



20155339 2016-2017-2 《Java程序设计》第5周学习总结
20155339 2016-2017-2 《Java程序设计》第5周学习总结
教材学习内容总结
使用try、catch
- 使用try、catch语法,JVM会先尝试执行try区块中的代码,如果发生错误就会调理错误发生点,然后比较catch括号中声明类型是否符合被抛出的错误对象类型,如果是就执行catch区块中的代码。
- 有时错误可以在捕捉处理之后,尝试恢复程序正常执行流程。相关练习,链接运行结果如下图

异常继承架构
- 错误会被包装为对象,这些对象都是可抛出的。设计错误对象都继承自
java.lang.Throwable类,Throwable定义了取得错误信息、堆栈追踪等方法,它有两个子类:java.lang.Error与java.lang.Exception。 - Error与其子类实例代表严重系统错误,Java应用程序本身无力回复。
- 程序设计本身的错误,建议用Exception或其子类实例来表现,所以通常称错误处理为异常处理。如果某个声明方法会抛出Throeable或子类实例,只要不属于
Error或java.lang.RuntimeException或其子类实例,就必须明确使用try、catch语句加以处理,或用throws声明这个方法会抛出异常。 - API文档中带throws的必须使用try...catch。
- Error和RuntimeException及其子类称为非首检异常,其它异常称为受检异常。
- 如果父类异常对象在子类异常对象前被捕捉,则catch子类异常对象将永远不会被执行,编译程序会检查出这个错误。从JDK7开始,可以使用多重捕捉语法,不过仍需注意异常的继承,catch括号中列出的异常不得有继承关系,否则会发生编译错误。多重捕捉语法如下:
try{
做一些事儿...
}catch(IOException|InterruptedException|ClassCastException e){
e.printStackTrace();
}
catch or throw
- FileInputStream可以指定档名来开启与读取文档内容,但是在创建时会抛出FileNotFoundException错误。
- 操作对象的过程中如果会抛出受检异常,但目前环境信息不足以处理异常,无法使用try、catch处理时,需用throw声明此方法会抛出的异常类型或父类型。
- catch区块进行完部分错误处理后可以使用throw将异常再抛出。
自定义异常
让异常更能表现应用程序特有的错误信息,用以更精确地表示出未处理的错误。自定义异常类别时,可以继承Throwable、Error或Exception,通常建议继承自Exception或其子类。
认识堆栈追踪
- 若想得知异常发生的根源,以及多重方法调用下异常的堆栈传播,可以利用异常对象自动收集的堆栈追踪来取得相关信息。
- 查看堆栈追踪最简单的方法,就是直接调用异常对象的
printStackTrace()。堆栈追踪信息会显示异常类型,最顶层是异常的根源。 - 如果想要取得个别的堆栈追踪数据元素进行处理,则可以使用getStackTrace(),这会返回StackTraceElement数组,数组中索引0为异常根源的相关信息。
- 善用堆栈追踪错误,1.代码中不要私吞异常。2.不要错误处理异常。3.处理时不要显示错误信息。
- 可以使用
fillInStackTrace()方法,让异常堆栈起点为重抛异常的地方,并返回Throwable对象。 assert:断言动能,使用assert作为关键字,默认执行时不启动,若要启动,可以在执行java指令时指定-enableassertions或是-ea自变量。assert有两种使用语法:
1.assert boolean_expression,若为true,则什么都不发生,若为false则会发生java.lang.AssertionError
2.assert boolean_expression:detail_expression,若为false。则会将detail_expression的结果显示出来。
异常与资源管理
-
无论
try区块中有无发生异常,若有撰写finally区块,则finally区块一定会被执行。 -
如果撰写的流程中先
return后有finally区块,那finally区块会先执行完后再返回值。例如链接,运行结果如下图
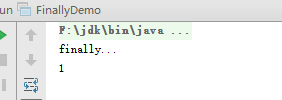
-
