昨天有幸拜读了蛙蛙池塘的《蛙蛙推荐:蛙蛙教你文本聚类》这篇文章,受益匪浅,于是今天就动手尝试照着他的C#代码,用C++和STL标准库重新实现一遍,因此就有了这篇文章。本文将重新温习蛙蛙池塘那篇文章,并且加入我个人在用C++重写这份代码过程中的一些心得体会。
源代码下载:TDIDF_Demo.rar
声明:本文代码思路完全来自蛙蛙池塘的博客,只为技术交流用途,无其他目的
昨天有幸拜读了蛙蛙池塘的《蛙蛙推荐:蛙蛙教你文本聚类》这篇文章,受益匪浅,于是今天就动手尝试照着他的C#代码,用C++和STL标准库重新实现一遍,因此就有了这篇文章。本文将重新温习蛙蛙池塘那篇文章,并且加入我个人在用C++重写这份代码过程中学到的一些知识。
TF-IDF(term frequency–inverse document frequency)
这是一种用于信息检索的一种常用加权技术。它是一种统计方法,用以评估一个字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
假如一篇文件的总词语数是100个,而词语“母牛”出现了3次,那么“母牛”一词在该文件中的词频就是 0.03 (3/100)。一个计算文件频率 (DF) 的方法是测定有多少份文件出现过“母牛”一词,然后除以文件集里包含的文件总数。所以,如果“母牛”一词在1,000份文件出现过,而文件总数是 10,000,000份的话,其文件频率就是 0.0001 (1000/10,000,000)。最后,TF-IDF分数就可以由计算词频除以文件频率而得到。以上面的例子来说,“母牛”一词在该文件集的TF- IDF分数会是 300 (0.03/0.0001)。这条公式的另一个形式是将文件频率取对数。
具体的计算原理,请参考维基百科tf–idf条目。下面简单介绍下基本的计算步骤:
1,文档预处理:1)文档分词;2)移除停用词;3)单词正规化处理
2,分出的单词就作为索引项(或单词表),它们代表的就是向量空间的项向量
3,计算项权值:这包括要计算1)词频 ; 2)倒排文件频率;3)TF-IDF权值
4,计算文档之间的相似度,一般用余弦相似度(cosine similarity)一同使用于向量空间模型中,用以判断两份文件之间的相似性
#include "ITokeniser.h"
#include <map>
class TFIDFMeasure
{
private:
StrVec _docs;//文档集合,每一行字符串代表一份文档
int _numDocs;//文档数目
int _numTerms;//单词数目
StrVec _terms;//单词集合
Int2DVec _termFreq;//每个单词出现在每份文档中的频率
Double2DVec _termWeight;//每个单词在每份文档的权重
IntVec _maxTermFreq;//记录每一份文档的最大词频
IntVec _docFreq;//出现单词的文档频率
ITokeniser* _tokenizer;//分词器
map<string,int> _wordsIndex;//单词映射表,保存每一个单词及其对应的下标
public:
TFIDFMeasure(const StrVec& documents,ITokeniser* tokeniser);
public:
~TFIDFMeasure(void);
protected:
void Init();//初始化TF-IDF计算器
void GenerateTerms(const StrVec& docs,StrVec& terms);//分词处理
void GenerateTermFrequency();//计算词频
void GenerateTermWeight();//计算词的权重
void GetWordFrequency(string& input,map<string,int>& freq); //实际统计词频函数
int CountWords(string& word, const StrVec& words);//统计词数
int GetTermIndex(const string& term);//查询词语对应的下标
double ComputeTermWeight(int term, int doc);//计算词语在指定文档中的权重值
double GetTermFrequency(int term, int doc);//获取词语在指定文档的词频
double GetInverseDocumentFrequency(int term);//计算倒排文件频率
public:
inline int NumTerms()const
{
return this->_numTerms;
}
void GetTermVector(int doc,DoubleVec& vec);//获取项向量
};

 TF-IDF具体实现代码
TF-IDF具体实现代码
#include "TFIDFMeasure.h"
#include <limits>
#include <cmath>
using namespace std;
TFIDFMeasure::~TFIDFMeasure(void)
{
//销毁分词器
if (this->_tokenizer!=NULL)
{
delete _tokenizer;
_tokenizer = NULL;
}
//清空数据
_docs.clear();
_terms.clear();
_wordsIndex.clear();
}
TFIDFMeasure::TFIDFMeasure(const StrVec& documents,ITokeniser* tokeniser)
{
_docs=documents;
_numDocs=documents.size();
_tokenizer = tokeniser;
this->Init();
}
void TFIDFMeasure::GenerateTerms(const StrVec& docs,StrVec& terms)
{
for (int i=0; i < docs.size() ; i++)
{
StrVec words;
_tokenizer->Partition(docs[i],words);//分词
