【深度学习】【NLP】RNN,LSTM,GRU
李宏毅的深度学习课程。
RNN一个应用是填槽,slot filling是需要存储记忆的。
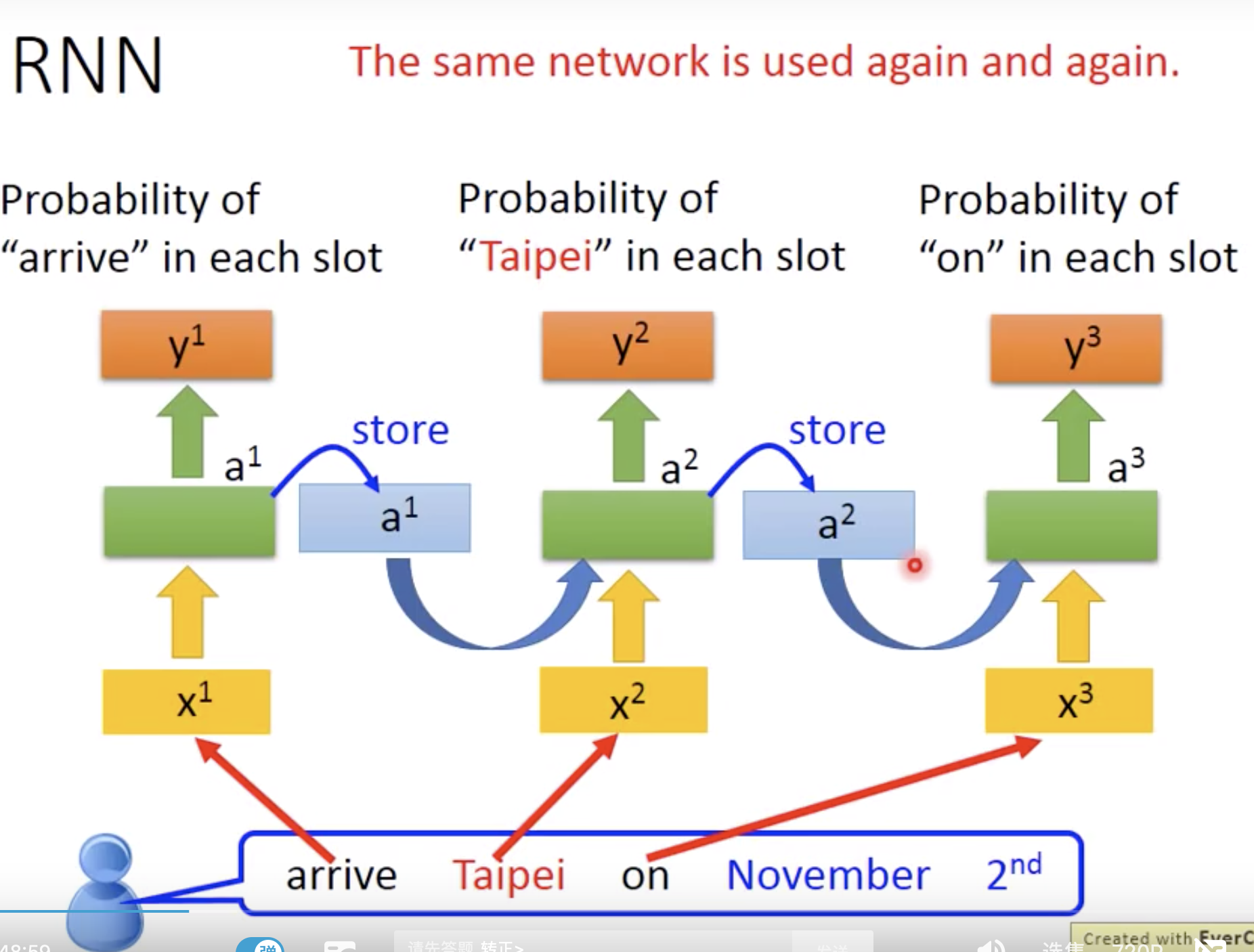
为什么要使用RNN
前馈神经网络
- 常见的前馈神经网络有单层前馈神经网络、多层前馈神经网络(DNN、多层感知器)、CNN(点名CNN这个垃圾)等。
前馈神经网络的缺陷
前馈神经网络前一个输入与后一个输入之间没有任何关系,
如果我们不知道它们的顺序,随机处理它们,那么我们就无法正确的预测出这句话的语义。
因为:苹果吃我、苹我吃果和我吃苹果是完全不同的语义。
RNN的种类(结构的四种形式)
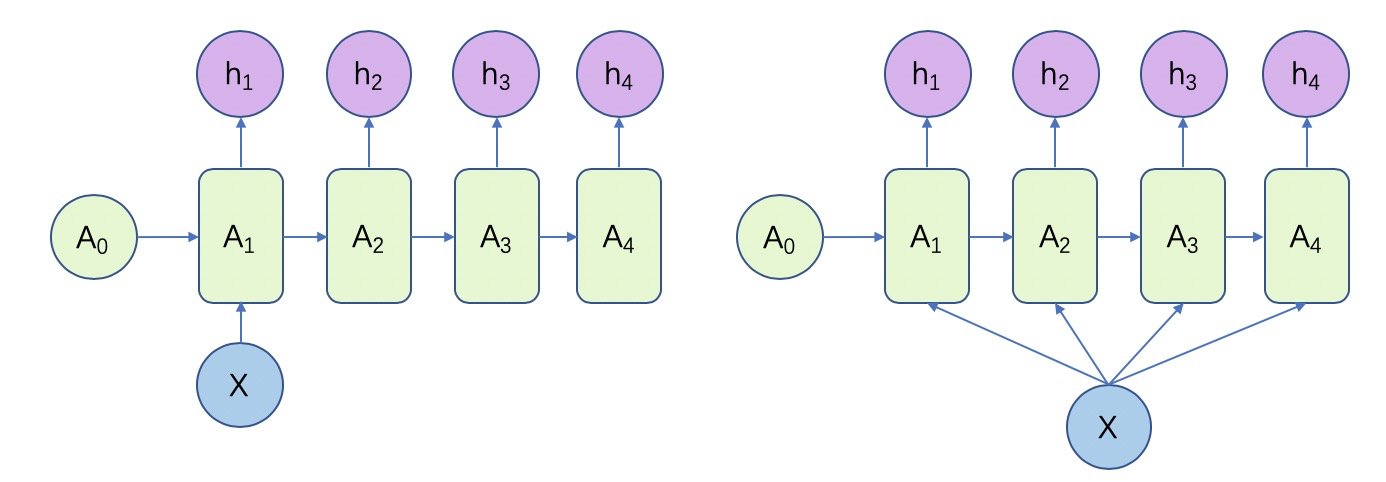
1 to N
