
小白学git1
什么是版本库呢?版本库又名仓库,英文名repository,你可以简单理解成一个目录,这个目录里面的所有文件都可以被Git管理起来,每个文件的修改、删除,Git都能跟踪,以便任何时刻都可以追踪历史,或者在将来某个时刻可以“还原”。
1.首先,选择一个合适的地方,创建一个空目录:
$ /Users/ocean/desktop
$ mkdir learngit
$ cd learngit
2.进入空目录,通过git init命令把这个目录变成Git可以管理的仓库。
$ cd learngit
$ git init
Initialized empty Git repository in C:/Users/epanhai/Desktop/learngit/.git/
瞬间Git就把仓库建好了,而且告诉你是一个空的仓库(empty Git repository),细心的读者可以发现当前目录下多了一个.git的目录,这个目录是Git来跟踪管理版本库的,没事千万不要手动修改这个目录里面的文件,不然改乱了,就把Git仓库给破坏了。

3.现在我们编写一个firstfile文件,内容如下:
Git is a version control system. Git is free software
一定要放到learngit目录下(子目录也行),因为这是一个Git仓库,放到其他地方Git再厉害也找不到这个文件。
4.用命令git add告诉Git,把文件添加到仓库:
$ git add firstfile.txt
执行上面的命令,没有任何显示,这就对了,Unix的哲学是“没有消息就是好消息”,说明添加成功。
5.用命令git commit告诉Git,把文件提交到仓库
$ git commit -m "wrote a firstfile"
1 file changed, 2 insertions(+) create mode 100644 firstfile
简单解释一下git commit命令,-m后面输入的是本次提交的说明,可以输入任意内容,当然最好是有意义的,这样你就能从历史记录里方便地找到改动记录。
git commit命令执行成功后会告诉你,1 file changed:1个文件被改动(我们新添加的readme.txt文件);2 insertions:插入了两行内容(readme.txt有两行内容)。
为什么Git添加文件需要add,commit一共两步呢?因为commit可以一次提交很多文件,所以你可以多次add不同的文件,比如:
$ git add file1.txt $ git add file2.txt file3.txt $ git commit -m "add 3 files."
6.我们继续修改 firstfile 文件,改成如下内容
Git is a distributed version control system. Git is free software.
7.运行git status命令看看结果:
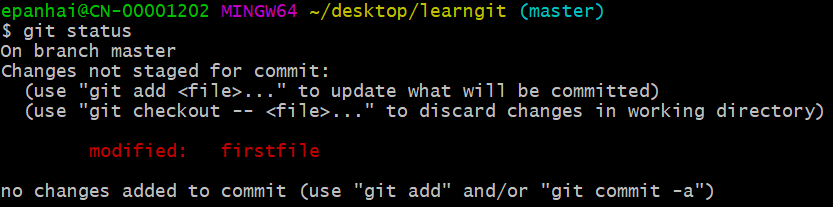
git status命令可以让我们时刻掌握仓库当前的状态,上面的命令输出告诉我们:firstfile被修改过了,但是还没有添加到stage,(缓存区,也叫暂存区),也没有提交。
8.虽然Git告诉我们 firstfile 被修改了,但如果能看看具体修改了什么内容,自然是很好的。比如你休假两周从国外回来,第一天上班时,已经记不清上次怎么修改的firstfile,所以,需要用git diff这个命令看看

-是修改之前的内容
+是修改之后的内容
可以从上面的命令输出看到,我们在第一行添加了一个distributed单词
9.知道了对 firstfile 作了什么修改后,再把它提交到仓库就放心多了,提交修改和提交新文件是一样的两步,第一步是git add:
$ git add firstfile
同样没有任何输出。在执行第二步git commit之前,我们再运行git status看看当前仓库的状态
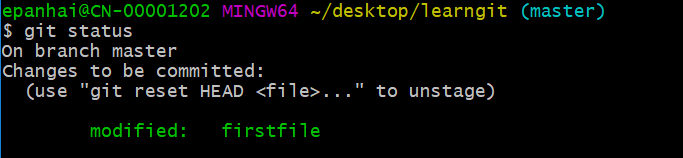
git status告诉我们,修改需要被提交
10. 提交
git commit -m "add distributed"
11.提交后,我们再用git status命令看看仓库的当前状态

