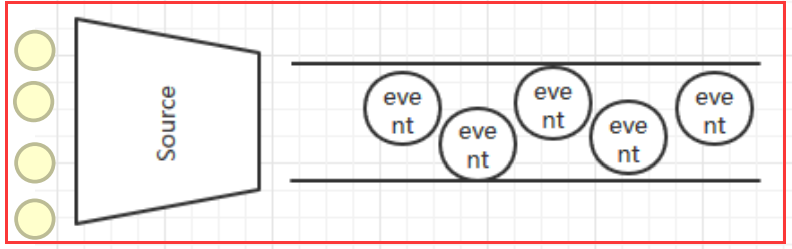
3.5 Channel
Channel是连接Source和Sink的组件,大家可以将它看做一个数据的缓冲区(数据队列),它可以将事件暂存到内存中也可以持久化到本地磁盘上, 直到Sink处理完该事件。
Flume对于Channel,则提供了Memory Channel、JDBC Chanel、File Channel,etc。
MemoryChannel可以实现高速的吞吐,但是无法保证数据的完整性。
MemoryRecoverChannel在官方文档的建议上已经建义使用FileChannel来替换。
FileChannel保证数据的完整性与一致性。在具体配置不现的FileChannel时,建议FileChannel设置的目录和程序日志文件保存的目录设成不同的磁盘,以便提高效率。
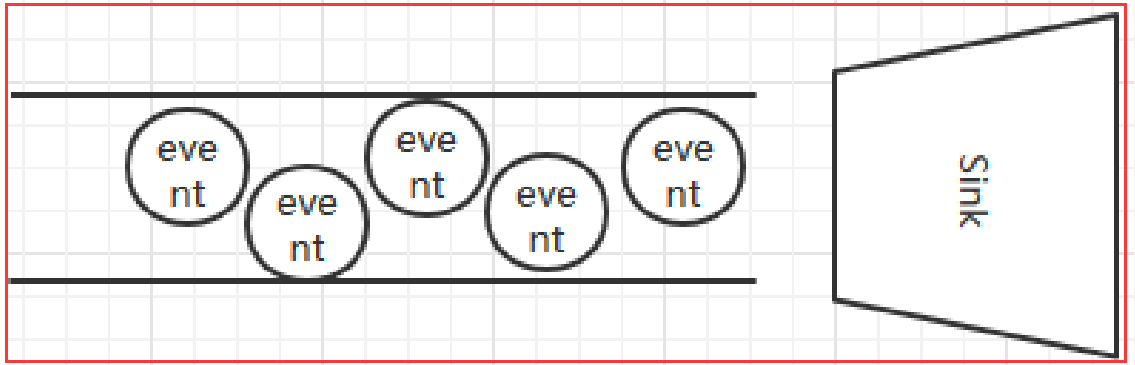
3.6 Sink
Flume Sink取出Channel中的数据,进行相应的存储文件系统,数据库,或者提交到远程服务器。
Flume也提供了各种sink的实现,包括HDFS sink、Logger sink、Avro sink、File Roll sink、Null sink、HBase sink,etc。
Flume Sink在设置存储数据时,可以向文件系统中,数据库中,hadoop中储数据,在日志数据较少时,可以将数据存储在文件系中,并且设定一定的时间间隔保存数据。在日志数据较多时,可以将相应的日志数据存储到Hadoop中,便于日后进行相应的数据分析。
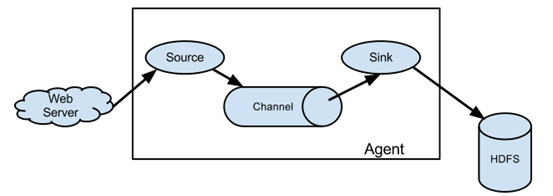
四、Flume的部署类型
4.1 单一流程
4.2 多代理流程(多个agent顺序连接)
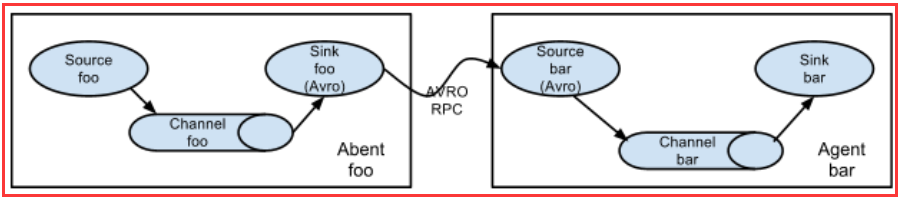
可以将多个Agent顺序连接起来,将最初的数据源经过收集,存储到最终的存储系统中。这是最简单的情况,一般情况下,应该控制这种顺序连接的Agent 的数量,因为数据流经的路径变长了,如果不考虑failover的话,出现故障将影响整个Flow上的Agent收集服务。
4.3 流的合并(多个Agent的数据汇聚到同一个Agent )