这种形式一是只在序列开始把输入信息输入模型计算(左);二是把输入信息作为每个阶段的输入(右),这种结构可以处理如: 输入图像的特征,输出y的序列是一段句子或者从别的类别生成语音;输入一个类别,输出一段描述文字这类问题。
RNN的种类(结构的四种形式)
1 to N
输入一个类别,输出一段描述文字这类问题。
N to 1
输入的是一个序列,输出的是一个单独的值。
这种结构常用于处理分类问题,如:输入一段文字判断类别、输入句子判断感情倾向、输入图片判断类别。
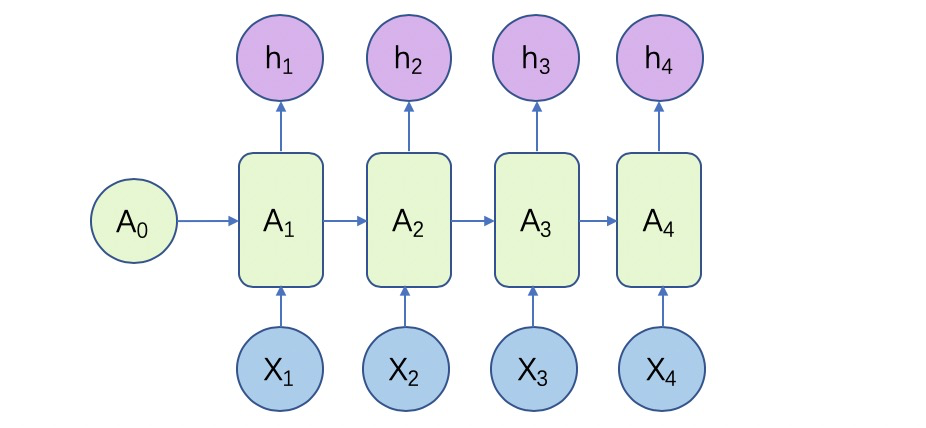
N to N
输入和输出序列是等长的。这种可以用来生成文章,诗歌。
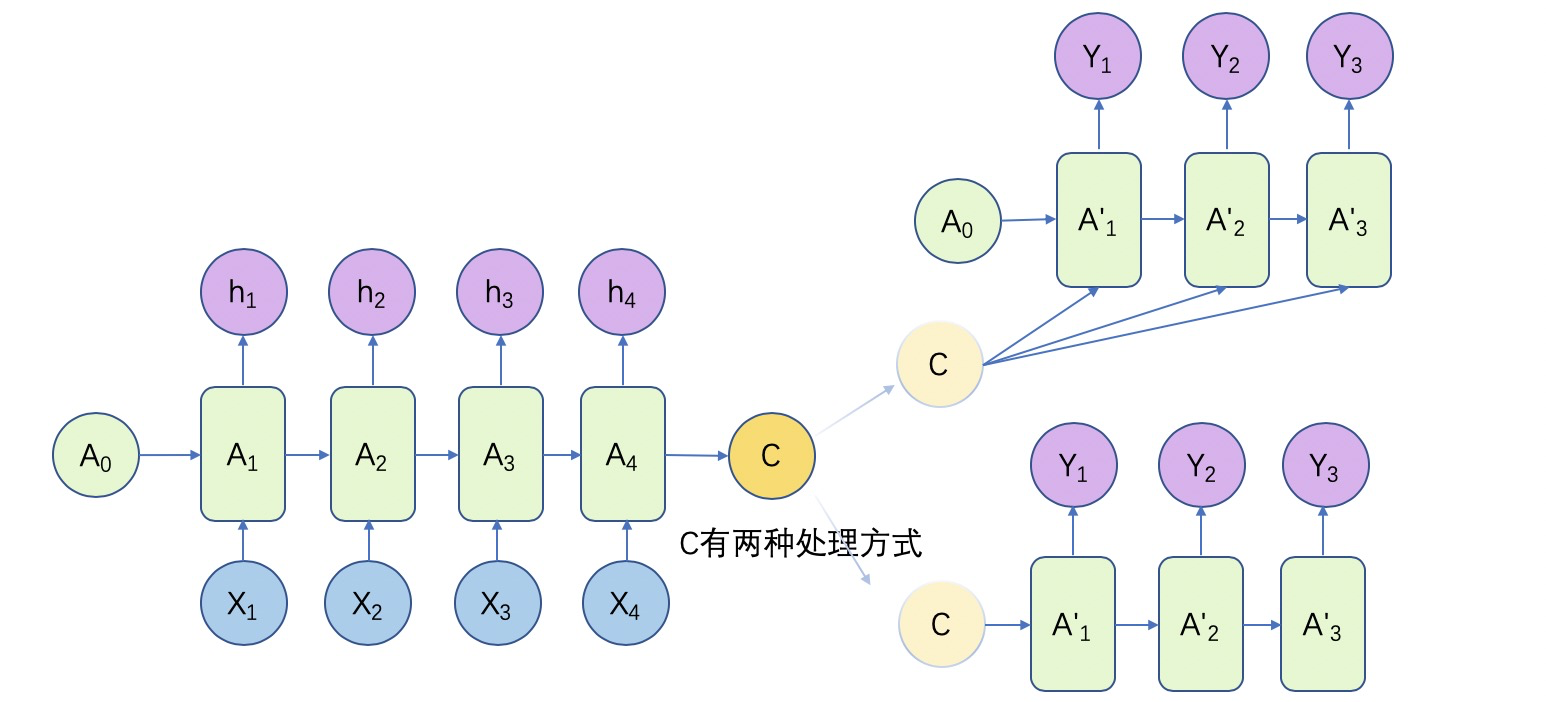
N to M
这种结构又称Encoder-Decoder、Seq2Seq模型,它会将输入数据编码成一个上下文向量c,之后通过c输出预测序列。它广泛应用于机器翻译、文本摘要、阅读理解、对话生成等领域。
RNN的实现
????