Git告诉我们当前没有需要提交的修改,而且,工作目录是干净(working tree clean)的。
12.现在,你已经学会了修改文件,然后把修改提交到Git版本库,现在,再练习一次,修改 firstfile 文件如下
Git is a distributed version control system. Git is free software under the GPL.
然后尝试提交:
$ git add firstfile
$ git commit -m "append GPL" [master 1094adb] append GPL 1 file changed, 1 insertion(+), 1 deletion(-)
像这样,你不断对文件进行修改,然后不断提交修改到版本库里,就好比玩RPG游戏时,每通过一关就会自动把游戏状态存盘,如果某一关没过去,你还可以选择读取前一关的状态。有些时候,在打Boss之前,你会手动存盘,以便万一打Boss失败了,可以从最近的地方重新开始。Git也是一样,每当你觉得文件修改到一定程度的时候,就可以“保存一个快照”,这个快照在Git中被称为commit。一旦你把文件改乱了,或者误删了文件,还可以从最近的一个commit恢复,然后继续工作,而不是把几个月的工作成果全部丢失。
现在,我们回顾一下firstfile文件一共有几个版本被提交到Git仓库里了:
版本1:wrote a firstfile
Git is a version control system.
Git is free software.
版本2:add distributed
Git is a distributed version control system.
Git is free software.
版本3:append GPL
Git is a distributed version control system.
Git is free software distributed under the GPL.
当然了,在实际工作中,我们脑子里怎么可能记得一个几千行的文件每次都改了什么内容,不然要版本控制系统干什么。版本控制系统肯定有某个命令可以告诉我们历史记录,在Git中,我们用git log命令查看:
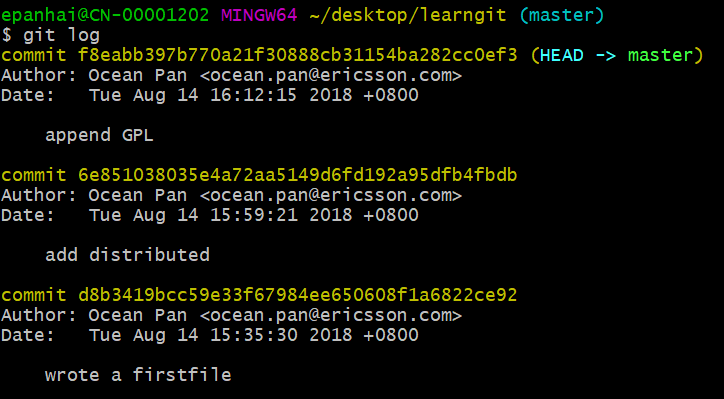
git log命令显示从最近到最远的提交日志,我们可以看到3次提交,最近的一次是append GPL,上一次是add distributed,最早的一次是wrote firstfile。
如果嫌输出信息太多,看得眼花缭乱的,可以试试加上--pretty=oneline参数:

需要友情提示的是,你看到的一大串类似1094adb...的是commit id(版本号),和SVN不一样,Git的commit id不是1,2,3……递增的数字,而是一个SHA1计算出来的一个非常大的数字,用十六进制表示,而且你看到的commit id和我的肯定不一样,以你自己的为准。为什么commit id需要用这么一大串数字表示呢?因为Git是分布式的版本控制系统,后面我们还要研究多人在同一个版本库里工作,如果大家都用1,2,3……作为版本号,那肯定就冲突了。
每提交一个新版本,实际上Git就会把它们自动串成一条时间线.
13.好了,现在我们启动时光穿梭机,准备把firstfile回退到上一个版本,也就是add distributed的那个版本,怎么做呢?
首先,Git必须知道当前版本是哪个版本,在Git中,用HEAD表示当前版本,也就是最新的提交1094adb...(注意我的提交ID和你的肯定不一样),上一个版本就是HEAD^,上上一个版本就是HEAD^^,当然往上100个版本写100个^比较容易数不过来,所以写成HEAD~100。
现在,我们要把当前版本append GPL回退到上一个版本add distributed,就可以使用git reset命令:

可以看到 head 当前指向 6e85103 版本,即 add distributed 版本。
看看 firstfile 的内容是不是版本add distributed:

果然被还原了。
还可以继续回退到上一个版本wrote firstfile,不过且慢,然我们用git log再看看现在版本库的状态.
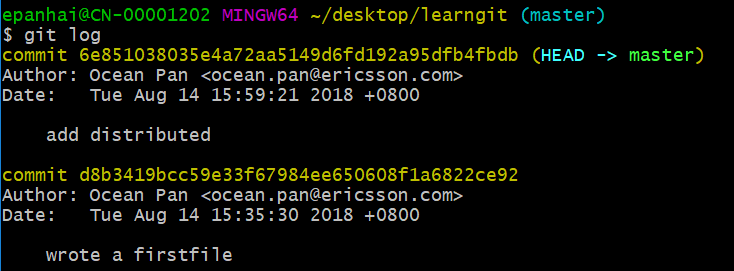
最新的那个版本append GPL已经看不到了!git log只能查看当前版本到之前版本的所有提交历史。
现在假设你想再回到 append GPL版本,肿么办。好比你从21世纪坐时光穿梭机来到了19世纪,想再回去已经回不去了,肿么办?
办法其实还是有的,只要上面的命令行窗口还没有被关掉,你就可以顺着往上找啊找啊,找到那个append GPL的commit id是f8eabb...,于是就可以指定回到未来的某个版本:

版本号没必要写全,前几位就可以了,Git会自动去找。当然也不能只写前一两位,因为Git可能会找到多个版本号,就无法确定是哪一个了。
再小心翼翼地看看 firstfile 的内容:


然后顺便把工作区的文件更新了。所以你让HEAD指向哪个版本号,你就把当前版本定位在哪。
现在,你回退到了某个版本,关掉了电脑,第二天早上就后悔了,想恢复到新版本怎么办?找不到新版本的commit id怎么办?
在Git中,总是有后悔药可以吃的。当你用$ git reset --hard HEAD^回退到add distributed版本时,再想恢复到append GPL,就必须找到append GPL的commit id。Git提供了一个命令git reflog用来记录你的每一次命令.
假设你现在处于 add distributed 版本,git log 只能显示当前版本到之前本版本的所有提交历史;git reflog 可以用来记录你的每一次命令:

终于舒了口气,从输出可知,append GPL的commit id是f8eabb3,然后通过命令 git reset --hard f8eabb3, 现在你又可以乘坐时光机回到未来了

14.我们继续修改firstfile
Git is a distributed version control system. Git is free software distributed under the GPL. Git tracks changes.
然后: git add firstfile
然后继续修改firstfile
Git is a distributed version control system. Git is free software distributed under the GPL. Git tracks changes
Git tracks changes of files
然后: git commit -m "revise-add-revise-commit"
然后git status

咦,怎么第二次的修改没有被提交?
别激动,我们回顾一下操作过程:
第一次修改 -> git add -> 第二次修改 -> git commit
你看,我们前面讲了,Git管理的是修改,当你用git add命令后,在工作区的第一次修改被放入暂存区,准备提交,但是,在工作区的第二次修改并没有放入暂存区,所以,git commit只负责把暂存区的修改提交了,也就是第一次的修改被提交了,第二次的修改不会被提交.
那怎么提交第二次修改呢?你可以继续git add再git commit,也可以别着急提交第一次修改,先git add第二次修改,再git commit,就相当于把两次修改合并后一块提交了:
第一次修改 -> git add -> 第二次修改 -> git add -> git commit
好,现在,把第二次修改提交了,然后开始小结。
现在,你又理解了Git是如何跟踪修改的,每次修改,如果不用git add到暂存区,那就不会加入到commit中。
假设现在创建文件 test.
git add test git commit -m "create test file"
后面我们删除了工作区的test文件
rm test
这个时候,Git知道你删除了文件,因此,工作区和版本库就不一致了,git status命令会立刻告诉你哪些文件被删除了。
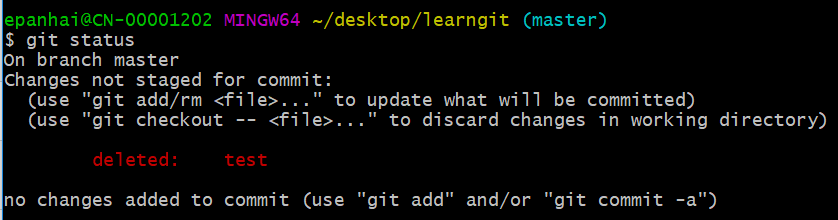
可以看到test文件被删除,然后这次修改没有加到暂存区。
现在你有两个选择,一是确实要从版本库中删除该文件,那就用命令git rm删掉,并且git commit:
$ git rm test git commit -m "git rm test file"
我们再查看一下状态

可以看到工作区是干净的。
另一种情况是删错了,因为版本库里还有呢,所以可以很轻松地把误删的文件恢复到最新版本:
$ git checkout -- test.txt
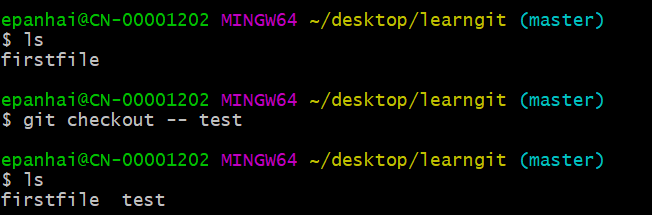
git checkout其实是用版本库里的版本替换工作区的版本,无论工作区是修改还是删除,都可以“一键还原”。
命令git rm用于删除一个文件。如果一个文件已经被提交到版本库,那么你永远不用担心误删,但是要小心,你只能恢复文件到最新版本,你会丢失最近一次提交后你修改的内容。