这种情况应用的场景比较多,比如要收集Web网站的用户行为日志, Web网站为了可用性使用的负载集群模式,每个节点都产生用户行为日志,可以为每 个节点都配置一个Agent来单独收集日志数据,然后多个Agent将数据最终汇聚到一个用来存储数据存储系统,如HDFS上。
4.4 多路复用流(多级流)
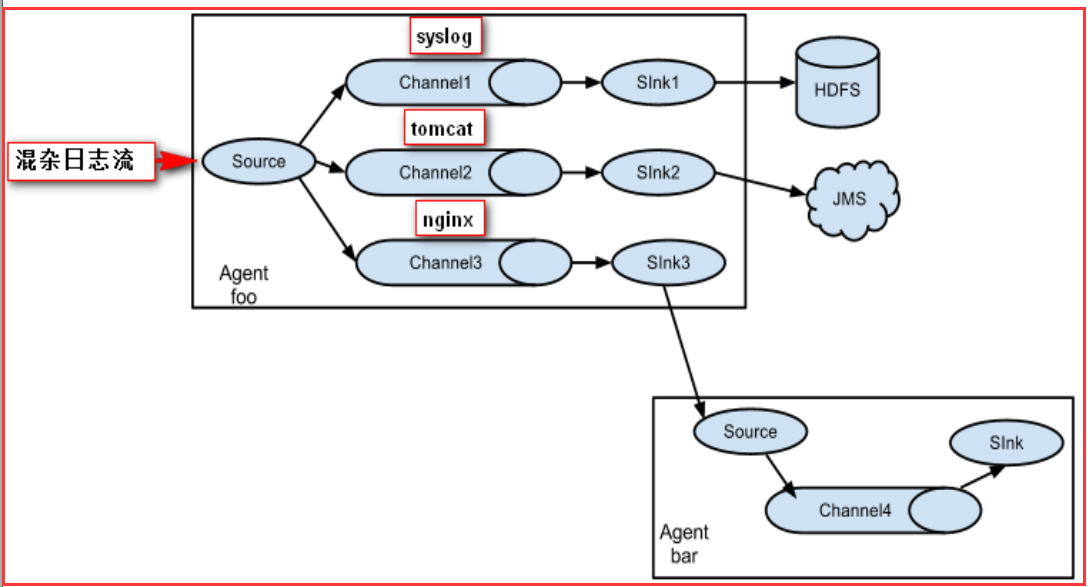
Flume还支持多级流,什么多级流?来举个例子,当syslog, java, nginx、 tomcat等混合在一起的日志流开始流入一个agent后,可以agent中将混杂的日志流分开,然后给每种日志建立一个自己的传输通道。
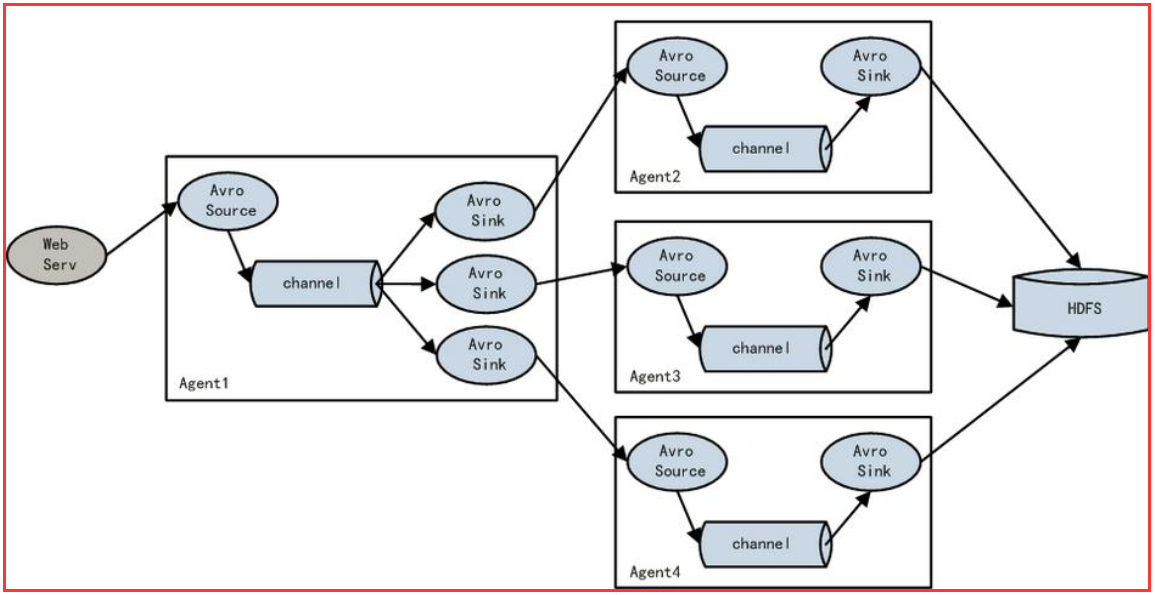
4.5 load balance功能
下图Agent1是一个路由节点,负责将Channel暂存的Event均衡到对应的多个Sink组件上,而每个Sink组件分别连接到一个独立的Agent上 。
五、Flume的安装
5.1 Flume的下载
下载地址:
http://mirrors.hust.edu.cn/apache/
http://flume.apache.org/download.html
5.2 Flume的安装
Flume框架对hadoop和zookeeper的依赖只是在jar包上,并不要求flume启动时必须将hadoop和zookeeper服务也启动。
(1)将安装包上传到服务器并解压
[hadoop@hadoop1 ~]$ tar -zxvf apache-flume-1.8.0-bin.tar.gz -C apps/
(2)创建软连接
[hadoop@hadoop1 ~]$ ln -s apache-flume-1.8.0-bin/ flume
(3)修改配置文件
/home/hadoop/apps/apache-flume-1.8.0-bin/conf
[hadoop@hadoop1 conf]$ cp flume-env.sh.template flume-env.sh

(4)配置环境变量
[hadoop@hadoop1 conf]$ vi ~/.bashrc
#FLUME export FLUME_HOME=/home/hadoop/apps/flume export PATH=$PATH:$FLUME_HOME/bin
保存使其立即生效
[hadoop@hadoop1 conf]$ source ~/.bashrc
(5)查看版本
[hadoop@hadoop1 ~]$ flume-ng version