2018-2019-20172329 《Java软件结构与数据结构》第二周学习总结
2018-2019-20172329 《Java软件结构与数据结构》第二周学习总结
教材学习内容总结
《Java软件结构与数据结构》第三章 集合概述——栈
一、集合
1、我们印象中的集合应该最大体现在数学学习中,在高一刚刚入学的时候就已经学习了集合是什么,映射是什么,综合学习数学以及Java的的经验,顾名思义,其实集合就是一些元素的总和,而这些元素可以是一些数字,或者一些类,反正是我们自身在编程的时候所需要的东西。
2、集合可以分为两大类:包括线性集合和非线性集合。从字面上就可以理解这两种集合的区别,线性与非线性的区别,但是所谓的线性所表现出的是什么呢,这就是我们要深入了解的地方。
- (1)线性集合举个例子,就像是小朋友排成一列,我们可以直接的选择我们需要谁,其优势就是内容简单,我们在提取数据或者元素的时候快速方便;
- (2)而非线性集合呢,则是像是一个拓展图,它比较详细的展示了其每一个里面所有的元素,其优势在于它比较可以快速的寻找到我们所需要的元素,展示的时候比较详细,清晰,但是在提取的时候,我认为它可能并没有线性集合那样快。
3、抽象:如何去理解这个抽象,在我看来,它无非就是构成一个事物必不可少的东西,但是我们可以通过一些步骤或者工具去简化(或忽略)一些细节,使得我们自己可以去控制这个事物达到这个事物的最大效能,或者是完成这个事物应当做的任务。综合来讲,就是可以通过一些方法将一个复杂的事物简单化以后变得更加容易控制的东西。
4、强调的一点是:集合也是一种抽象。
5、抽象数据类型(Abstract Date Type,ADT):是一种在程序设计语言中尚未定义其值和操作的数据类型。ADT的抽象性体现在,ADT必须对其实现细节进行定义,且这些对用户是不可见的。
6、数据结构:是一种用于实现集合的编程结构集。
7、集合是一种隐藏了实现细节的抽象。
8、Java集合API是一个类集,表示了一些特定类型的集合,这些类的实现方式各不相同。
二、栈集合
1、栈的元素是按后进先出(LIFO)的方法进行处理的,最后进入栈中的元素最先被移除。
2、编程人员选择的数据结构,应与需要进行数据管理的类型相适应。
3、栈的一些操作方法:
| 操作 | 描述 |
|---|---|
| push | 添加一个元素到栈的顶部 |
| pop | 从栈的顶部移出一个元素 |
| peek | 查看栈顶部的元素 |
| isempty | 确定栈是否为空 |
| size | 确定栈的元素数目 |
三、主要的面向对象概念
1、继承性与多态:
- (1)多态引用是一个引用变量,它可以在不同地点引用不同类型的对象。
- (2)继承可以用于创建一个类层次,其中,一个引用变量可用于指向与之相关的任意对象。
2、泛型 - (1)什么叫做泛型呢?
- 解答:就是我们可以定义一个类,以便他能储存、操作和管理在实例化之前没有指定是何种类型的对象。
- (2)为什么要用泛型呢?