RNN常见变体
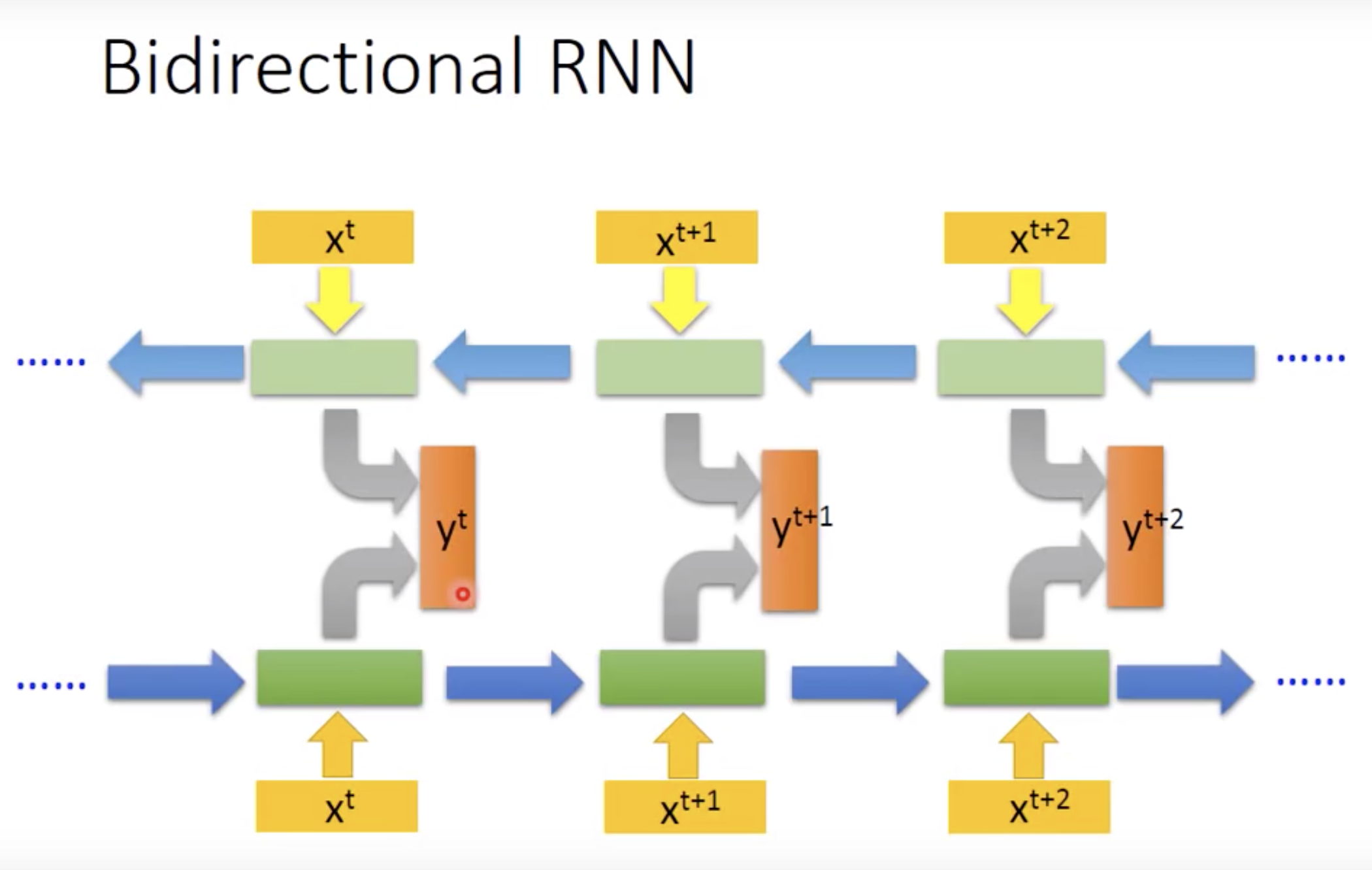
双向循环网络(Bi-RNN)
在处理序列信息时,有时我们不仅需要之前的信息,还需要之后的信息,比如:预测我__苹果这句话所缺失的词是什么,我们就需要根据上下文的词汇一起去预测。
一个由两个RNN上下叠加在一起组成的相对较简单的RNN。因此,它的输出由前向RNN和后向RNN共同决定
文章啊句子常用bidirectional,记忆到的范围比较大。performance好。
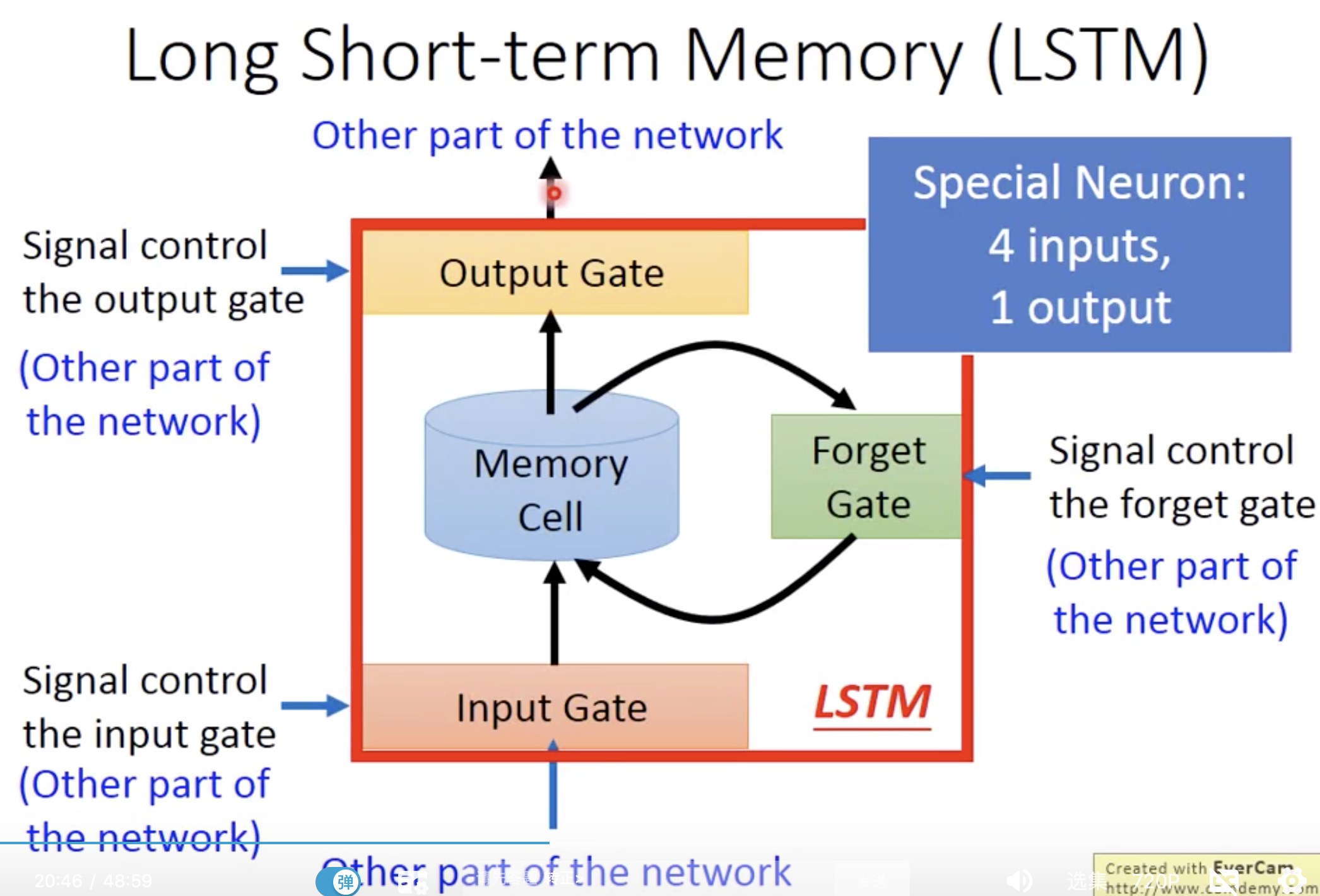
LSTM
