Python基础-数据类型总结归纳.
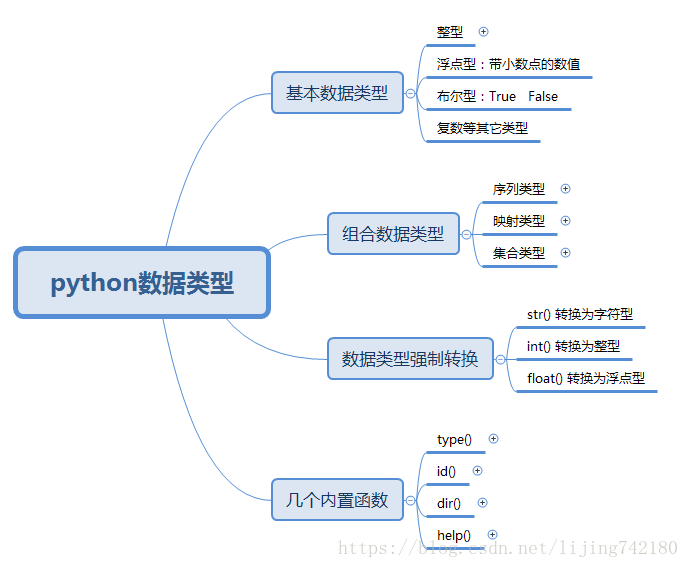
1.1、python3 数据类型:
| 类型 | 含义 | 示例 |
|---|---|---|
| int | 整型 | 1 |
| float | 浮点型 | 1.0 |
| bool | 布尔值 | True或False |
| complex | 复数 | a+bj |
| string | 字符串 | ‘abc123’ |
| list | 列表 | [a,b,c] |
| tuple | 元组 | (a,b,c) |
| set | 集合 | {a,b,c} |
| dictionary | 字典 | {a:b,c:d} |
1.2、备注说明
| 类型 | 说明 |
|---|---|
| complex | 复数的虚数部分不能省略 |
| string(字符串) | 字符串不能包括有 ‘\’ ,否则输出的不是原来的字符串 |
| list(列表)和tuple(元组) | list可以修改元素,tuple不能,但是tuple可以包括list等多种数据类型,占用资源多于list |
| set(集合) | 没有排列的顺序(没有索引,不能通过索引取值)及不会有重复的元素 |
| dictionary(字典) |
一个键对应多个值(值可以是列表、字典、集合等),一个值也可对应多个键。。但是不能有相同的键、列表作为值可以重复、字典和集合作为值不能重复。 |
- 不可变数据(3 个):Number(数字)、String(字符串)、Tuple(元组);
- 可变数据(3 个):List(列表)、Dictionary(字典)、Set(集合)。
- 可变数据类型:value值改变,id值不变;不可变数据类型:value值改变,id值也随之改变。(元组不可修改,所以元组是不可变类型)
变量以及类型
<1>变量的定义
在程序中,有时我们需要对2个数据进行求和,那么该怎样做呢?
大家类比一下现实生活中,比如去超市买东西,往往咱们需要一个菜篮子,用来进行存储物品,等到所有的物品都购买完成后,在收银台进行结账即可
如果在程序中,需要把2个数据,或者多个数据进行求和的话,那么就需要把这些数据先存储起来,然后把它们累加起来即可
在Python中,存储一个数据,需要一个叫做变量的东西,如下示例:
-
num1 = 100 #num1就是一个变量,就是一个模具
-
num2 = 87 #num2也是一个变量
-
result = num1 + num2 #把num1和num2这两个"模具"中的数据进行累加,然后放到 result变量中
- 说明:
- 所谓变量,可以理解为模具(内存空间),如果需要存储多个数据,最简单的方式是有多个变量,当然了也可以使用一个列表
- 程序就是用来处理数据的,而变量就是用来存储数据的
-
变量定义的规则:
- 变量名只能是 字母、数字或下划线的任意组合
- 变量名的第一个字符不能是数字
- 以下关键字不能声明为变量名
['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']
想一想:我们应该让变量占用多大的空间,保存什么样的数据?