- 解答:使用泛型可以来创建可用于安全且高效地储存任意类型的对象的集合。
四、异常
1、错误和异常表示不正常或不合法的处理。
五、栈ADT
1、Java接口定义了一个抽象方法集,有助于把抽象数据类型的概念与其实现分隔开来。
2、通过使用接口名作为返回类型,方法就不会局限于实现栈的任何特定类。
六、用数组实现栈
代码:
import java.util.Arrays;
import java.util.EmptyStackException;
public class ArrayStack<T> implements StackADT<T> {
private final int DEFAULT_CAPACITY = 100;
private int top;
private T[] stack;
public ArrayStack(){
top = 0;
stack = (T[]) (new Object[DEFAULT_CAPACITY]);
}
// public ArrayStack(int initialCapacity){
// top = 0;
// stack = (T[]) (new Object[initialCapacity]);
// }
@Override
public void push(T element){
if(size()==stack.length)
expandCapacity();
stack[top] = element;
top++;
}
private void expandCapacity(){
stack= Arrays.copyOf(stack,stack.length*2);
}
@Override
public int size(){
int b=0;
for(int a = 0; stack[a] != null;a++)
{
b++;
}
return b;
}
@Override
public T pop() throws EmptyCollectionException
{
if (isEmpty())
throw new EmptyCollectionException("Stack");
top--;
T result = stack[top];