for (int j=0; j < words.size(); j++)
{
//不在单词表中,则加入
if (find(terms.begin(),terms.end(),words[j])==terms.end())
{
terms.push_back(words[j]);
}
}
}
}
void TFIDFMeasure::Init()
{//初始化
this->GenerateTerms (_docs,_terms);//分出所有词项
this->_numTerms=_terms.size() ;//所有文档中的词项数目
//准备好存储空间
_maxTermFreq.resize(_numDocs);
_docFreq.resize(_numTerms);
_termFreq.resize(_numTerms);
_termWeight.resize(_numTerms);
for(int i=0; i < _terms.size() ; i++)
{
_termWeight[i].resize(_numDocs);
_termFreq[i].resize(_numDocs) ;
_wordsIndex[_terms[i]] = i;//将单词放入单词映射表中
}
this->GenerateTermFrequency ();//计算单词频率
this->GenerateTermWeight();//计算单词权重
}
void TFIDFMeasure::GetWordFrequency(string& input,map<string,int>& freq)
{//计算单词频率
transform(input.begin(),input.end(),input.begin(),tolower);
StrVec temp;
this->_tokenizer->Partition(input,temp);//对当前文档分词
unique(temp.begin(),temp.end());
StrVec::iterator iter;
for (iter=temp.begin();iter!=temp.end();++iter)
{
int count = CountWords(*iter, temp);//计算单词在文档中出现的次数
freq[*iter] = count;//保存单词频率
}
}
void TFIDFMeasure::GetTermVector(int doc,DoubleVec& vec)
{
vec.resize(this->_numTerms);
for (int i=0; i < this->_numTerms; i++)
vec[i]=_termWeight[i][doc];//第i个单词在文档doc中的权重
}
//用于字符串比较的仿函数
class WordComp
{
public:
WordComp(string& sWord) : word(sWord)
{
}
bool operator() (const string& lhs)
{
return lhs.compare(word)==0;
}
private:
string word;
};
int TFIDFMeasure::CountWords(string& word, const StrVec& words)
{
int nCount = 0;
nCount = count_if(words.begin(),words.end(),WordComp(word));
return nCount;
}
int TFIDFMeasure::GetTermIndex(const string& term)
{
map<string,int>::iterator pos = _wordsIndex.find(term);
if (pos!=_wordsIndex.end())
{
return pos->second;
}
else
return -1;
}
void TFIDFMeasure::GenerateTermFrequency()
{//计算每个单词在每份文档出现的频率
for(int i=0; i < _numDocs ; i++)
{
string curDoc=_docs[i];//当前待处理的文档
map<string,int> freq;
this->GetWordFrequency(curDoc,freq);
map<string,int>::iterator iter;
_maxTermFreq[i]=numeric_limits<int>::min();
for (iter = freq.begin();iter!=freq.end();++iter)
{
string word=iter->first;
int wordFreq=iter->second ;
int termIndex=GetTermIndex(word);//单词下标
if(termIndex == -1)
continue;
_termFreq [termIndex][i]=wordFreq;//单词在第i份文档中出现的频率
_docFreq[termIndex]++;//出现第termIndex单词的文档频率加
if (wordFreq > _maxTermFreq[i]) _maxTermFreq[i]=wordFreq;//记录第i份文档中的最大词频
}
}
}
void TFIDFMeasure::GenerateTermWeight()
{//计算每个单词在每份文档中的权重
for(int i=0; i < _numTerms; i++)
{
for(int j=0; j < _numDocs ; j++)
{
_termWeight[i][j]=ComputeTermWeight (i, j);
}
}
}
double TFIDFMeasure::GetTermFrequency(int term, int doc)
{
int freq=_termFreq [term][doc];//词频
int maxfreq=_maxTermFreq[doc];
return ( (float) freq/(float)maxfreq );
}
double TFIDFMeasure::ComputeTermWeight(int term, int doc)