|
类型
|
描述
|
例子
| 备注 |
|---|---|---|---|
|
str(字符型)
|
一个由字符组成的不可更改的有序串行。
|
'Wikipedia'
"Wikipedia"
"""Spanning
multiple
lines"""
|
在Python 3.x里,字符串由Unicode字符组成 |
|
bytes(字节)
|
一个由字节组成的不可更改的有序串行。
|
b'Some ASCII'
b"Some ASCII"
|
|
|
list(列表)
|
可以包含多种类型的可改变的有序串行
|
[4.0, 'string', True]
|
|
|
tuple(元组)
|
可以包含多种类型的不可改变的有序串行
|
(4.0, 'string', True)
|
|
|
set, frozenset(集合)
|
与数学中集合的概念类似。无序的、每个元素唯一。
|
{4.0, 'string', True}
frozenset([4.0, 'string', True])
|
|
|
dict(字典)
|
一个可改变的由键值对组成的无序串行。
|
{'key1': 1.0, 3: False}
|
|
|
int(整型)
|
精度不限的整数
|
42
|
|
|
float(浮点)
|
浮点数。精度与系统相关。
|
3.1415927
|
|
|
complex
|
复数
|
3+2.7j
|
|
|
bool(布尔)
|
逻辑值。只有两个值:真、假
|
True
False
|
条件语句
如果我们希望有效的响应用户的输入,代码就需要具有判断能力。能够让程序进行判断的结构成为条件,条件判断语句返回的是布尔值真或假,真就执行一条线路,假就执行另外一条线路
if 判断;
-
#!/usr/bin/env python
-
# -*- coding: encoding -*-
-
name = input('请输入用户名:')
-
if name == "Peter":
-
print( "超级管理员")
-
elif name == "eric":
-
print ("普通管理员")
-
elif name == "tony":
-
print ("业务主管")
-
else:
-
print ("普通用户")
While循环:
While循环,是一个循环加判断的组合,满足判断条件返回 真(True)开始循环代码块,不满足判断条件返回 假()不循环
格式:
While 条件:
代码块
注意:在While循环里如果不加终止循环的判断或者关键字,会一直循环(死循环)
如:
-
#!/usr/bin/env python
-
# -*- coding: utf-8 -*-
-
my_age = 28
-
count = 0
-
while count < 3:
-
user_input = int(input("input your guess num:"))
-
if user_input == my_age:
-
print("Congratulations, you got it !")
-
break
-
elif user_input < my_age:
-
print("Oops,think bigger!")
-
else:
-
print("think smaller!")
-
count += 1 #每次loop 计数器+1
-
else:
-
print("猜这么多次都不对,你个笨蛋.")
for循环:
主要用于循环一个字符串列表等
不需要判断,定义一个循环变量即可
格式:for (循环定义变量) in (被循环的变量) 循环完后自动退出整个循环
打印循环定义变量即可
关键字(continue) 跳出本次循环 继续下次环
关键字(break) 跳出整个循环 不在循环
如:for i in rang(0,10) #循环for i in range(1,10): #i=3
for j in range(1,i+1):
print('%s*%s=%s ' %(i,j,i*j),end='') #i=2 j=2
print()
2 是一个整数的例子。
长整数 不过是大一些的整数。
3.23和52.3E-4是浮点数的例子。E标记表示10的幂。在这里,52.3E-4表示52.3 * 10-4。
(-5+4j)和(2.3-4.6j)是复数的例子。
int(整型)
在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807
跟C语言不同,Python的长整数没有指定位宽,即:Python没有限制长整数数值的大小,但实际上由于机器内存有限,我们使用的长整数数值不可能无限大。
注意,自从Python2.2起,如果整数发生溢出,Python会自动将整数数据转换为长整数,所以如今在长整数数据后面不加字母L也不会导致严重后果了。
float(浮点型)
浮点数用来处理实数,即带有小数的数字。类似于C语言中的double类型,占8个字节(64位),其中52位表示底,11位表示指数,剩下的一位表示符号。
complex(复数)
复数由实数部分和虚数部分组成,一般形式为x+yj,其中的x是复数的实数部分,y是复数的虚数部分,这里的x和y都是实数。
布尔类型只有True和False两种值,但是布尔类型有以下几种运算:
与运算:只有两个布尔值都为 True 时,计算结果才为 True。
True and True # ==> True
True and False # ==> False
False and True # ==> False
False and False # ==> False
或运算:只要有一个布尔值为 True,计算结果就是 True。
True or True # ==> True
True or False # ==> True
False or True # ==> True
False or False # ==> False
非运算:把True变为False,或者把False变为True:
not True # ==> False
not False # ==> True
布尔运算在计算机中用来做条件判断,根据计算结果为True或者False,计算机可以自动执行不同的后续代码。
在Python中,布尔类型还可以与其他数据类型做 and、or和not运算,请看下面的代码:
a = True
print a and 'a=T' or 'a=F'
计算结果不是布尔类型,而是字符串 'a=T',这是为什么呢?