stack[top] = null;
return result;
}
@Override
public T peek() throws EmptyStackException
{
if (isEmpty())
throw new EmptyCollectionException("Stack");
return stack[top-1];
}
@Override
public boolean isEmpty(){
boolean p ;
if (stack[0]!=null){
p=false;
}
else
{
p=true;
}
return p;
}
@Override
public String toString(){
String result = "";
for(int a = 0; a<size();a++){
result += String.valueOf(stack[a] +" ");
}
return result;
}
}
《Java软件结构与数据结构》第四章 链式结构——栈
一、链接作为引用
1、对象引用变量可以用来创建链式结构。
2、链表由一些对象构成,其中每个对象指向了链表中的下一对象。
3、在链表中储存的对象通常泛称为链表的结点。
4、链表会按需动态增长,因此在本质上,它没有容量限制。
二、管理链表
1、插入结点:改变引用顺序是维护链表的关键。
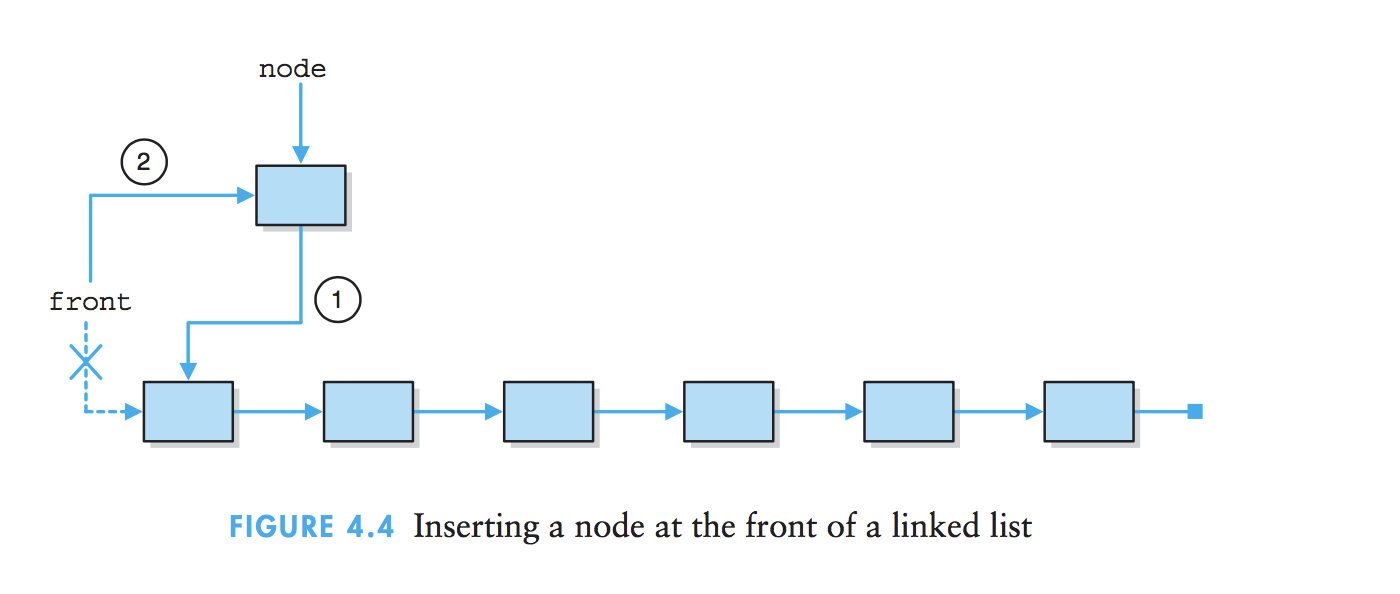
2、删除结点:处理链表的首结点需要进行一些特殊处理。
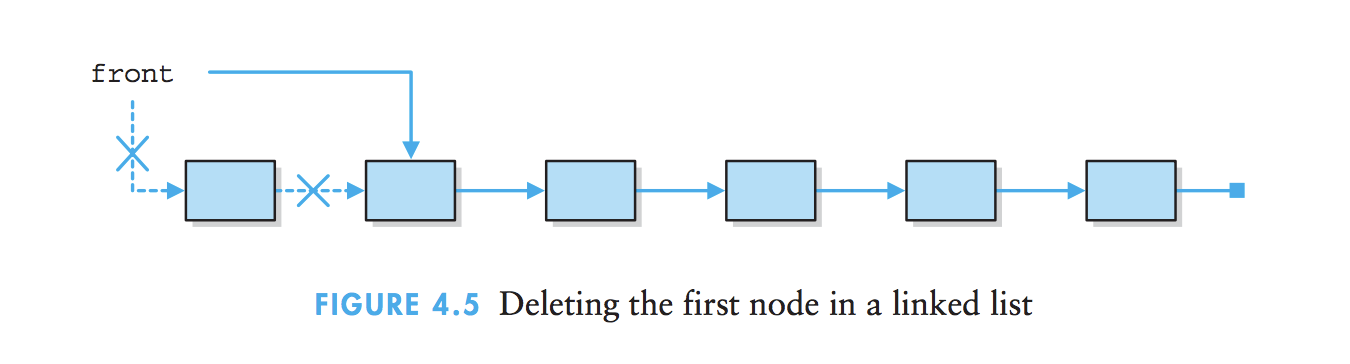
三、无链接的元素
1、储存在集合中的对象不应该含有基本数据结构的任何实现细节。
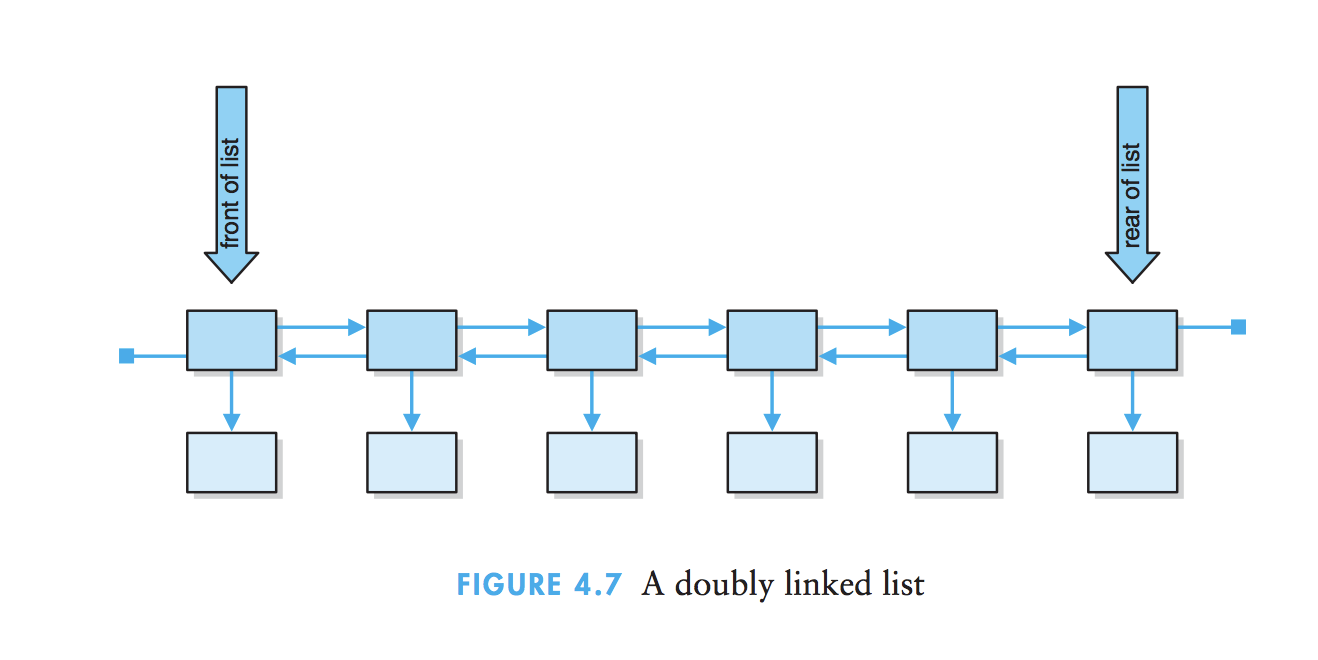
2、双向链表:在双向链表中,需要维护两个引用:一个引用指向链表的首结点;另一个引用指向链表的末端点。链表的每个结点都存在两个引用:一个指向下一个元素,另一个指向上一个元素。
四、用链表实现栈
1、只要有效地实现了恰当的操作,集合的实现都可用来求解问题。
package chapter4.pp4_2;