{//计算单词在文档中的权重
float tf=GetTermFrequency (term, doc);
float idf=GetInverseDocumentFrequency(term);
return tf * idf;
}
double TFIDFMeasure::GetInverseDocumentFrequency(int term)
{
int df=_docFreq[term];//包含单词term的文档数目
return log((float) (_numDocs) / (float) df );
}
分词算法
为了便于使用不同的分词算法,我们定义一个抽象的分词算法接口,具体的分词算法由用户自行实现
class ITokeniser
{
public:
virtual void Partition(string input,StrVec& retWords)=0;//分词算法
};
这里只实现了一个最简单的空格符分词算法:
#include "Tokeniser.h"
#include "StopWordsHandler.h"
Tokeniser::Tokeniser(void)
{
}
Tokeniser::~Tokeniser(void)
{
}
void Tokeniser::Partition(string input,StrVec& retWords)
{//分词算法,input为输入串,retWords为处理后所分开的单词,这里就简单化处理了,以空格符为分隔符进行分词
transform(input.begin(),input.end(),input.begin(),tolower);
string::iterator start = input.begin();
string::iterator end = input.end();
StopWordsHandler stopHandler;
do
{
string temp;
pos = find(start,input.end(),' ');//找到分隔符
copy(start,end,back_inserter(temp));
if (!stopHandler.IsStopWord(temp))
{//不是停用词则保存
retWords.push_back(temp);//保存分出的单词
}
if (end == input.end())
{//最后一个单词了
break;
}
start = ++end;
} while (end != input.end());
}
停用词处理
去掉文档中无意思的词语也是必须的一项工作,这里简单的定义了一些常见的停用词,并根据这些常用停用词在分词时进行判断
#include "StopWordsHandler.h"
string stopWordsList[] ={"的", "我们","要","自己","之","将","“","”",",","(",")","后","应","到","某","后",
"个","是","位","新","一","两","在","中","或","有","更","好",""};//常用停用词
int stopWordsLen = sizeof(stopWordsList)/sizeof(stopWordsList[0]);
StopWordsHandler::StopWordsHandler(void)
{
for (int i=0;i<stopWordsLen;++i)
{
stopWords.push_back(stopWordsList[i]);
}
}
StopWordsHandler::~StopWordsHandler(void)
{
}
bool StopWordsHandler::IsStopWord(string& str)
{//是否是停用词
transform(str.begin(),str.end(),str.begin(),tolower);//确保小写化
return find(stopWords.begin(),stopWords.end(),str)!=stopWords.end();
}
K-Means算法
k-means 算法接受输入量 k ;然后将n个数据对象划分为 k个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。聚类相似度是利用各聚类中对象的均值所获得一个“中心对象”(引力中心)来进行计算的。
k-means 算法的工作过程说明如下:首先从n个数据对象任意选择 k 个对象作为初始聚类中心;而对于所剩下其它对象,则根据它们与这些聚类中心的相似度(距离),分别将它们分配给与其最相似的(聚类中心所代表的)聚类;然 后再计算每个所获新聚类的聚类中心(该聚类中所有对象的均值);不断重复这一过程直到标准测度函数开始收敛为止。一般都采用均方差作为标准测度函数. k个聚类具有以下特点:各聚类本身尽可能的紧凑,而各聚类之间尽可能的分开。
#include "Common.h"
class Cluster;
class KMeans
{
public:
vector<Cluster*> _clusters;//聚类
private:
int _coordCount;//数据的数量
Double2DVec _coordinates;//原始数据
int _k;//聚类的数量
//定义一个变量用于记录和跟踪每个资料点属于哪个群聚类
// _clusterAssignments[j]=i; 表示第j 个资料点对象属于第i 个群聚类
IntVec _clusterAssignments;
// 定义一个变量用于记录和跟踪每个资料点离聚类最近
IntVec _nearestCluster;
/// 定义一个变量,来表示资料点到中心点的距离,
/// 其中—_distanceCache[i][j]表示第i个资料点到第j个群聚对象中心点的距离;
Double2DVec _distanceCache;
void InitRandom();
static double getDistance(const DoubleVec& coord, const DoubleVec& center);
int NearestCluster(int ndx);