因为Python把0、空字符串''和None看成 False,其他数值和非空字符串都看成 True,所以:
True and 'a=T' 计算结果是 'a=T'
继续计算 'a=T' or 'a=F' 计算结果还是 'a=T'
要解释上述结果,又涉及到 and 和 or 运算的一条重要法则:短路计算。
1. 在计算 a and b 时,如果 a 是 False,则根据与运算法则,整个结果必定为 False,因此返回 a;如果 a 是 True,则整个计算结果必定取决与 b,因此返回 b。
2. 在计算 a or b 时,如果 a 是 True,则根据或运算法则,整个计算结果必定为 True,因此返回 a;如果 a 是 False,则整个计算结果必定取决于 b,因此返回 b。
所以Python解释器在做布尔运算时,只要能提前确定计算结果,它就不会往后算了,直接返回结果。
在python中声明一个字符串,通常有三种方法:在它的两边加上单引号、双引号或者三引号,(三引号可多行)如下:
name='hello'name1="hello bei jing "name2='''hello shanghai haha'''python中的字符串一旦声明,是不能进行更改的,如下:#字符串为不可变变量,即不能通过对某一位置重新赋值改变内容name='hello'name[0]='k'#通过下标来修改字符串的值,报错信息:TypeError: 'str' object does not support item assignment
|
1
2
3
4
|
name = "peter"print( "i am %s " % (name))print("i am{}“ .foemat(name))
输出: i am peter |
PS: 字符串是 %s;整数 %d;浮点数%f
优先掌握的字符串操作:
#1、按索引取值(正向取+反向取) :只能取
msg='hello world'
print(msg[4])#正向取值
print(msg[-1])#负向取值
#2、切片(顾头不顾尾,步长)
# msg='hello world' # 就是从一个大的字符串中切分出一个全新的子字符串
# print(msg[0:5])
# print(msg) # 没有改变原值,只是取值
# print(msg[0:5:1])
# print(msg[0:5])
# print(msg[0:5:2]) #hlo 步长的概念 0+2计算
#print(msg[5:0:-1])#从第5个开始向前取值,负步长的概念
#print(msg[-1::-1])
#print(msg[::-1])#从最后开始取到最前
#3、长度len:方法返回对象(字符、列表、元组等)长度或项目个数。
# msg='hello world'
# print(len(msg))
结果:11 包含空格
#4、成员运算in和not in:判断一个子字符串是否存在于一个大的字符串中
# print('alex' in 'alex is dsb')#返回true 可用于条件判断中 while
# print('dsb' in 'alex is dsb')#返回true
# print('sb' in 'alex is dsb')#返回true
# print('xxx' not in 'alex is dsb') # 推荐
# print(not 'xxx' in 'alex is dsb')
#5、移除空白strip:去掉字符串左右两边的字符strip,不管中间的,默认是去空白,括号内可使用* +/、-
# user=' peter 'username_db = "peter"
user_pwd_db = 123
Tag =True
while Tag:
user_name = input("请输入用户名:").strip("* +-\/_@#$%^&!~:?<>=|';")
user_pass = input("请输入密码:").strip("*\/ +-")
user_pass = int(user_pass)
if user_name ==username_db and user_pass == user_pwd_db:
print("用户名密码正确,登陆成功")
else:
print("登陆失败")
#6、切分split:针对按照某种分隔符组织的字符串,可以用split将其切分成列表,进而进行取值
# msg="root:123456:0:0::/root:/bin/bash"
# res=msg.split(':')
# print(res[1])
# cmd='dowload|a.txt|3333333'
# cmd_name,filename,filesize=cmd.split('|')
#7、循环
# msg='hello'
# for item in msg:
# print(item)
需要掌握的操作:
#1、strip,lstrip,rstrip
# print('*****egon*****'.lstrip('*'))#去除左边的
# print('*****egon*****'.rstrip('*'))#去除右边的
# print('*****egon*****'.strip('*'))#两边都去去除
#2、lower,upper:lower全部变成小写,upper全部变成大写
# msg='aABBBBb'
# res=msg.lower() # lower有返回值
# print(res)
# print(msg)
#3、startswith,endswith:startswth以什么开始,endswith以什么结束。返回True或者False。。可用于判断条件中。
# msg='alex is dsb'
# print(msg.startswith('alex'))
# print(msg.endswith('sb'))
# print(msg.endswith('b'))
#4、split,rsplit:
# print(msg.split('|',-1))#可以指定切分个数 从左往右切 -1表示切到底.
# print(msg.rsplit('|',1))#从右放左切 可以指定切的个数.
#5、join:以某种方式将列表拼接回字符串
# msg='get|a.txt|333331231'
# l=msg.split('|')
# print(l)
# src_msg='|'.join(l)
# print(src_msg)
#6、replace:替换字符串中字符,不是更改原值,有返回值。replace不能更换最后一个
# msg='alex say i have one tesla,alex is alex hahaha'
# print(msg.replace('alex','sb',1))# 1 表示改几个,几次 不写表示全改。
# print(msg)
#7、isdigit:判断字符串中包含的是否是存数字
age=input('请输入年龄: ').strip()
# if age.isdigit():
# age=int(age) #int('asfdsadfsd')
# if age > 30:
# print('too big')
# elif age < 30:
# print('too small')
# else:
# print('you got it')
# else:
# print('必须输入数字')
字符串需要了解的操作:
#1、find,rfind,index,rindex,coun
#2、center,ljust,rjust,zfill
#3、expandtabs
#4、captalize,swapcase,title
#5、is数字系列
#6、is其他
|
1
2
3
|
name_list = ['peter', 'seven', 'eric']或name_list = list(['peter', 'seven', 'eric']) |
基本操作:
x = 'hello world'
y = list(x)# 此处是小括号
print(type(y),y)
l1=list('hello') #list就相当于调用了一个for循环依次取出'hello'的值放入列表
# print(l1)
#优先掌握的操作:
#1、按索引存取值(正向存取+反向存取):即可存也可以取
l=['peter','lxx','yxx']
# print(l[0])
# l[0]='EGON'
# print(l)
# print(l[-1])
# print(l[3])
# l[0]='peter' # 只能根据已经存在的索引去改值
# l[3]='xxxxxxxx' #如果索引不存在直接报错
#2、切片(顾头不顾尾,步长)l=['egon','lxx','yxx',444,555,66666]
# print(l[0:5])
# print(l[0:5:2])
# print(l[::-1])
#3、长度
# l=['peter','lxx','yxx',444,555,66666,[1,2,3]]
# print(len(l))
#4、成员运算in和not in# l=['peter','lxx','yxx',444,555,66666,[1,2,3]]
# print('lxx' in l)
# print(444 in l)
#5、追加
l=['peter','lxx','yxx']
# l.append(44444)
# l.append(55555)
# print(l)
#6、删除
# l=['peter','lxx','yxx']
# 单纯的删除值:
# 方式1:
# del l[1] # 通用的
# print(l)
# 方式2:
# res=l.remove('lxx') # 指定要删除的值,返回是None.函数删除列表中第一个匹配项:
# print(l,res)
# 从列表中拿走一个值:pop函数默认删除列表中最后一个元素,pop函数是唯一可以既可以修改列表又能返回元素值除了(None)的列表方法。
# res=l.pop(-1) # 按照索引删除值(默认是从末尾删除),返回删除的那个值
# print(l,res)
#7、循环
# l=['peter','lxx','yxx']
# for item in l:
# print(item)
#8、往指定索引前插入值
# l=['peter','lxx','yxx']
# l.insert(0,11111)
# print(l)
# l.insert(2,2222222)
# print(l)
# 需要掌握的操作
#1、count函数统计元素个数:
l=['peter','peter','lxx','yxx',444,555,66666]
# print(l.count('peter'))
x=['4','2','1','7','1']
print x.count('1')
x=[[1,2],1,1,[2,1,[1,2]]]
print x.count([1,2])
运算结果:
========RESTART: C:/Users/Mr_Deng/Desktop/3.py========
2
1
>>>
#2、extend函数追加多个元素
x=[1,2,3,4]
print x
y=[5,6,7,8]
x.extend(y)
print x
运算结果:
========RESTART: C:/Users/Mr_peter/Desktop/3.py========