public class LindedStack<T> implements StackADT<T> {
private int count;
private LinnearNode<T> top;
public LindedStack(){
count=0;
top=null;
}
@Override
public void push(T element) {
LinnearNode<T> temp=new LinnearNode<T>(element);
temp.setNext(top);
top = temp;
count++;
}
@Override
public T pop() throws EmptyCollectionException {
if (isEmpty())
throw new EmptyCollectionException("Stack");
T result = top.getElement();
top=top.getNext();
count--;
return result;
}
@Override
public T peek() {
if (isEmpty())
throw new EmptyCollectionException("Stack");
T result = top.getElement();
top=top.getNext();
return result;
}
@Override
public boolean isEmpty() {
boolean p ;
if (size()==0){
p=true;
}
else
{
p=false;
}
return p;
}
@Override
public int size() {
return count;
}
@Override
public String toString(){
LinnearNode node = new LinnearNode();
while (node != null) {
System.out.print(node.getElement()+" ");
node = node.getNext();
}
return node.getElement().toString();
}
}
教材学习中的问题和解决过程
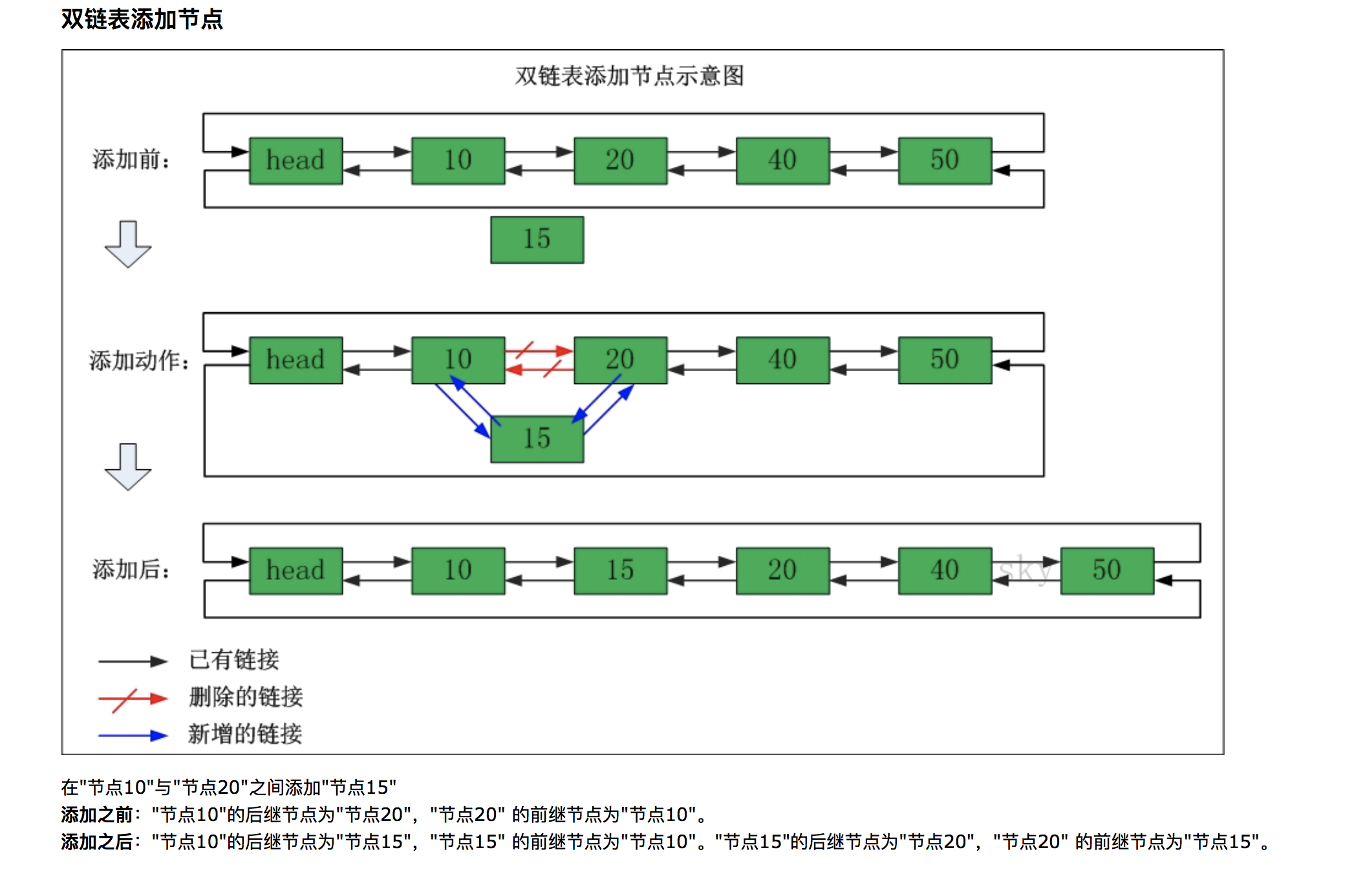
- 问题1:看到了教材中对于双向链条的提起,就很好奇它是如何进行创建和运转的:
- 问题1解决方法:
首先了解一个方法不如和学习单链表一样的方法,从图解来入手:
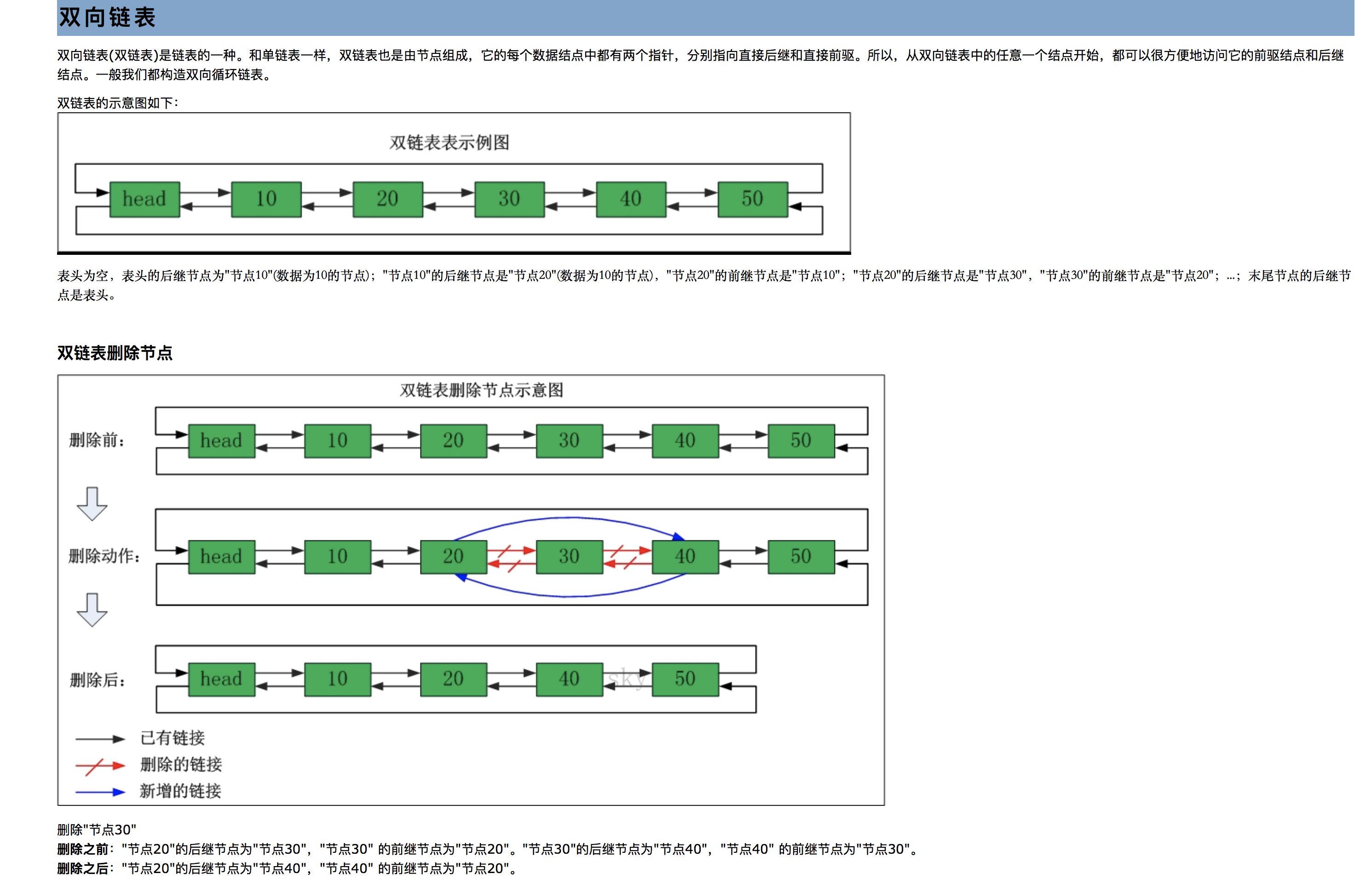
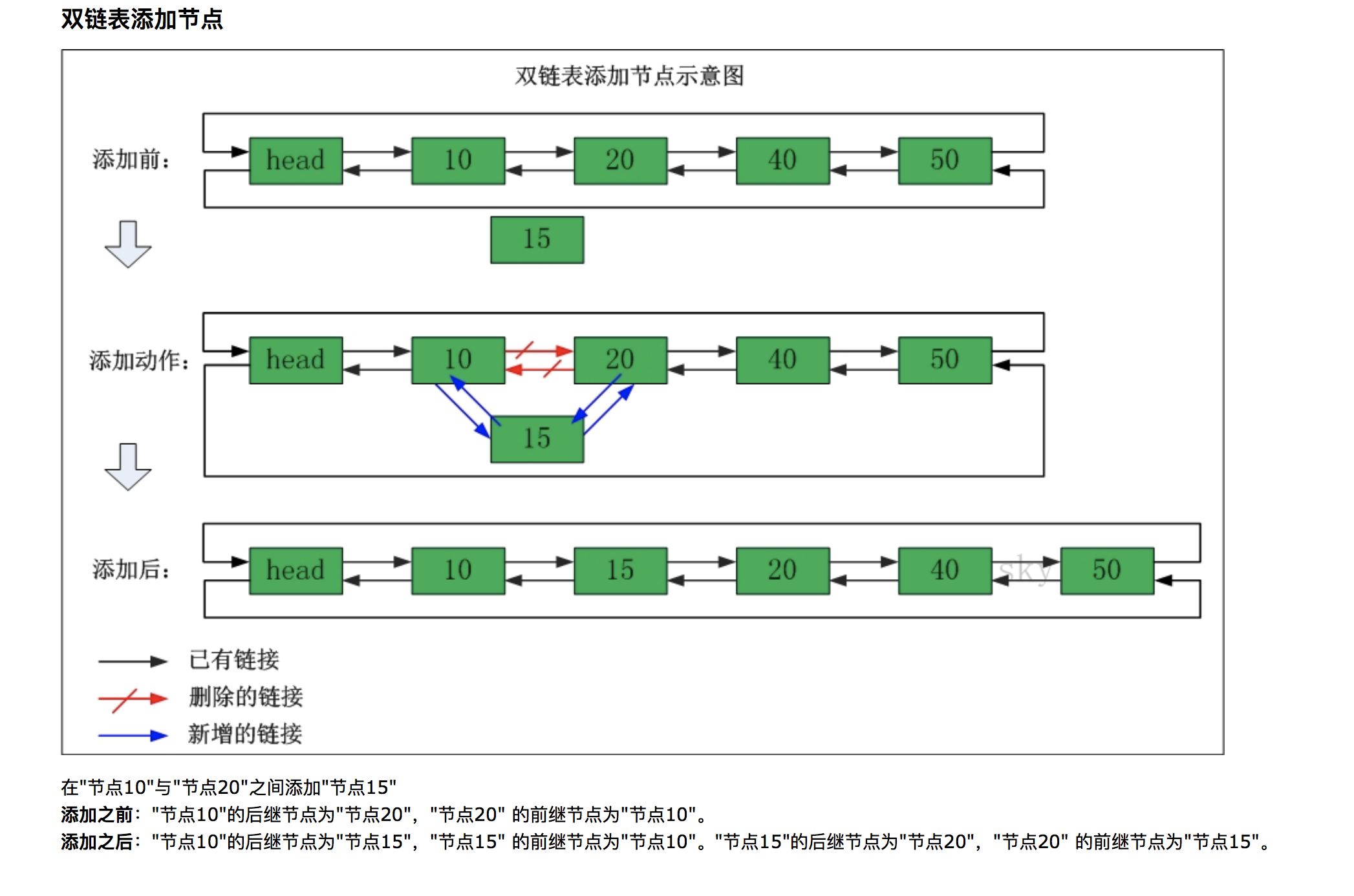
这就是具体的过程,也让我自己了解到双链表的神奇。
代码调试中的问题和解决过程
- 问题1:用数组实现栈和用链表实现栈的区别以及效率
- 问题1解决方法:使用代码对比我们自己实现的栈的性能差异:
private static double testStack(Stack<Integer> s, int opCnt) {
long startTime = System.nanoTime();
for (int i = 0; i < opCnt; i++) {
s.push(i);
}
for (int i = 0; i < opCnt; i++) {
s.pop();
}
long endTime = System.nanoTime();
return (endTime - startTime) / 1000000000.0;
}
上面的代码实现:对栈进行opCnt次入栈和出栈操作,记录所消耗的时间。(注:nonoTime的单位是ns,将结果转换为s,除以10的9次方)
首先将opCnt设置为10 0000 来看看性能差异:
public static void main(String[] args) {
ArrayStack<Integer> arrayStack = new ArrayStack<Integer>();
LinkedStack<Integer> linkedStack = new LinkedStack<Integer>();
int opCnt = 100000;
double time1 = testStack(arrayStack, opCnt);
double time2 = testStack(linkedStack, opCnt);