public:
KMeans(Double2DVec& data, int K);
void Start();
public:
~KMeans(void);
};
K-Means算法具体实现
#include "KMeans.h"
#include <time.h>
#include "Cluster.h"
#include "TermVector.h"
#include <limits>
KMeans::KMeans(Double2DVec &data, int K)
{
int i;
this->_coordinates.resize(data.size());
for (i=0;i<data.size();++i)
{
copy(data[i].begin(),data[i].end(),back_inserter(_coordinates[i]));
}
_coordCount = data.size();
_k = K;
_clusters.resize(K);
_clusterAssignments.resize(_coordCount);
_nearestCluster.resize(_coordCount);
_distanceCache.resize(_coordCount);
for (i=0;i<_coordCount;++i)
{
_distanceCache[i].resize(_coordCount);
}
InitRandom();
}
void KMeans::InitRandom()
{
srand(unsigned(time(NULL)));
for (int i = 0; i < _k; i++)
{
int temp = rand()%(_coordCount);//产生随机数
_clusterAssignments[temp] = i; //记录第temp个资料属于第i个聚类
_clusters[i] = new Cluster(temp,_coordinates[temp]);
}
}
void KMeans::Start()
{
int iter = 0,i,j;
while (true)
{
cout<<"Iteration "<<iter++<< " "<<endl;
"<<endl;
//1、重新计算每个聚类的均值
for (i = 0; i < _k; i++)
{
_clusters[i]->UpdateMean(_coordinates);
}
//2、计算每个数据和每个聚类中心的距离
for (i = 0; i < _coordCount; i++)
{
for (j = 0; j < _k; j++)
{
double dist = getDistance(_coordinates[i], _clusters[j]->Mean);
_distanceCache[i][j] = dist;
}
}
//3、计算每个数据离哪个聚类最近
for (i = 0; i < _coordCount; i++)
{
_nearestCluster[i] = this->NearestCluster(i);
}
//4、比较每个数据最近的聚类是否就是它所属的聚类
//如果全相等表示所有的点已经是最佳距离了,直接返回;
int k = 0;
for (i = 0; i < _coordCount; i++)
{
if (_nearestCluster[i] == _clusterAssignments[i])
k++;
}
if (k == _coordCount)
break;
//5、否则需要重新调整资料点和群聚类的关系,调整完毕后再重新开始循环;
//需要修改每个聚类的成员和表示某个数据属于哪个聚类的变量
for (j = 0; j < _k; j++)
{
_clusters[j]->CurrentMembership.clear();
}
for (i = 0; i < _coordCount; i++)
{
_clusters[_nearestCluster[i]]->CurrentMembership.push_back(i);
_clusterAssignments[i] = _nearestCluster[i];
}
}
}
double KMeans::getDistance(const DoubleVec& coord, const DoubleVec& center)
{
return 1- TermVector::ComputeCosineSimilarity(coord, center);
}
int KMeans::NearestCluster(int ndx)
{
int nearest = -1;
double min = numeric_limits<double>::max();
for (int c = 0; c < _k; c++)
{
double d = _distanceCache[ndx][c];
if (d < min)
{
min = d;
nearest = c;
}
}
return nearest;
}
KMeans::~KMeans(void)
{
vector<Cluster*>::iterator iter;
for (iter=this->_clusters.begin();iter!=_clusters.end();++iter)
{
delete (*iter);
}
_clusters.clear();
}
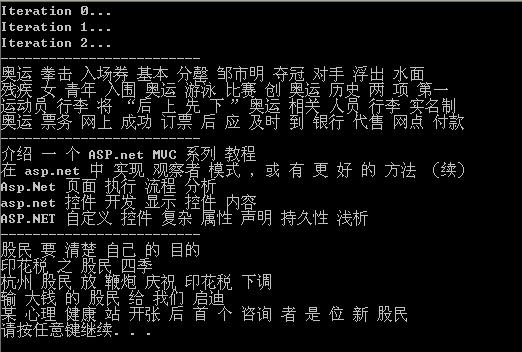
最后使用《蛙蛙推荐:蛙蛙教你文本聚类》这篇文章中的数据测试所得:
Reference
1, 蛙蛙推荐:蛙蛙教你文本聚类
2,Term frequency/Inverse document frequency implementation in C#
3, 维基百科tf–idf条目
4, K-Means算法java实现
附:
最后我想请教一个问题:蛙蛙池塘的代码中分词算法使用了一个正则表达式
Regex r=new Regex("([ ""t{}():;. "n])");
它产生的结果是将”asp.net”分成了两个单词”asp”和”net”,请问,为什么不直接将其看作是一个单词”asp.net”呢?