RNN在处理长期依赖(时间序列上距离较远的节点)时会遇到巨大的困难,因为计算距离较远的节点之间的联系时会涉及雅可比矩阵的多次相乘,
会造成梯度消失或者梯度膨胀的现象。 LSTM就是一种为了解决长期依赖问题而提出的特殊RNN
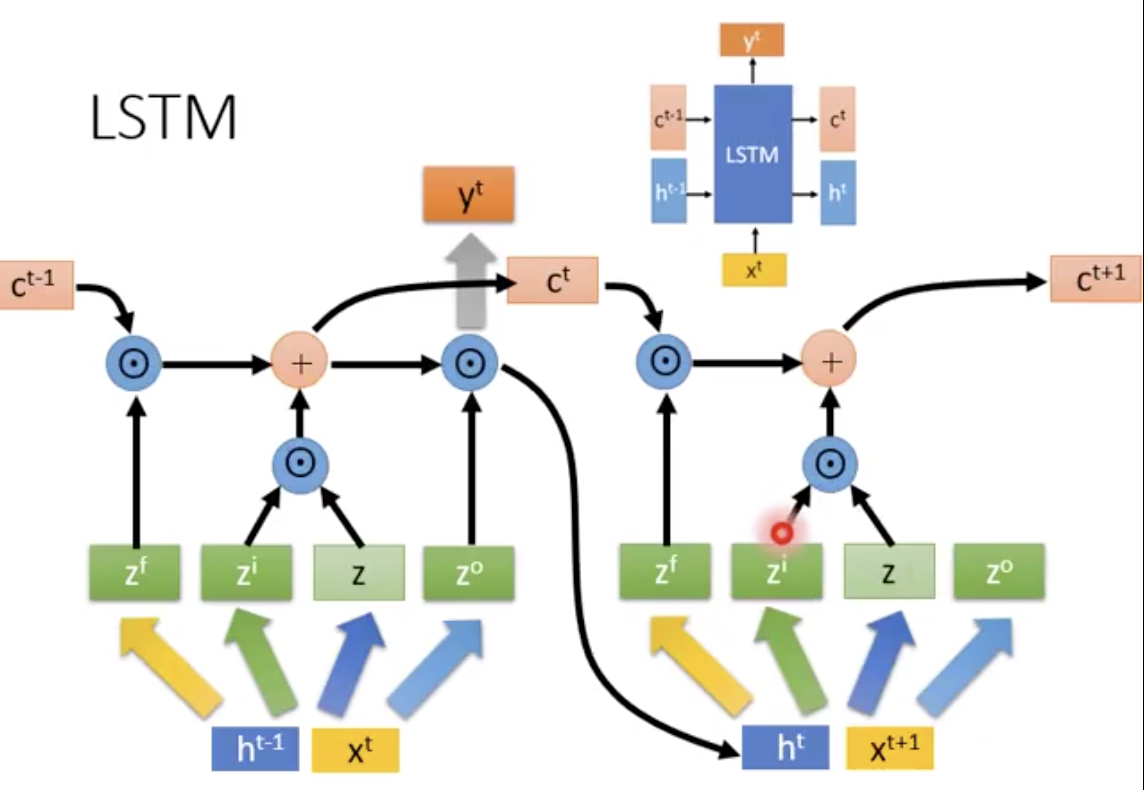
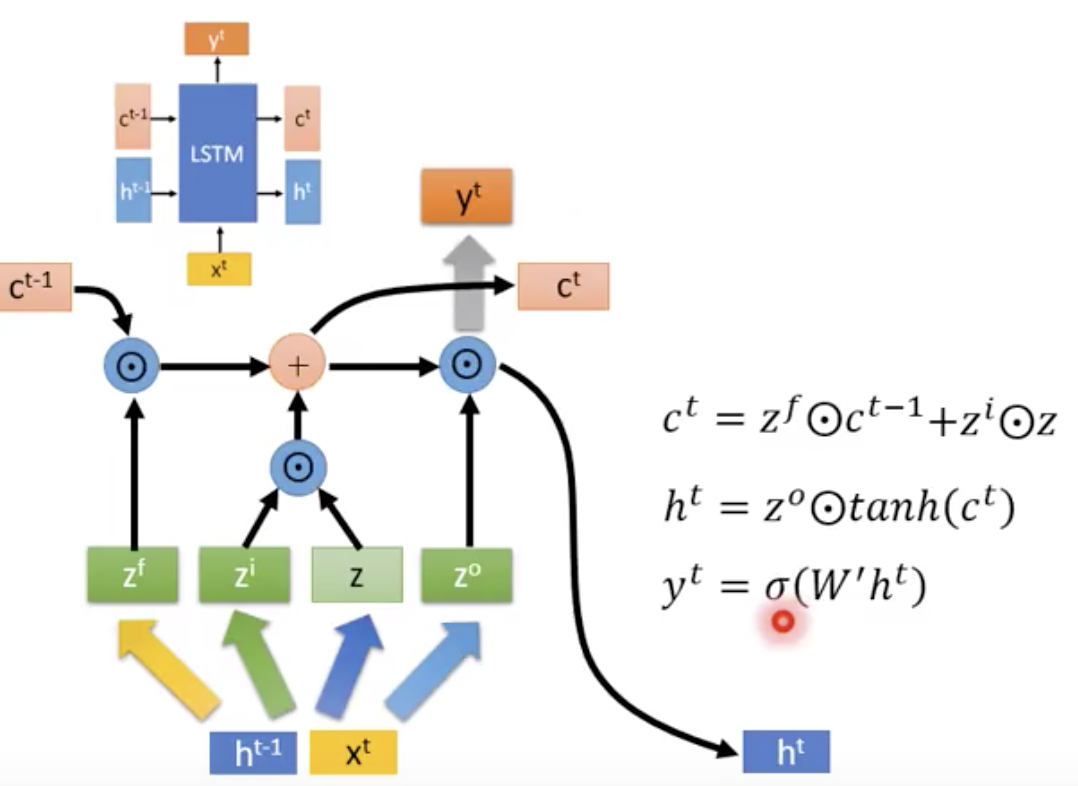
在LSTM里面,有3个gate,自己会学习什么时候要把gate打开什么时候关上。三个gate和一个input,所以说这个neuron有4个input
RNN’s may leave out important information from the beginning.
