
从缓存行出发理解volatile变量、伪共享False sharing、disruptor
备注,现在已经进入多核时代了,考虑问题要考虑多核啊
volatile关键字
当变量被某个线程A修改值之后,其它线程比如B若读取此变量的话,立刻可以看到原来线程A修改后的值
注:普通变量与volatile变量的区别是volatile的特殊规则保证了新值能立即同步到主内存,以及每次使用前可以立即从内存刷新,即一个线程修改了某个变量的值,其它线程读取的话肯定能看到新的值;
普通变量:
写命中:当处理器将操作数写回到一个内存缓存的区域时,它首先会检查这个缓存的内存地址是否在缓存行中,如果不存在一个有效的缓存行,则处理器将这个操作数写回到缓存,而不是写回到内存,这个操作被称为写命中。
|
术语 |
英文单词 |
描述 |
|
共享变量 |
在多个线程之间能够被共享的变量被称为共享变量。共享变量包括所有的实例变量,静态变量和数组元素。他们都被存放在堆内存中,Volatile只作用于共享变量。 |
|
|
内存屏障 |
Memory Barriers |
是一组处理器指令,用于实现对内存操作的顺序限制。 备注: In the Java Memory Model a volatile field has a store barrier inserted after a write to it and a load barrier inserted before a read of it. |
|
缓冲行 |
Cache line |
缓存中可以分配的最小存储单位。处理器填写缓存线时会加载整个缓存线,需要使用多个主内存读周期。 |
|
原子操作 |
Atomic operations |
不可中断的一个或一系列操作。 |
|
缓存行填充 |
cache line fill |
当处理器识别到从内存中读取操作数是可缓存的,处理器读取整个缓存行到适当的缓存(L1,L2,L3的或所有) |
|
缓存命中 |
cache hit |
如果进行高速缓存行填充操作的内存位置仍然是下次处理器访问的地址时,处理器从缓存中读取操作数,而不是从内存。 |
|
写命中 |
write hit |
当处理器将操作数写回到一个内存缓存的区域时,它首先会检查这个缓存的内存地址是否在缓存行中,如果不存在一个有效的缓存行,则处理器将这个操作数写回到缓存,而不是写回到内存,这个操作被称为写命中。 |
|
写缺失 |
write misses the cache |
一个有效的缓存行被写入到不存在的内存区域。 |
单核CPU缓存结构

单核CPU缓存
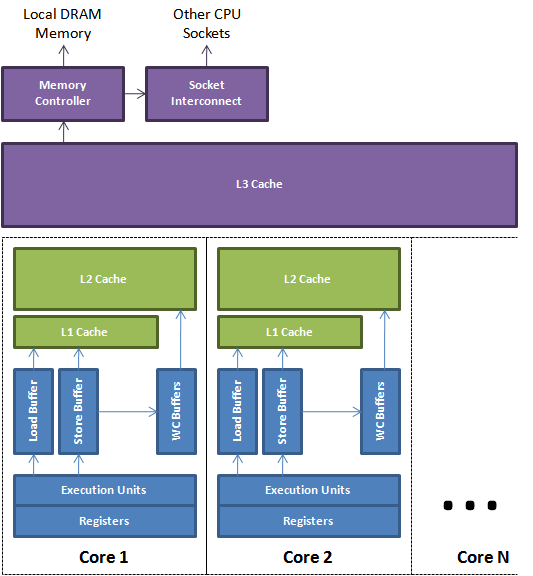
多核CPU缓存
所谓缓存航就是缓存中可以分配的最小存储单位。
处理器填写缓存线时会加载整个缓存线,需要使用多个主内存读周期。
下面降到伪缓存时会介绍,多核CPU、内存的缓存系统;
Information transfer between the cache and the memory is in terms of complete cache lines, rather than individual bytes. Thus if the program needs a particular byte, the entire cache line containing that byte is obtained from the memory. For example, suppose that the cache of Figure 2 was being used and the program fetches the word (two bytes) at location 0004736. If none of the cache lines contain the 16 bytes stored in addresses 0004730 through 000473F, then these 16 bytes are transferred from the memory to one of the cache lines. Because of the spatial locality of the program, we expect that other values in the cache line thus loaded will be referenced in the near future.
