向量化——>Word2Vec神经网络
---恢复内容开始---
关于W2V:简单的做个笔记
TF-IDF ——> BM25
Co-Occurrence ——> Word2Vec
w2v主流的两种实现算法:
1.CBOW :周围词预估中心词
缺点:每个周围词学习效果相对差一些
2.Skip-Gram :中心词预估周围词
优点:学习效果好
缺点:学习速度慢
Skip-Gram 是 CBOW 的网络翻转
Cbow训练速度快,Skip-Gram更好处理生僻字
学习目标:Word Embedding(词向量)
学习不是为了准确的预估正确的中心词/周围词,而是为了 word——>vector
onehotb编码
Hidden layer 隐藏层概念
- w1 -> v
- w2 -> v
- w3 -> v
- w4 -> v 随机初始化
w1,w2,w3,w4 =>avg -> vector -> Hidden(高维度)·(特征抽取) -> vec -> softmax -> 中心词
基于DNN
多分类问题?
w1 w2 w3 w4 w5
中心词
w3 w1 w2 w4 w5
Y x1 x2 x3 x4
label
窗口概念
Hierarchinal softmax 分层softmax:
Negative sampling 负采样(采集负样本)
Hierarchinal softmax:
问题:Hidden layer(隐藏层)到输出的softmax层的计算量很大
改进:
1.word average
—对所有输入词向量求和并取平均值
2.哈弗曼树
—避免要计算所有词的softmax概率,提高速度
AACBCAADBAAB
等长编码:
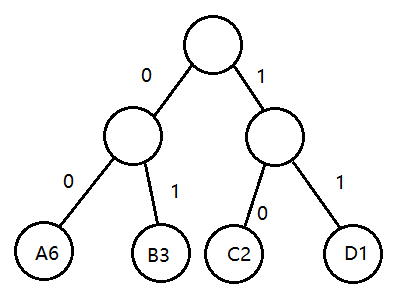
A:00 B:01 C:10 D:11
00 00 10 01 10 00 00 11 01 00 00 01 =24位
哈夫曼编码:
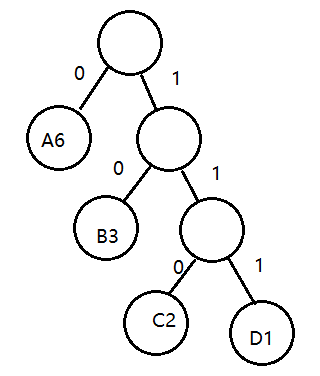
A:0 B:10 C:110 D:111
0 0 110 10 110 0 0 111 10 0 0 10 =21位
单词权重:权重 => 词频 (TF)
希望高频词越靠近根节点
之前:每个单词都要算
现在:与每个中间节点算一次 lr (加速)
* lr => 神经网络运算得到
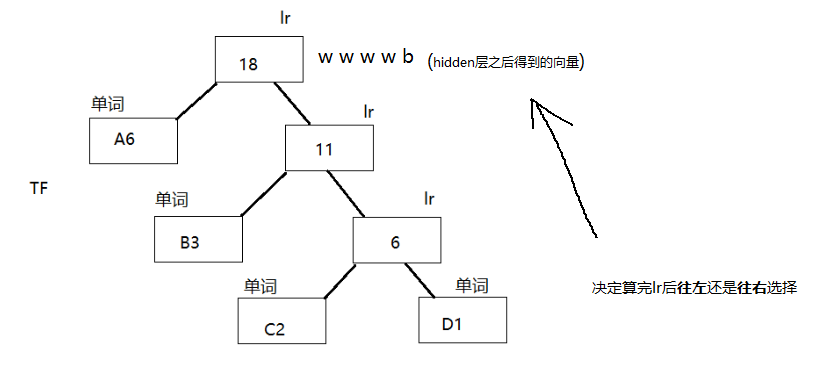
优点: 1.计算量降低 V => log2V
2.高频词靠近树根,更少时间会被找到,符合贪心思想
负采样:
高频词/长尾词 w1 w2 w3 w4
越长:次数越多 (排序:从小到大)
随机采样:词频越高被采出概率越高
保持数据同分布:采样出的样本(label),保持和数据分布式一致。高频词出现负样本的概率更大,低频词出现的概率更小。(侧重点不一样,高频词的学习程度强,低频词的学习程度弱)
重复采样:加大高频词的学习
采到正样本 => 噪音的存在 => 模型泛化能力更强