[1, 2, 3, 4]
[1, 2, 3, 4, 5, 6, 7, 8]
>>>
#3 index函数寻找列表第一个匹配元素的索引位置:
x=[1,2,3,4]
print x.index(4)
#not exist 6
print x.index(6)
运算结果:
========RESTART: C:/Users/Mr_peter/Desktop/3.py========
3
Traceback (most recent call last):
File "C:/Users/Mr_peter/Desktop/3.py", line 4, in <module>
print x.index(6)
ValueError: 6 is not in list
>>>
#4 reverse函数列表元素反向存放
x=[9,8,1,2,5,6]
print x
x.reverse()
print x
运算结果:
========RESTART: C:/Users/Mr_peter/Desktop/3.py========
[9, 8, 1, 2, 5, 6]
[6, 5, 2, 1, 8, 9]
>>>
#5 sort函数对列表元素排序:
x=[9,8,1,2,5,6]
print x
x.sort()
print x
运算结果:
========RESTART: C:/Users/Mr_peter/Desktop/3.py========
[9, 8, 1, 2, 5, 6]
[1, 2, 5, 6, 8, 9]
>>>
sort函数可以修改列表但是返回值却是空,意思是不能通过y=x.sort(x)的方式,将列表x排序后的结果赋值给y。若要实现这个功能,可以通过sorted函数来实现。
x=[9,8,1,2,5,6]
y=sorted(x)
print y
运算结果:
========RESTART: C:/Users/Mr_peter/Desktop/3.py========
[1, 2, 5, 6, 8, 9]
>>>
#6高级排序操作:
参数key作为排序依据
x=['kenan','xinyi','dadi','bob','as']
print x
x.sort(key=len)
print x
运算结果:
========RESTART: C:/Users/Mr_peter/Desktop/3.py========
['kenan', 'xinyi', 'dadi', 'bob', 'as']
['as', 'bob', 'dadi', 'kenan', 'xinyi']
>>>
参数reverse作为排序依据
x=['kenan','xinyi','dadi','bob','as']
print x
x.sort(reverse=True)
print x
运算结果:
========RESTART:C:/Users/Mr_peter/Desktop/3.py========
['kenan', 'xinyi', 'dadi', 'bob', 'as']
['xinyi', 'kenan', 'dadi', 'bob', 'as']
>>>
参数cmp作为比较的依据 (python3.x中已经取消)
x=['kenan','xinyi','dadi','bob','as','1']
print x
x.sort(cmp)
print x
运算结果:
========RESTART:C:/Users/Mr_peter/Desktop/3.py========
['kenan', 'xinyi', 'dadi', 'bob', 'as', '1']
['1', 'as', 'bob', 'dadi', 'kenan', 'xinyi']
>>>
|
1
2
3
|
ages = (11, 22, 33, 44, 55)或ages = tuple((11, 22, 33, 44, 55)) |
优先掌握的操作:
#1、按索引取值(正向取+反向取):只能取
t=('peter',123,['a','b'])
# print(id(t[0]))
# print(id(t[1]))
# print(id(t[2]))
#
# t[2][0]='A' #元组内列表数据可更改。
#2、切片(顾头不顾尾,步长)
# t=(1,2,3,4,5)
# print(t[0:3])#基本和列表差不多
# print(t)
#3、长度
len()
#4、成员运算in和not in
基本操作和列表差不多
#5、循环
# for item in ('a','b','c'):
# print(item)
#6:方法:
count:返回元素在元祖中出现的次数。
T = (123, 'Google', 'Runoob', 'Taobao', 123);print ("123 元素个数 : ", T.count(123))print ("Runoob 元素个数 : ", T.count('Runoob'))T.index(obj[,start=0[,end=len(T)]])- obj -- 指定检索的对象。
- start -- 可选参数,开始索引,默认为0。(可单独指定)
- end -- 可选参数,结束索引,默认为元祖的长度。(不能单独指定)
|
1
2
3
|
person = {"name": "mr.wu", 'age': 18}或person = dict({"name": "mr.wu", 'age': 18}) |
#优先掌握的操作:
#1、按key存取值:可存可取
# dic={'name':'peter'}
# print(dic['name'])
# dic['name']='peter'
# print(dic)
# dic['age']=18
# print(dic)
#2、长度len# dic={'name':'peter','age':18,'name':'Peter','name':'XXXX'}
# print(dic)
# print(len(dic))
#3、成员运算in和not in
# dic={'name':'peter','age':18,}
# print(18 in dic)
# print('age' in dic)
#4、删除
dic={'name':'peter','age':18,}
# 通用
# del dic['name']
# print(dic)
# del dic['xxx'] ##key不存在则报错
#5、键keys(),值values(),键值对items()
dic={'name':'peter','age':18,}
# print(dic.keys())
# l=[]
# for k in dic.keys():
# l.append(k)
# print(l)
# print(list(dic.keys()))
#6、循环
dic={'name':'peter','age':18,'sex':'male'}
# for k in dic.keys():
# print(k,dic[k])
# for k in dic:
# print(k,dic[k])
# for v in dic.values():
# print(v)
# for k,v in dic.items():
# print(k,v)
#7clear函数:清除字典中的所有项
# _*_ coding:utf-8 _*_ d={'one':1,'two':2,'three':3,'four':4} print d d.clear() print d 运算结果: =======RESTART: C:\Users\Mr_peter\Desktop\test.py======= {'four': 4, 'three': 3, 'two': 2, 'one': 1} {} >>>
#8copy函数:返回一个具有相同键值的新字典
# _*_ coding:utf-8 _*_ x={'one':1,'two':2,'three':3,'test':['a','b','c']} print u'初始X字典:' print x print u'X复制到Y:' y=x.copy() print u'Y字典:' print y y['three']=33 print u'修改Y中的值,观察输出:' print y print x print u'删除Y中的值,观察输出' y['test'].remove('c') print y print x 运算结果: =======RESTART: C:\Users\Mr_Peter\Desktop\test.py======= 初始X字典: {'test': ['a', 'b', 'c'], 'three': 3, 'two': 2, 'one': 1} X复制到Y: Y字典: {'test': ['a', 'b', 'c'], 'one': 1, 'three': 3, 'two': 2} 修改Y中的值,观察输出: {'test': ['a', 'b', 'c'], 'one': 1, 'three': 33, 'two': 2} {'test': ['a', 'b', 'c'], 'three': 3, 'two': 2, 'one': 1} 删除Y中的值,观察输出 {'test': ['a', 'b'], 'one': 1, 'three': 33, 'two': 2} {'test': ['a', 'b'], 'three': 3, 'two': 2, 'one': 1} >>>
d={'one':1,'two':2,'three':3}
print d print d.get('one')
print d.get('four')
运算结果: =======RESTART: C:\Users\Mr_Peter\Desktop\test.py======= {'three': 3, 'two': 2, 'one': 1} 1None
#11has_key函数:检查字典中是否含有给出的键
作用:去重,关系运算,
#定义集合:
集合:可以包含多个元素,用逗号分割,
集合的元素遵循三个原则:
1:每个元素必须是不可变类型(可hash,可作为字典的key)
2: 没有重复的元素
3:无序
注意集合的目的是将不同的值存放到一起,不同的集合间用来做关系运算,无需纠结于集合中单个值
#1 集合定义
s={1,3.1,'aa',(1,23),} # s=set({1,3.1,'aa',(1,23),}) s=set() 空集合
# print(s,type(s))
>>> s={2,3,4}
>>> type(s)
<type 'set'>
>>> s
set([2, 3, 4])
>>> s={1,2,3,2,2,1}#自动去重(集合中的元素不重复)
>>> s
set([1, 2, 3])
>>> s={1,2,3}#可以通过这样的形式生成一个非空集合
>>> s
set([1, 2, 3])
#2如何生成一个空集合呢?