在JDK7之后,新增了尝试关闭资源语法。尝试自动关闭资源的对象撰写在try之后的括号中,如果无须catch处理任何异常可以不用撰写,也不用撰写finally自行尝试关闭资源。
-
尝试关闭资源语法可套用的对象必须操作
java.lang.AutoCloseable接口,同时关闭两个以上的对象资源时中间以分号间隔,越后面的越早被关闭。相关练习,链接,运行结果如下
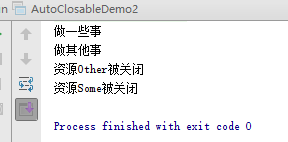
第九章 Collection与Map
认识collection架构
- 收集对象的行为,如新增对象的add()方法、移除对象的remove()方法等,都是定义在
java.util.Collection中。既然能收集对象,也能逐一取得对象,是java.lang.Iterable定义的行为。 - 根据对收集对象不同的需求,有以下几种收集方法:
1.收集时记录每个对象的索引顺序,并可依索引取回对象,此行为定义在java.util.List接口中;
2.手机的对象不重复,具有集合的行为,则由java.util.Set定义;
3.收集对象时以队列方式排列,收集的对象加入至尾端,取得对象时从前端,用java.util.Queue;对Queue的两端进行加入、移除等动作,用java.util.Deque。
List
- List是一种Collection,作用是收集对象,并以索引的方式保留收集的对象顺序,其操作之一是
java.util.ArrayList。 - ArrayList特性:ArrayList搜集对象时使用数组,由于数组在内存中是连续线性空间,根据索引随机存取时速度快,所以适合排序的时候用,可得到较好的速度表现。
- LinkedList特性:LinkedList采用了链接结构,每次新增对象后会形成链状结构,链接的每个元素会参考至下一个元素,有利于调整索引顺序,适用于需要经常变动索引的情况,但不适用于排序之类的情况。
Set
Queue
- Queue具有Collection的add()、remove()、element()等方法,同时也定义了自己的offer()、poll()与peek()等方法。最主要的差别在于,前者操作失败时会抛出异常,而后者操作失败会返回特定值。
- offer()用来在队列后端加入对象,成功返回true,失败返回false;poll()用来在队列前段取出对象,空是返回null,peek()用来取得队列前端的对象,空时童谣返回null。
- .Queue的子接口Deque在队列前端加入对象与取出对象,在队列尾端加入对象与取出对象。
java.util.ArrayDeque操作了Deque接口。
使用泛型
- 设计API时可以指定类或方法支持泛型,会使客户端在语法上更为简洁,并得到编译时期检查。
- 声明与建立对象时使用角括号告知编译程序,只要声明参考时有指定类型,创建对象时就不用再写了。例如
ArrayList<String> names=new ArrayList<>(); - 泛型也可以仅仅定义在方法上,最常见的是在静态方法是定义泛型。
Lambda表达式
- 相对于匿名类语法来说,Lambda表达式的语法省略了接口类型和方法名称。—>左边是参数列,以及在()中声明穿的参数类型及其本身,右边是方法本体。
- 当流程较为复杂时,可以用{}包括演算流程,如果方法必须返回值,在区块中就必须使用return。相关练习,链接,运行结果如下图

Iterable与Iterator
iterator()方法:返回java.util.Iterator接口的操作对象,包括了Collection收集的所有对象,利用iterator.hasNext()看看有无下一对象,用iterator.next()取得下一对象。- 在JDK5之后有了增强式for循环,增强式for循环可以运用在操作Iterable接口的对象上。JDK8演进了interface语法,允许接口定义默认方法。
java.util.Arrays的static方法asList()方法接受不定长度自变量,可将指定的自变量收集为List。
Comparable与Comparator
-
sort()方法可以进行排序算法,由于必须有索引才能进行排序,因此Collection的sort()方法接受List操作。
-
Collection的sort()方法需要操作
java.lang.Comparable,这个接口有个compareTo()方法需要返回大于0、等于0或小于0的数。 -
Collections的sort()方法有另一个重载版本,可接受java.util.Comparator接口的操作对象,如果使用这个版本,排序方式将根据Comparator的compare()定义来决定。例如,链接,运行结果如下