System.out.println("arrayStack:" + time1 + "s");
System.out.println("linkedStack:" + time2 + "s");
}
将opCnt设置为100 0000:
结果:
arrayStack:0.020232116s
linkedStack:0.016551687s
将opCnt设置为1000 0000:
arrayStack:3.780388172s
linkedStack:9.333468302s
总结:
基于数组的栈是在数组尾部进行入栈和出栈操作,因此实现复杂度为O(1);
基于链表的栈是在链表头部进行入栈和出栈操作,因此实现复杂度也为O(1);
因此两者的性能不会差很多,在opCnt=1000 0000时,arrayStack的性能比linkedStack性能要好。原因是linkedStack要进行大量的new操作,在opCnt较小的情况下,体现不出性能差异;而在操作次数大时,arrayStack性能优势就体现出来了。
码云链接

因为我的as传不到码云上面所以在这里给出我的Java代码和运行结果:
package com.example.pp3_9;
import android.os.Bundle;
import android.support.v7.app.AppCompatActivity;
import android.view.View;
import android.widget.Button;
import android.widget.EditText;
import java.util.Stack;
public class MainActivity extends AppCompatActivity {
LinkedlistStack stack=new LinkedlistStack();
private String result="";
int time=0;
String re="";
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
Button button1=(Button)findViewById(R.id.button);