Volatile的实现原理
那么Volatile是如何来保证可见性的呢?在x86处理器下通过工具获取JIT编译器生成的汇编指令来看看对Volatile进行写操作CPU会做什么事情。
|
Java代码: |
instance = new Singleton();//instance是volatile变量 |
|
汇编代码: |
0x01a3de1d: movb $0x0,0x1104800(%esi); 0x01a3de24: lock addl $0x0,(%esp); |
有volatile变量修饰的共享变量进行写操作的时候会多第二行汇编代码,通过查IA-32架构软件开发者手册可知,lock前缀的指令在多核处理器下会引发了两件事情
- 将当前处理器缓存行的数据会写回到系统内存。
- 这个写回内存的操作会引起在其他CPU里缓存了该内存地址的数据无效。
Lock前缀指令会引起处理器缓存回写到内存。Lock前缀指令导致在执行指令期间,声言处理器的 LOCK# 信号。在多处理器环境中,LOCK# 信号确保在声言该信号期间,处理器可以独占使用任何共享内存。(因为它会锁住总线,导致其他CPU不能访问总线,不能访问总线就意味着不能访问系统内存),但是在最近的处理器里,LOCK#信号一般不锁总线,而是锁缓存,毕竟锁总线开销比较大。在8.1.4章节有详细说明锁定操作对处理器缓存的影响,对于Intel486和Pentium处理器,在锁操作时,总是在总线上声言LOCK#信号。但在P6和最近的处理器中,如果访问的内存区域已经缓存在处理器内部,则不会声言LOCK#信号。相反地,它会锁定这块内存区域的缓存并回写到内存,并使用缓存一致性机制来确保修改的原子性,此操作被称为“缓存锁定”,缓存一致性机制会阻止同时修改被两个以上处理器缓存的内存区域数据。
一个处理器的缓存回写到内存会导致其他处理器的缓存无效。IA-32处理器和Intel 64处理器使用MESI(修改,独占,共享,无效)控制协议去维护内部缓存和其他处理器缓存的一致性。在多核处理器系统中进行操作的时候,IA-32 和Intel 64处理器能嗅探其他处理器访问系统内存和它们的内部缓存。它们使用嗅探技术保证它的内部缓存,系统内存和其他处理器的缓存的数据在总线上保持一致。例如在Pentium和P6 family处理器中,如果通过嗅探一个处理器来检测其他处理器打算写内存地址,而这个地址当前处理共享状态,那么正在嗅探的处理器将无效它的缓存行,在下次访问相同内存地址时,强制执行缓存行填充。
Volatile的使用优化
著名的Java并发编程大师Doug lea在JDK7的并发包里新增一个队列集合类LinkedTransferQueue,他在使用Volatile变量时,用一种追加字节的方式来优化队列出队和入队的性能。
追加字节能优化性能?这种方式看起来很神奇,但如果深入理解处理器架构就能理解其中的奥秘。让我们先来看看LinkedTransferQueue这个类,它使用一个内部类类型来定义队列的头队列(Head)和尾节点(tail),而这个内部类PaddedAtomicReference相对于父类AtomicReference只做了一件事情,就将共享变量追加到64字节。我们可以来计算下,一个对象的引用占4个字节,它追加了15个变量共占60个字节,再加上父类的Value变量,一共64个字节。
为什么追加64字节能够提高并发编程的效率呢? 因为对于英特尔酷睿i7,酷睿, Atom和NetBurst, Core Solo和Pentium M处理器的L1,L2或L3缓存的高速缓存行是64个字节宽,不支持部分填充缓存行,这意味着如果队列的头节点和尾节点都不足64字节的话,处理器会将它们都读到同一个高速缓存行中,在多处理器下每个处理器都会缓存同样的头尾节点,当一个处理器试图修改头接点时会将整个缓存行锁定,那么在缓存一致性机制的作用下,会导致其他处理器不能访问自己高速缓存中的尾节点,而队列的入队和出队操作是需要不停修改头接点和尾节点,所以在多处理器的情况下将会严重影响到队列的入队和出队效率。Doug lea使用追加到64字节的方式来填满高速缓冲区的缓存行,避免头接点和尾节点加载到同一个缓存行,使得头尾节点在修改时不会互相锁定。
那么是不是在使用Volatile变量时都应该追加到64字节呢?不是的。在两种场景下不应该使用这种方式。第一:缓存行非64字节宽的处理器,如P6系列和奔腾处理器,它们的L1和L2高速缓存行是32个字节宽。第二:共享变量不会被频繁的写。因为使用追加字节的方式需要处理器读取更多的字节到高速缓冲区,这本身就会带来一定的性能消耗,共享变量如果不被频繁写的话,锁的几率也非常小,就没必要通过追加字节的方式来避免相互锁定。