原来RNN是非常short,下一个时间点就wash掉了更早的memory。现在也short term但是更long一点
一个计算例子
蓝色是计算一步步得到的memory

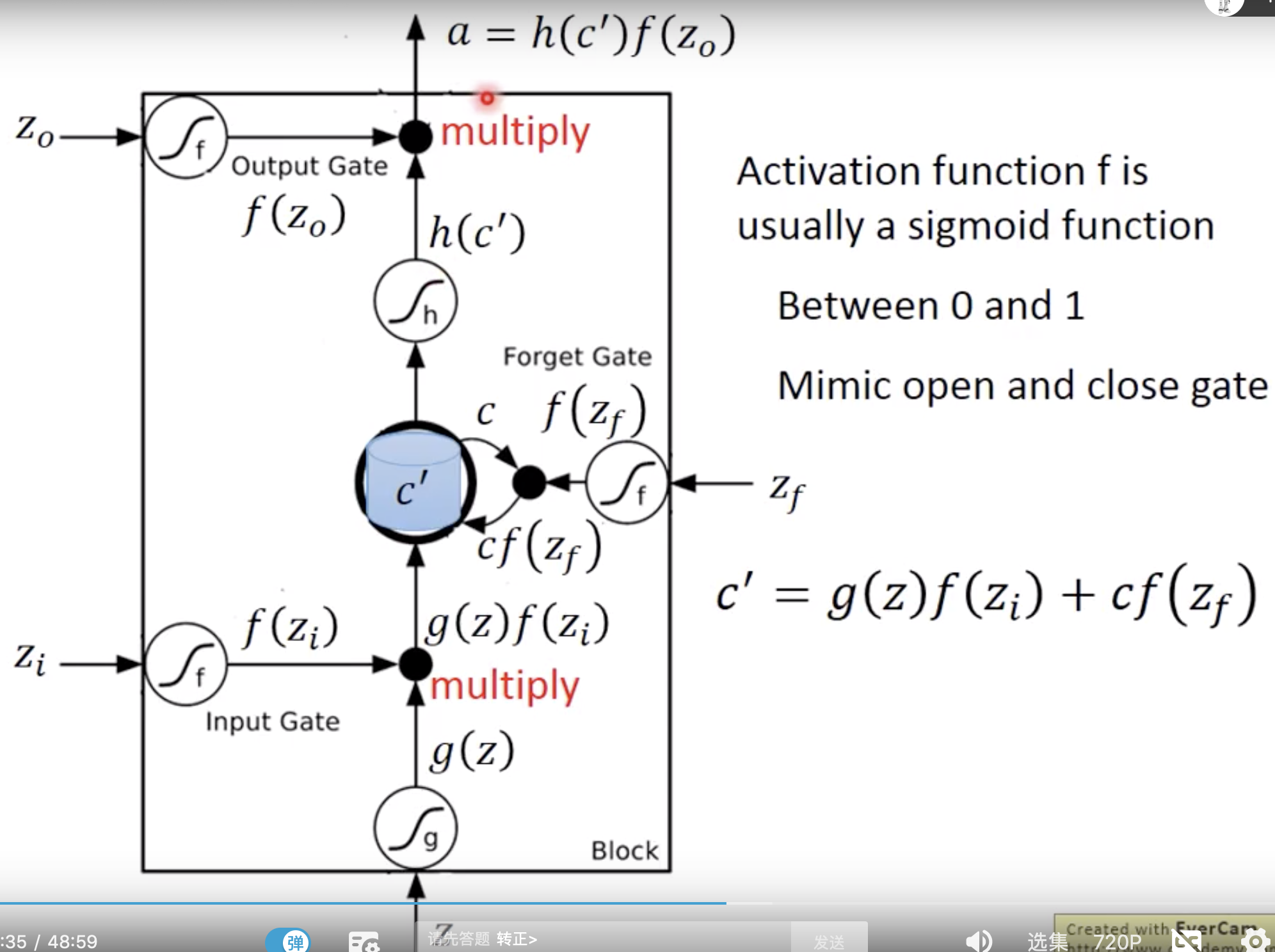
lstm有4个input
1x3维度的input乘以线段上三个值,加上绿色方框里的bias
就是input. w 和b是训练出来的,为了演示,假设我们都知道。
input gate表明说,
bias是-10,如果x2是0,这个gate就是关闭的
同理,forget gate,如果x2是很大的负数,才会是关闭的
同理,output gate,平时是关闭的,只有x3是正值,才会打开。
假设mempry里面的初始值是0
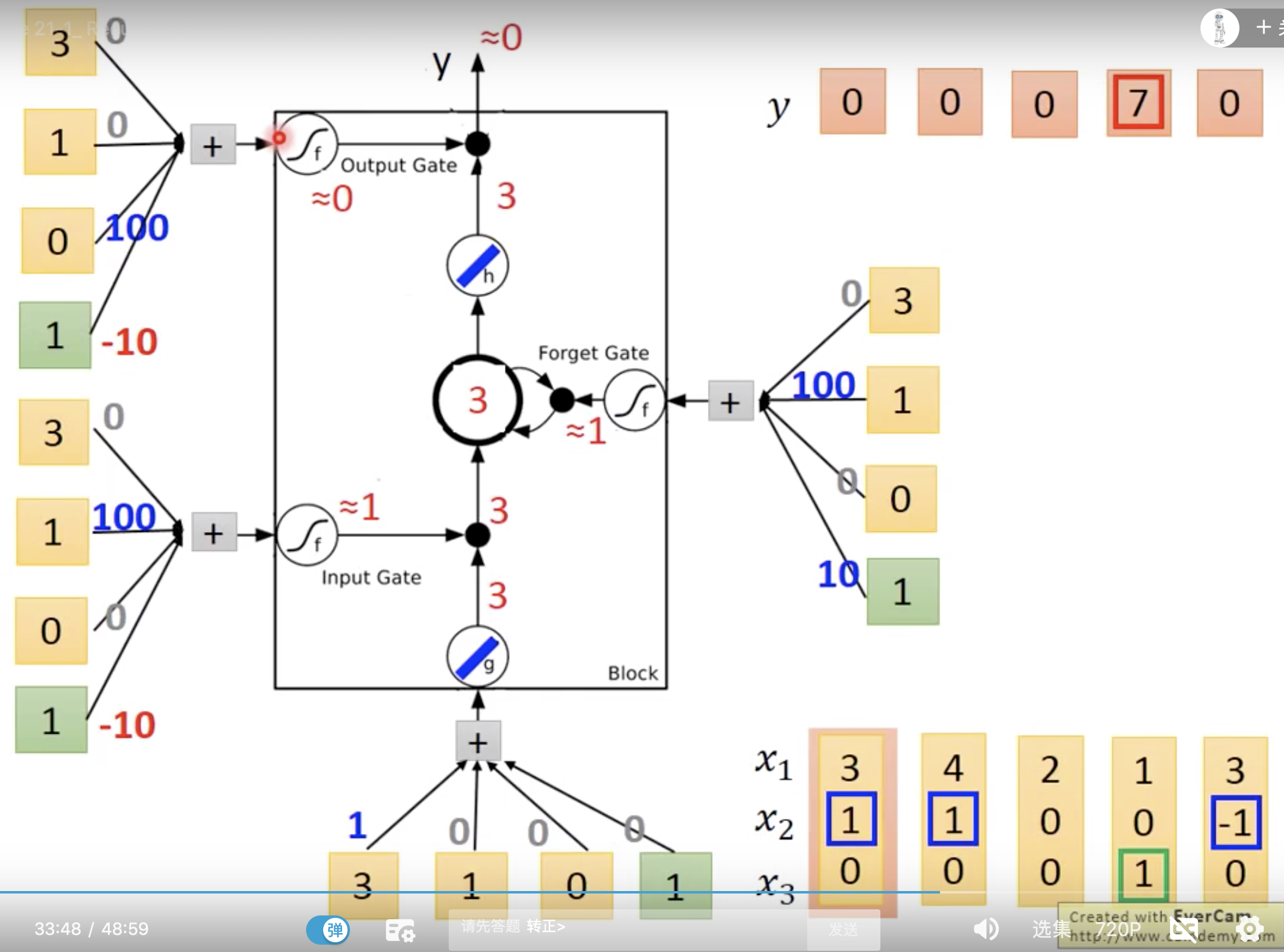