button1.setOnClickListener(new mybuttoninsert1());
Button button2=(Button)findViewById(R.id.button2);
button2.setOnClickListener(new mybuttoninsert2());
}
public class mybuttoninsert1 implements View.OnClickListener {
@Override
public void onClick(View view) {
EditText a =(EditText) findViewById(R.id.editText3);
String[] aa = a.getText().toString().split("");
EditText b =(EditText)findViewById(R.id.editText);
stack.push(aa[time]);
time++;
String result="";
for (int i =0;i<a.getText().length()-time;i++){
result+=aa[i+1];
//result+=aa[a.getText().length()-time];
}
b.setText(result);
}
}
public class mybuttoninsert2 implements View.OnClickListener {
@Override
public void onClick(View view) {
EditText c =(EditText)findViewById(R.id.editText2);
// c.setText(stack.pop().toString());
re+=stack.pop();
c.setText(re);
}
}
}

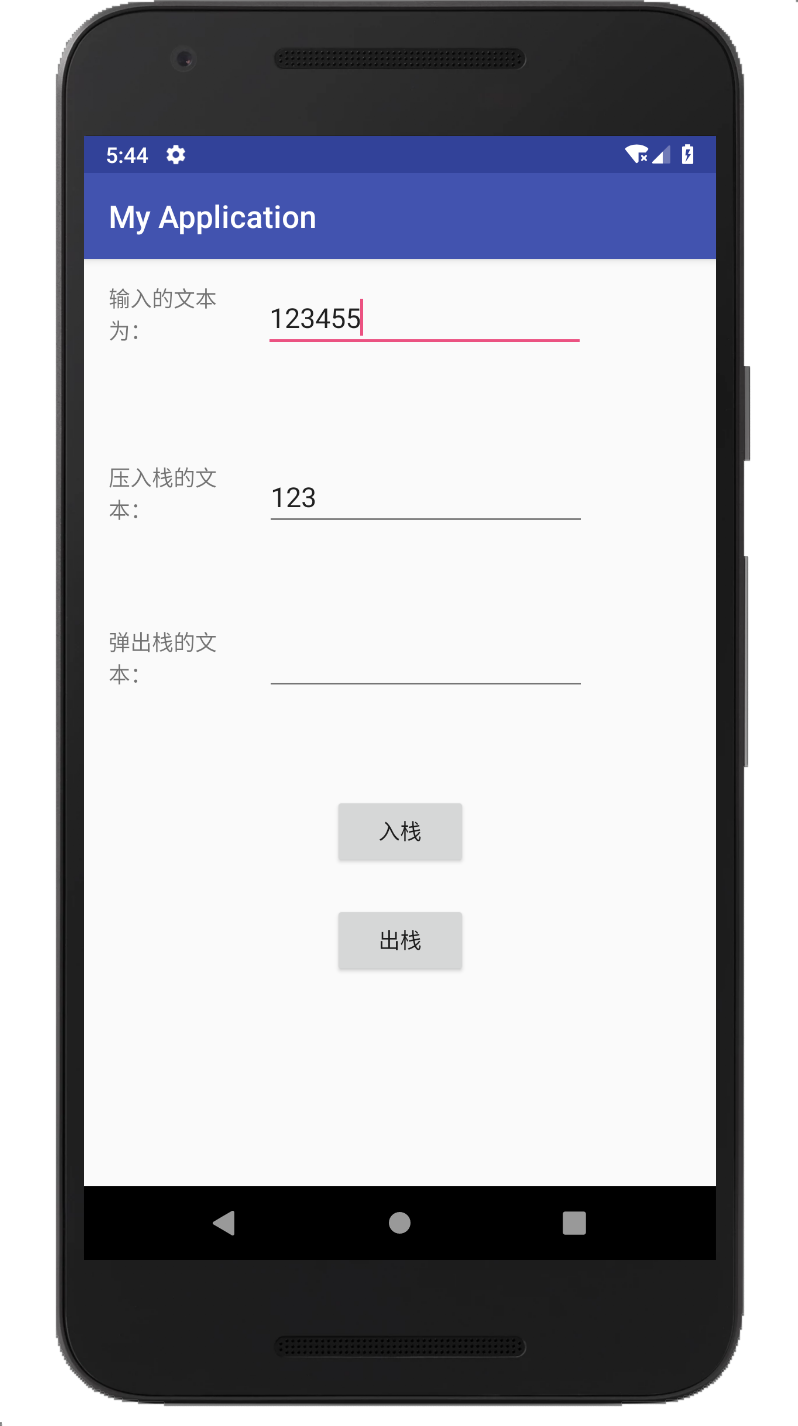
上周考试错题总结
-
错题1.An efficient system handles problems gracefully
A .True
B .False正确答案: B 我的答案: A -