/** head of the queue */
private transient final PaddedAtomicReference < QNode > head;
/** tail of the queue */
private transient final PaddedAtomicReference < QNode > tail;
static final class PaddedAtomicReference < T > extends AtomicReference < T > {
// enough padding for 64bytes with 4byte refs
Object p0, p1, p2, p3, p4, p5, p6, p7, p8, p9, pa, pb, pc, pd, pe;
PaddedAtomicReference(T r) {
super(r);
}
}
public class AtomicReference < V > implements java.io.Serializable {
private volatile V value;
}
为什么追加64字节能够提高并发编程的效率呢? 因为对于英特尔酷睿i7,酷睿, Atom和NetBurst, Core Solo和Pentium M处理器的L1,L2或L3缓存的高速缓存行是64个字节宽,不支持部分填充缓存行,这意味着如果队列的头节点和尾节点都不足64字节的话,处理器会将它们都读到同一个高速缓存行中,在多处理器下每个处理器都会缓存同样的头尾节点,当一个处理器试图修改头接点时会将整个缓存行锁定,那么在缓存一致性机制的作用下,会导致其他处理器不能访问自己高速缓存中的尾节点,而队列的入队和出队操作是需要不停修改头接点和尾节点,所以在多处理器的情况下将会严重影响到队列的入队和出队效率。Doug lea使用追加到64字节的方式来填满高速缓冲区的缓存行,避免头接点和尾节点加载到同一个缓存行,使得头尾节点在修改时不会互相锁定。
那么是不是在使用Volatile变量时都应该追加到64字节呢?不是的。在两种场景下不应该使用这种方式。第一:缓存行非64字节宽的处理器,如P6系列和奔腾处理器,它们的L1和L2高速缓存行是32个字节宽。第二:共享变量不会被频繁的写。因为使用追加字节的方式需要处理器读取更多的字节到高速缓冲区,这本身就会带来一定的性能消耗,共享变量如果不被频繁写的话,锁的几率也非常小,就没必要通过追加字节的方式来避免相互锁定。
Java并发编程实践写道:“一个理解volatile变量好的方法:想想它们的行为与SynchrosizedInteger类相似,只不过用get和set方法取代了对volatile变量的读写操作。然而访问volatile变量的操作不会加锁,也就不会引起线程的阻塞,这使volatile相对于synchronized而言,只是轻量级的同步机制”
false-sharing
Memory is stored within the cache system in units know as cache lines. Cache lines are a power of 2 of contiguous bytes which are typically 32-256 in size. The most common cache line size is 64 bytes. False sharing is a term which applies when threads unwittingly impact the performance of each other while modifying independent variables sharing the same cache line. Write contention on cache lines is the single most limiting factor on achieving scalability for parallel threads of execution in an SMP system. I’ve heard false sharing described as the silent performance killer because it is far from obvious when looking at code.