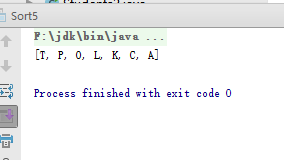
-
在java中与顺序有关的行为,通常要不对象本身是Comparable,要不就是另行制定Comparator对象告知如何排序。
Map
- 常用的Map操作类为java.util.HashMap与java.util.TreeMap,其继承自抽象类java.util.AbstractMap。Map支持泛型语法,建立Map操作对象时,可以使用泛型语法指定键与值的类型。
- 在
hashMap中建立键值对应后,键是无序的。使用TreeMap建立键值对应,则键的部分将会排序,条件是作为键的对象必须操作Comparable接口,或者是在建立TreeMap时指定操作Comparator接口的对象。 - properties也有map的行为,但一般常用Properties的setProperty()指定字符串类型的键值,getProperty指定字符串类型的键,取回字符串类型的值,通常称为属性名称和属性值。
- properties的=左边设定属性名称,右边设定属性值。可以使用Properties的load()方法指定InputStream的实例。
访问Map键值
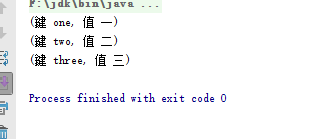
- 如果想取得Map中所有的键,可以调用Map的keySet() 返回Set对象。若想取得Map中所有的值,则可以使用values()返回collection对象。
- 如果想同时取得Map的键与值,可以使用entrySet()方法,会返回一个Set对象,每个元素都是Map.Entry实例,可以调用getKey()取得键,调用getValue()取得值。相关练习,链接,运行结果如下图
教材学习中的问题和解决过程
-
1.在学习书上的第一段代码时,发现前面已经定义的number,在后面想操作的时候却提示出错了,如下图

-
在认真的研究了程序的功能后发现自己误需要在将while中运行的内容,写到了外面,从而明白了在循环或者条件语句里面定义的变量,当你到了该语句外面还想再用他的时候只能重新定义,而且它不保存之前所存储过的内容,对上面的错误不针对该题的解决方法应该是在while外部定义number,或者在内部定义完之后,如果到了外部还需要使用,应该再定义一次。
-
2
text.append(a.nextLine())这段代码中append()是什么用途呢? -
解决:参考教材,上网查询后知道了append()是个方法,是往动态字符串数组添加,跟“xxxx”+“yyyy”相当那个‘+’号 。
-
3.hashSet是怎么判断元素是否重复呢?
-
解决:在网上查找得到答案:是根据元素继承的两个方法来判断,hashCode和equals,当存储元素时,首先判断要存入的元素和已存在的元素的哈希值是否相同,若不相同存入,若相同则利用equals判断两个元素是否相同,若不相同,则存入,若相同则放弃。而hashCode和equlas是在存入元素自动调用的。
代码调试中的问题和解决过程
-
1.在学习finally的用法时,练习书上的代码,总是出现如下图的错误
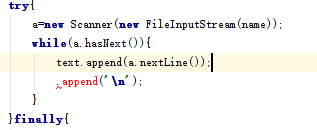
-
解决:仔细查看代码,发现是多了个分号,如下
text.append(a.nextLine());
.append('\n');
修改后应该是
text.append(a.nextLine())
.append('\n');
对于这个的理解我觉得应该是在text中加上用户输入的内容之后再换行,也就是与下面的代码意义相同。
text.append(a.nextLine());
text.append('\n');
-
2.学习书上的关于LinkedList的特性时,练习书上的代码,总会出现如下的错误
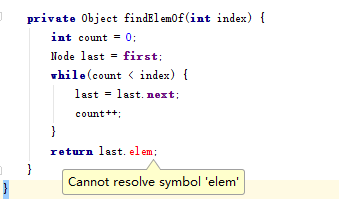
-
解决:尚未解决。
-
3.在学习Set时,练习书上的代码出现如下的错误
-
解决:将set改为students即可运行成功。
-
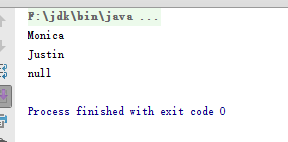
4.在学习Queue的Deque时,学习了书上的代码,链接,书上新建的Stack对象的容量是5,因此可以把输入的三个值都表示出来,但是如果容量是2,却输入了三个值,又因为堆栈是先入后出的,那么应该是前两个显示出来,还是后两个呢?