不要害怕

门控循环单元(GRU)
GRU可以看成是LSTM的变种,GRU把LSTM中的遗忘门和输入们用更新门来替代。 把cell state和隐状态ht进行合并,在计算当前时刻新信息的方法和LSTM有所不同。GRU的构造更简单,在训练数据大的情况下能节省更多时间
在LSTM中引入了三个门函数:输入门、遗忘门和输出门 。GRU模型中只有两个门:更新门和重置门。
更新门的值越大说明前一时刻的状态信息带入越多。重置门越小,前一状态的信息被写入的越少。
RNN使用的计算资源比它的演化变体LSTM和GRU少得多。
梯度消失会导致我们的神经网络中前面层的网络权重无法得到更新,也就停止了学习。
梯度爆炸会使得学习不稳定, 参数变化太大导致无法获取最优参数。
LSTM如何解决梯度消失或爆炸的?
https://www.data-blogger.com/2017/08/27/gru-implementation-tensorflow/

rnn的basic function把自己的吐出来的再吃进去,说明这些h是有一样的dimention
rnn厉害的就是他的参数量不会随着input sequence长度的改变而变多
可以是deep的。f2吃y1和b
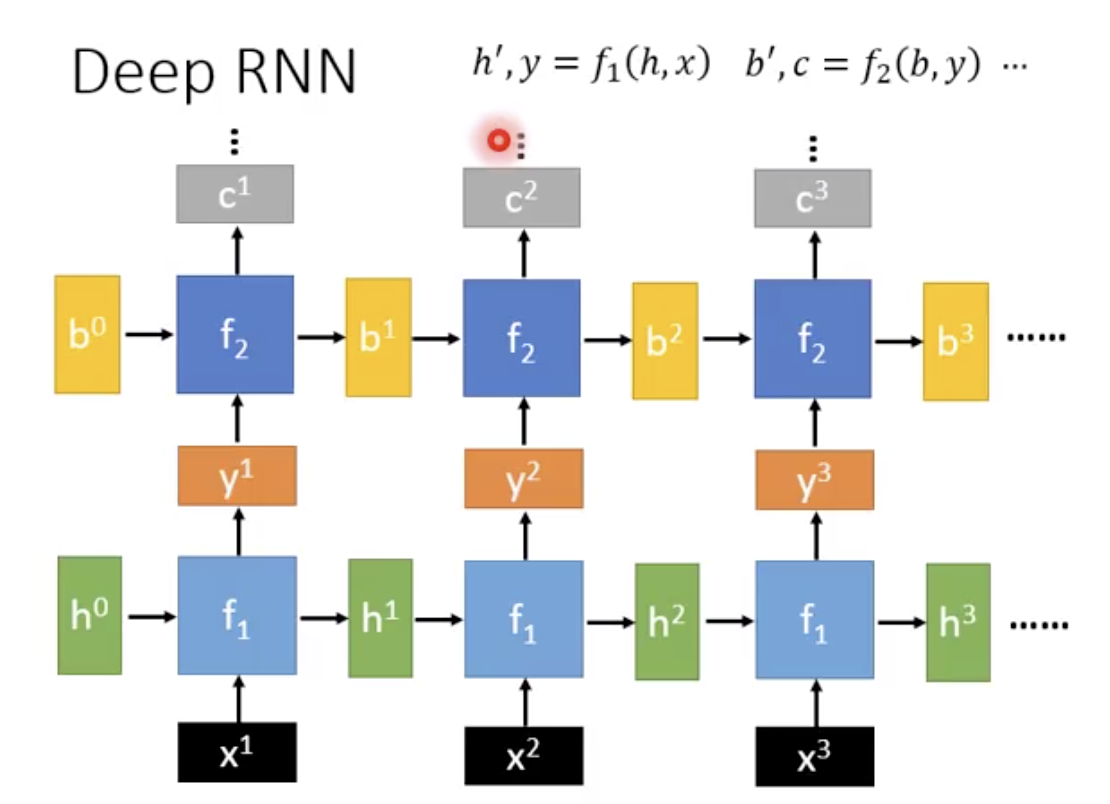
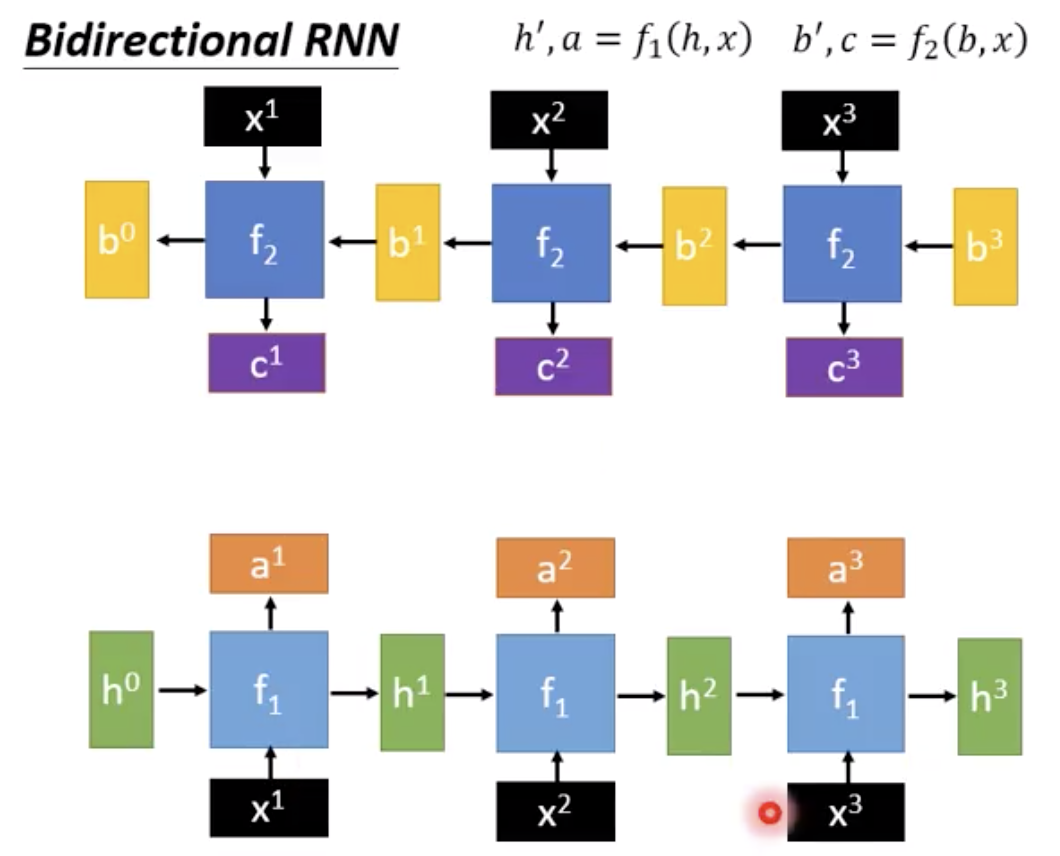
当然也可以是双向的
最后有一个f3把两排吃进来
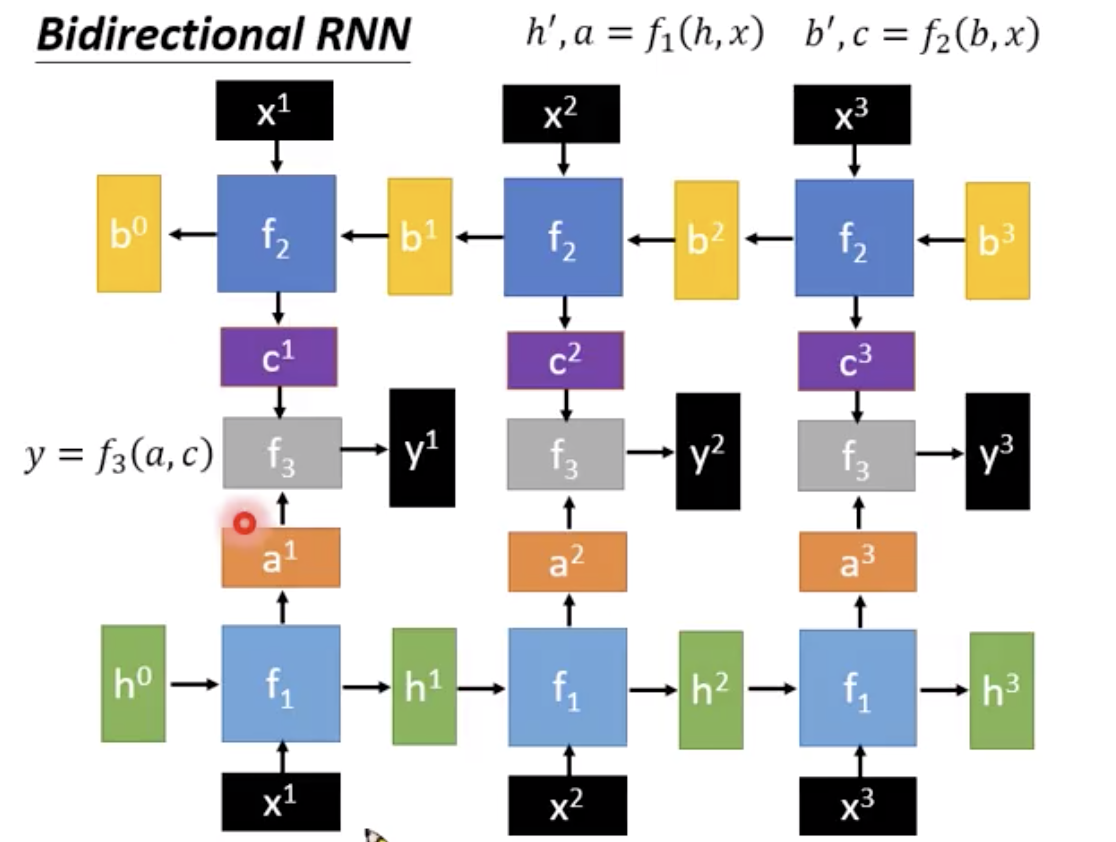
那么这个basic function f要怎么选择呢。最简单就是wx+b