class {int x ,int y} x和y被放在同一个高速缓存区,如果一个线程修改x;那么另外一个线程修改y,必须等待x修改完成后才能实施。

L1 Cache(一级缓存)是CPU第一层高速缓存,分为数据缓存和指令缓存。内置的L1高速缓存的容量和结构对CPU的性能影响较大,不过高速缓冲存储器均由静态RAM组成,结构较复杂,在CPU管芯面积不能太大的情况下,L1级高速缓存的容量不可能做得太大。一般服务器CPU的L1缓存的容量通常在32—4096KB。
L2 Cache 都在CPU中
L3 Cache(三级缓存),分为两种,早期的是外置,现在的都是内置的。而它的实际作用即是,L3缓存的应用可以进一步降低内存延迟,同时提升大数据量计算时处理器的性能。降低内存延迟和提升大数据量计算能力对游戏都很有帮助。而在服务器领域增加L3缓存在性能方面仍然有显著的提升。比方具有较大L3缓存的配置利用物理内存会更有效,故它比较慢的磁盘I/O子系统可以处理更多的数据请求。具有较大L3缓存的处理器提供更有效的文件系统缓存行为及较短消息和处理器队列长度。
从图中可以看出为多核共享的
To achieve linear scalability with number of threads, we must ensure no two threads write to the same variable or cache line. Two threads writing to the same variable can be tracked down at a code level. To be able to know if independent variables share the same cache line we need to know the memory layout, or we can get a tool to tell us. Intel VTune is such a profiling tool. In this article I’ll explain how memory is laid out for Java objects and how we can pad out our cache lines to avoid false sharing.
可见每个cpu核心或者线程都会可能往同一个缓存行写数据;并且对共享变量,同时cpu核心会有各自的缓存行
虽然两个线程修改各种独立变量,但是因为这些独立变量被放在同一个高速缓存区,性能就影响了。测试结果。
当多核CPU线程同时修改在同一个高速缓存行各自独立的变量时,会不自不觉地影响性能,这就发生了伪共享False sharing,伪共享是性能的无声杀手。
当多核CPU线程同时修改在同一个高速缓存行各自独立的变量时,会不自不觉地影响性能,这就发生了伪共享False sharing,伪共享是性能的无声杀手。
这里强调多核,是因为单核CPU模拟出的多线程不会严格意义上同时访问缓存行,所以性能影响不大
解决方便是将高速缓存剩余的字节填充填满(pad),确保不发生多个字段被挤入一个高速缓存区,下面测试结果图就是和填充后性能比较。
实现字节填充的框架有 Disruptor,在RingBuffer中实现填充。关于Disruptor可见infoQ这个视频,用1毫秒的延时得到100K+ TPS吞吐量,
JDK的ArrayQueue并行环境不见得是最快的,该视频后面讨论很多,让人大跌眼镜啊,开放源码多有好处啊,别人能发现你不能发现的漏洞。
Disruptor
Disruptor没有像JDK的LinkedBlockQueue等那样使用锁,针对CPU高速缓存进行了优化。
原来我们以为多个线程同时写一个类的字段会发生争夺,这是多线程基本原理,所以使用了锁机制,保证这个共用字段(资源)能够某个时刻只能一个线程写,但是这样做的坏处是:有可能发生死锁。
比如1号线程先后访问共享资源A和B;而2号线程先后访问共享资源B和A,因为在资源A和资源B都有锁,那么1号在访问资源A时,资源A上锁了,准备访问资源B,但是无法访问,因为与此同时;而2号线程在访问资源B,资源B锁着呢,正准备访问资源A,发现资源A被1号线程锁着呢,结果彼此无限等待彼此下去,死锁类似逻辑上自指悖论。
所以,锁是坏的,破坏性能,锁是并发计算的大敌。
我们回到队列上,一把一个队列有至少两个线程:生产者和消费者,这就具备了资源争夺的前提,这两个线程一般彼此守在队列的进出两端,表面上好像没有访问共享资源,实际上队列存在两个共享资源:队列大小或指针.