-
解决:编程实验,发现只有前两个输进去的才会遵循先进后出的原则,正确显示出来,而第三个因为是由poolLast(),则显示空,代码及运行截图如下
public static void main(String[] args) {
Stack stack = new Stack(2);
stack.push("Justin");
stack.push("Monica");
stack.push("Irene");
out.println(stack.pop());
out.println(stack.pop());
out.println(stack.pop());
}
代码托管
-
代码提交过程截图:

-
代码量截图:

上周考试错题总结
- 使用JDB进行调试时查看源代码的命令是(list)。
- 分析:对JDB的命令不够熟悉。相关内容可以看这篇文章。
- System.out.println( “HELLO”.( toLowerCase() ) ) 会输出“hello”。
- 分析:toLowerCase()方法会返回一个字符串,该字符串中的字母被转换为小写字母。
- ”Hello”.substring( 0,2 )的值是“He”
- 分析:substring()方法用于提取字符串中介于两个指定下标之间的字符。
- 父类的protected方法,在子类中可以override为public的方法。
- 实现一个类中的equals()方法时,一定要同时实现(hashCode())方法。
- 面向对象中,设计经验可以用(设计模式)表达。
结对及互评
评分标准
-
正确使用Markdown语法(加1分):
- 不使用Markdown不加分
- 有语法错误的不加分(链接打不开,表格不对,列表不正确...)
- 排版混乱的不加分
-
模板中的要素齐全(加1分)
- 缺少“教材学习中的问题和解决过程”的不加分
- 缺少“代码调试中的问题和解决过程”的不加分
- 代码托管不能打开的不加分
- 缺少“结对及互评”的不能打开的不加分
- 缺少“上周考试错题总结”的不能加分
- 缺少“进度条”的不能加分
- 缺少“参考资料”的不能加分
-
教材学习中的问题和解决过程, 一个问题加1分
-
代码调试中的问题和解决过程, 一个问题加1分
-
本周有效代码超过300分行的(加2分)
- 一周提交次数少于20次的不加分
-
其他加分:
- 周五前发博客的加1分
- 感想,体会不假大空的加1分
- 排版精美的加一分
- 进度条中记录学习时间与改进情况的加1分
- 有动手写新代码的加1分
- 课后选择题有验证的加1分
- 代码Commit Message规范的加1分
- 错题学习深入的加1分
-
扣分:
- 有抄袭的扣至0分
- 代码作弊的扣至0分
点评模板:
-
基于评分标准,我给本博客打分:10分。得分情况如下:1.正确使用Markdown语法(加1分),2.模板中的要素齐全(加1分),3. 教材学习中的问题和解决过程,一个问题加1分,4. 代码调试中的问题和解决过程, 一个问题加1分,5.本周有效代码超过300分行的(加2分),6.感想,体会不假大空的加1分,7.排版精美的加一分,8.进度条中记录学习时间与改进情况的加1分,9.错题学习深入的加1分。
点评过的同学博客和代码
其他(感悟、思考等,可选)
这次的相比较前几次的学习更有难度一些,所以画的时间也更多一些,通过这周的学习,明白了无论学什么不能想当然的把别的相类似的东西生搬硬套,这样很容易就酿下不容易寻找的错误。
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 20/20 | 1/4 | 20/20 | |
| 第二周 | 145/165 | 1/5 | 12/32 | |
| 第三周 | 411/576 | 1/6 | 16/48 | |
| 第四周 | 1021/1597 | 1/7 | 25/73 | |
| 第五周 | 1115/2712 | 1/8 | 28/103 |
尝试一下记录「计划学习时间」和「实际学习时间」,到期末看看能不能改进自己的计划能力。这个工作学习中很重要,也很有用。
耗时估计的公式
:Y=X+X/N ,Y=X-X/N,训练次数多了,X、Y就接近了。
-
计划学习时间:25小时
-
实际学习时间:28小时
-
改进情况:学习时间超出了预计的时间。