>>> s={}#这样做生成的是空字典,并不是空集合
>>> s
{}
>>> type(s)
<type 'dict'>
可以这样生成空集合
>>> s=set([])#将空列表转化成空集合
>>> s
set([])
>>> s=set(())#也可以将空元组转化成空集合
>>> s
set([])
2》将列表或元组转换成集合
>>> l=range(10)
>>> l
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> s=set(l)#将列表转化成集合
>>> s
set([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> l
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> l[0]#列表有序,通过下标访问元素
0
>>> s[0]#集合无序,不支持下标访问
Traceback (most recent call last):
File "<pyshell#33>", line 1, in <module>
s[0]
TypeError: 'set' object does not support indexing
>>> t=(1,2,3,4,3,2)
>>> s=set(t)#将元组转换成集合(自动去重)
set([1, 2, 3, 4])
#3 set类型对象的内置方法
add()增加一个元素
In [41]: s1 = set(range(10))
In [42]: s1
Out[42]: {0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
In [43]: s1.add(10)
In [44]: s1
Out[44]: {0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
remove()删除一个元素
指定删除set对象中的一个元素,如果集合中没有这个元素,则返回一个错误。
In [47]: s1
Out[47]: {0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
In [48]: s1.remove(0)
In [49]: s1
Out[49]: {1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
pop()随机删除并返回一个元素
随机删除并返回一个集合中的元素,若集合为空,则返回一个错误。
In [65]: s2 = set(['j','m','i','l','k'])
In [66]: s2.pop()
Out[66]: 'i'
In [67]: s2.pop()
Out[67]: 'k'
discard()删除一个元素
指定删除集合中的一个元素,若没有这个元素,则do nothing。
In [90]: s1
Out[90]: {1, 2, 3, 4, 5, 6, 7, 8, 9}
In [91]: s1.discard(1)
In [92]: s1
Out[92]: {2, 3, 4, 5, 6, 7, 8, 9}
In [93]: s1.discard('abc')
In [94]: s1
Out[94]: {2, 3, 4, 5, 6, 7, 8, 9}
clear()清空一个集合中的所有元素
In [94]: s1
Out[94]: {2, 3, 4, 5, 6, 7, 8, 9}
In [95]: s1.clear()
In [96]: s1
Out[96]: set()
update()更新并集:update()方法没有返回值。
In [111]: s1.update(s2,s3)
In [112]: s1
Out[112]: {1, 2, 3, 4, 5, 8, 9, 10, 'a', 'b', 'c', 'd', 'de', 'f'}
# 4 常用操作+内置的方法
pythons={'李二丫','张金蛋','李银弹','赵铜蛋','张锡蛋','alex','oldboy'}
linuxs={'lxx','egon','张金蛋','张锡蛋','alex','陈独秀'}
# 取及报名python课程又报名linux课程的学员:交集
# print(pythons & linuxs)
# print(pythons.intersection(linuxs))
# 取所有报名老男孩课程的学员:并集
# print(pythons | linuxs)
# print(pythons.union(linuxs))
# 取只报名python课程的学员: 差集
# print(pythons - linuxs)
# print(pythons.difference(linuxs))
# 取只报名linux课程的学员: 差集
# print(linuxs - pythons)
# print(linuxs.difference(pythons))
# 取没有同时报名两门课程的学员:对称差集
# print(pythons ^ linuxs)
# print(pythons.symmetric_difference(linuxs))
# 是否相等
# s1={1,2,3}
# s2={3,1,2}
# print(s1 == s2)
# 父集:一个集合是包含另外一个集合
# s1={1,2,3}
# s2={1,2}
# print(s1 >= s2)
# print(s1.issuperset(s2))
# s1={1,2,3}
# s2={1,2,4}
# print(s1 >= s2)
# 子集
# s1={1,2,3}
# s2={1,2}
# print(s2 <= s1)
# print(s2.issubset(s1))

#返回true
# _*_ coding:utf-8 _*_ d={'one':1,'two':2,'three':3,'four':4} print d d.clear() print d 运算结果: =======RESTART: C:\Users\Mr_Deng\Desktop\test.py======= {'four': 4, 'three': 3, 'two': 2, 'one': 1} {} >>>
x=[9,8,1,2,5,6] print x x.sort() print x 运算结果: ========RESTART: C:/Users/Mr_Deng/Desktop/3.py======== [9, 8, 1, 2, 5, 6] [1, 2, 5, 6, 8, 9] >>>