错题解析:因为在书里有这样一句话:“一个健壮的系统可以完美地处理各种问题。”被这句话给误导了。
-
错题2.Which of the following has the smallest time complexity?
A .3n+5+2n
B .logn+2
C .3n+4
D .nlogn正确答案: B 我的答案: D -
错题解析:因为对于题目位置的不确定性,没有看出原本题目的意思。
结对及互评
- 本周结对学习情况
- 博客中值得学习的或问题:
- 内容详略得当;
- 代码调试环节比较详细;
- 基于评分标准,我给本博客打分:5分。得分情况如下:
-
正确使用Markdown语法(加1分):
-
模板中的要素齐全(加1分)
-
教材学习中的问题和解决过程, 一个问题加1分
-
代码调试中的问题和解决过程, 一个问题加1分
- 博客中值得学习的或问题:
- 内容详略得当;
- 代码调试环节比较详细;
- 基于评分标准,我给本博客打分:9分。得分情况如下:
- 正确使用Markdown语法(加1分):
- 模板中的要素齐全(加1分)
- 教材学习中的问题和解决过程, 一个问题加1分
- 代码调试中的问题和解决过程, 一个问题加1分
感悟
这一周Java课程学习了新知识,也温习了旧的一些功课,因为对于知识的掌握程度一开始的了解程度不是很好,所以就花了很长的时间去理解知识点,知识点的理解对于书本内容的吃透还是很重要,这一学期的任务相比于上学期的任务只能讲熟练程度,因为很多也都是之前写过的代码,因此希望自己新的一学期可以自己加油,努力!唉,又是一波鸡汤!!
学习进度条
| | 代码行数(新增/累积)| 博客量(新增/累积)|学习时间(新增/累积)
| -------- | :----------------😐:----------------😐:---------------: |:-----:
| 目标 | 5000行 | 30篇 | 400小时
| 第一周 | 0/0 | 1/1 | 6/6
|第二周 | 1313/1313 |1/2 | 20/26
参考资料
蓝墨云班课
Java程序设计
java:链表排序
[数据结构]java实现的简单链表的 头/尾插法
玩转数据结构(五)数组栈和链表栈性能对比