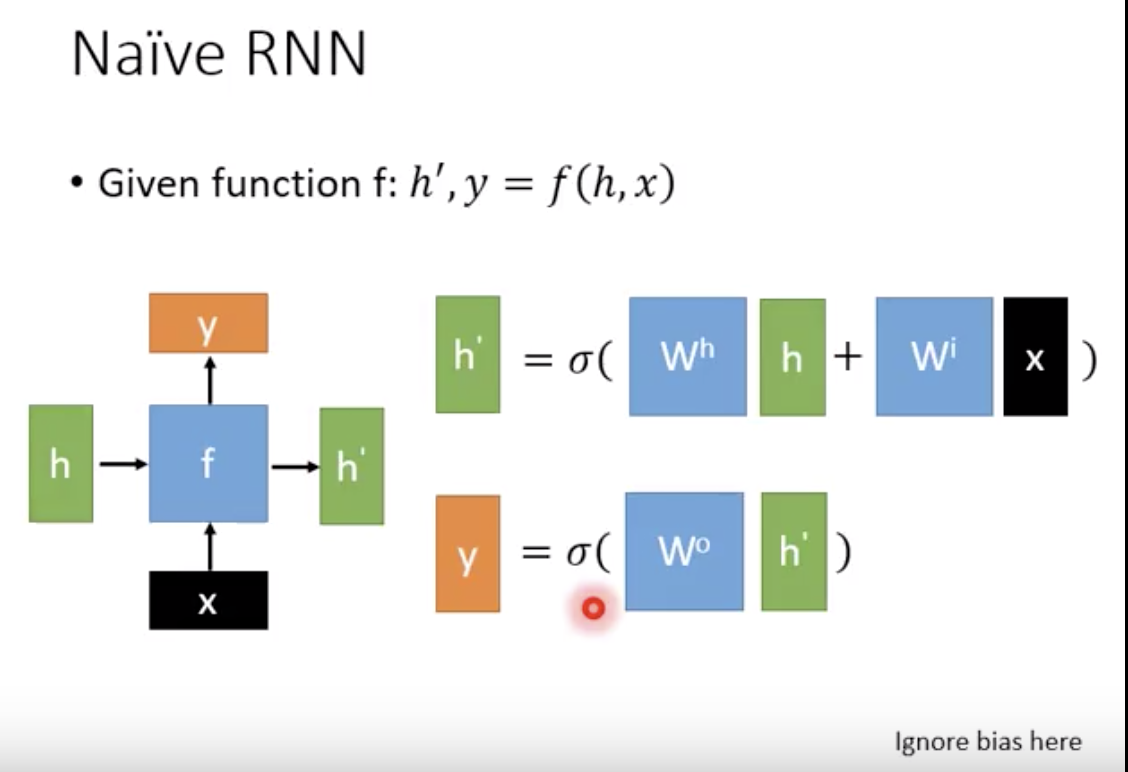
中间那个activation function 一般用relu之类。
更常见是lstm,而不是naive rnn
在lstm里面,input和output都分为两部分,一个是c一个是h
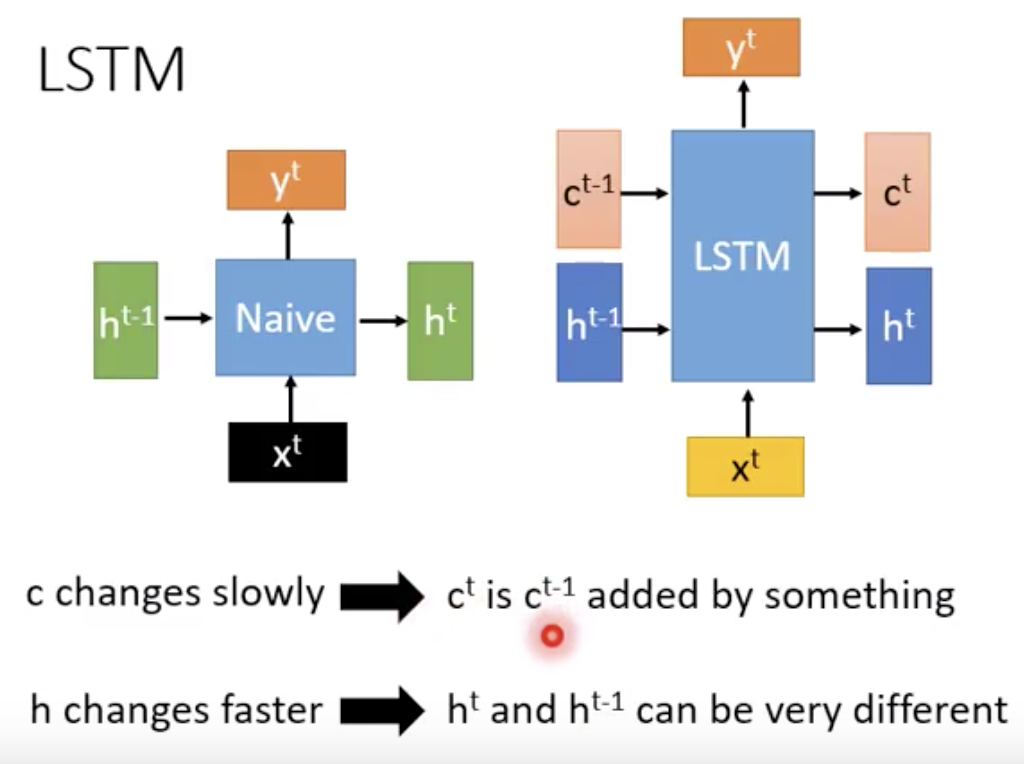
lstm记忆比较久,就是因为有ct c(t-1)
ct只是 c(t-1) elementwise乘上一个东西加上一个东西,没有太多non linear的,而ht要tanh()一下,因此会变化快一点。
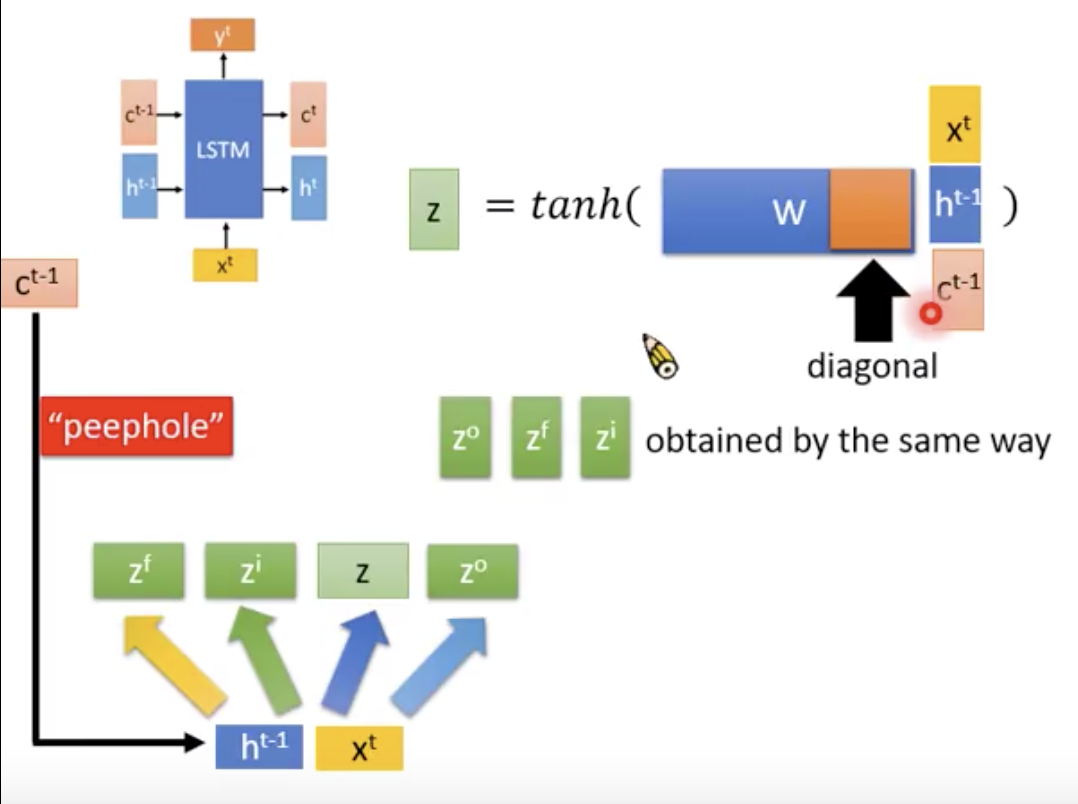
所谓的peephole就是强制w的后面一段是diagonal的东西,线性代数的角度减少参数
这个unit被反复地用。