除了共享资源写操作上存在资源争夺问题外,Disruptor的LMAX团队发现Java在多核CPU情况下有伪共享问题:
CPU会把数据从内存加载到高速缓存中 ,这样可以获得更好的性能,高速缓存默认大小是64 Byte为一个区域,CPU机制限制只能一个CPU的一个线程访问(写)这个高速缓存区。
CPU在将主内存中数据加载到高速缓冲时,如果发现被加载的数据不足64字节,那么就会加载多个数据,以填满自己的64字节,悲催就发生了,恰恰hotspot JVM中对象指针等大小都不会超过64字节,这样一个高速缓冲中可能加载了两个对象指针,一个CPU一个高速缓冲,双核就是两个CPU各自一个高速缓冲,那么两个高速缓冲中各有两个对象指针,都是指向相同的两个对象。
因为一个CPU只能访问(写)自己高速缓存区中数据,相当于给这个数据加锁,那么另外一个CPU同时访问自己高速缓冲行中同样数据时将会被锁定不能访问。
这就发生与锁机制类似的性能陷进,Disruptor的解决办法是填满高速缓冲的64字节,不是对象指针等数据不够64字节吗?那么加一些字节填满64字节,这样CPU将数据加载到高速缓冲时,就只能加载一个了,刚刚好啊。
所以,尽管两个线程是在写两个不同的字段值,也会因为双核CPU底层机制发生伪装的共享,并没有真正共享,其实还是排他性的独享。
现在我们大概知道RingBuffer是个什么东东了:
1.ring buffer是一个大的数组.
2.RingBuffer里所有指针都是Java longs (64字节) 不断永远向前计数,如后面图,不断在圆环中循环。
3.RingBuffer只有当前序列号,没有终点序列号,其中数据不会被取出后消除,这样以便实现从过去某个序列号到当前序列号的重放,这样当消费者说没有接受到生产者发送的消息,生产者还可以再次发送,这点是一种原子性的“事务”机制。
This new pattern is an ideal foundation for any asynchronous event processing architecture where high-throughput and low-latency is required.
Concurrent execution of code is about two things, mutual exclusion and visibility of change.
Read and write operations require that all changes are made visible to other threads. However only contended write operations require the mutual exclusion of the changes.
Locks provide mutual exclusion and ensure that the visibility of change occurs in an ordered manner. Locks are incredibly expensive because they require arbitration when contended.
We will illustrate the cost of locks with a simple demonstration. The focus of this experiment is to call a function which increments a 64-bit counter in a loop 500 million times. This can be executed by a single thread on a 2.4Ghz Intel Westmere EP in just 300ms if written in Java. The language is unimportant to this experiment and results will be similar across all languages with the same basic primitives.
Once a lock is introduced to provide mutual exclusion, even when the lock is as yet un-contended, the cost goes up significantly. The cost increases again, by orders of magnitude, when two or more threads begin to contend. The results of this simple experiment are shown in the table below

However CAS operations are not free of cost. The processor must lock its instruction pipeline to ensure atomicity and employ a memory barrier to make the changes visible to other threads. CAS operations are available in Java by using the java.util.concurrent.Atomic* classes.
The processors need only guarantee that program logic produces the same results regardless of execution order.
barriter:make the memory state within a processor visible to other processors.
disruptor 是为了解决消费者大于生产者的问题
参考
伪共享 :http://mechanical-sympathy.blogspot.com/2011/07/false-sharing.html
http://www.jdon.com/jivejdon/thread/42451#23138636
volatile:http://www.infoq.com/cn/articles/ftf-java-volatile
缓存行:http://ecee.colorado.edu/~ecen2120/Manual/caches/cache.html
disruptor:http://mechanitis.blogspot.com/2011/07/dissecting-disruptor-why-its-so-fast_22.html
源码:http://code.google.com/p/disruptor/
memory barrier 屏障:http://mechanical-sympathy.blogspot.com/2011/07/memory-barriersfences.html

