【算法】二叉查找树(BST)实现字典API
正文
参考资料
《算法(java)》 — — Robert Sedgewick, Kevin Wayne
《数据结构》 — — 严蔚敏
上一篇文章,我介绍了实现字典的两种方式,:有序数组和无序链表
这一篇文章介绍的是一种新的更加高效的实现字典的方式——二叉查找树。
【注意】 为了让代码尽可能简单, 我将字典的Key和Value的值也设置为int类型,而不是对象, 所以在下面代码中, 处理“操作失败”的情况的时候,是返回 -1 而不是返回 null 。 所以代码默认不能选择 -1作为 Key或者Value
(在实际场景中,我们会将int类型的Key替换为实现Compare接口的类的对象,同时将“失败”时的返回值从-1设为null,这时是没有这个问题的)
二叉查找树的定义
二叉查找树(BST)是一颗二叉树, 其中每个结点的键都大于其左子树中任意结点的键而小于其右子树中任意结点的键。
简单的理解, 就是二叉查找树在二叉树的基础上, 加上了一层结点大小关系的限制。
例如这是一颗二叉树, 其中的根结点10大于其左子树的所有结点的键(1,3,5,7),小于右子树中所有结点的键(12,14,15,16,18)

请注意一点, 这种大小关系并不是局限在“左儿子-父节点-右儿子”的范围里,而是“左子树-父节点-右子树”的范围中!
例如下图这并不是一颗二叉树,关键在于蓝色的66结点, 虽然它作为35-40-66这颗子树来看是一颗二叉查找树, 但从根结点看, 因为66>55, 这违背了二叉查找树的定义, 所以这不是一颗二叉树
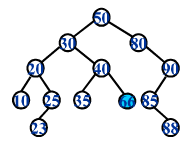
一颗二叉查找树对应一个有序序列
对二叉查找树进行中序遍历, 可以得到一个递增的有序序列。
通过将二叉查找树的所有键投影到一条直线上,我们就可以很直观地看出二叉查找树和有序序列的对应关系。
(下面的键值是字母A~Z, 大小关系是A最小,Z最大)
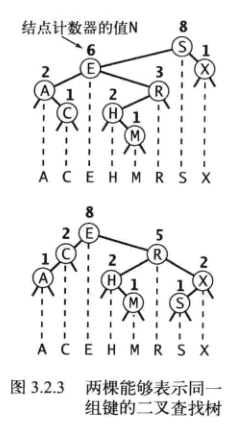
从上面的图示还可以得出的一点是:
1. 一个二叉查找树对应一个唯一的递增序列
2. 一个递增序列可以对应多个不同的二叉查树
二叉查找树实现字典API的所有思路, 都将围绕这种有序性展开。
本文的字典API
int size() 获取字典中键值对的总数量 void put(int key, int val) 将键值对存入字典中 int get(int key) 获取键key对应的值 void delete(int key) 从字典中删去对应键(以及对应的值) int min() 字典中最小的键 int max() 字典中最大的键 int rank(int key) key在键中的排名(小于key的键的数量) int select(int k) 获取排名为k的键
BST类的基本结构

public class BST { Node root; // 根结点 private class Node { // 匿名内部类Node int key; // 存储字典的键 int val; // 存储字典的值 Node left,right; // 分别表示左链接和右链接 int N; // 以该结点为根的子树中的结点总数 public Node (int key,int val,int N) { this.key = key; this.val = val; this.N = N; } } public int get (int key) { } public void put (int key,int val) { } // 其他方法 ... ... }
我们发现, 二叉查找树的类的基本结构和链表很相似。
因为基本单元是结点,所以创建一个匿名内部类(Node)以便初始化结点, 结点的成员变量key和val分别用来存储字典的键和值, 而因为每个结点有两条或以下的链接,所以用成员变量left和right表示。
在外部类BST中, 设置一个成员变量,所有的递归操作都从这个结点开始。
Node内部类中成员变量N的作用
但有一点令人奇怪的是:Node类里有个成员变量N,你可能能想到,这是为size方法(获取字典中键值对的总数量)准备的, 但不妨思考一下, 如果它仅仅为size方法而设置, 设置为外部类BST的成员变量不是就可以了吗, 为什么要为每个结点都设置一个N属性呢
Node类里的成员变量N除了为size方法服务外, 更多地是为rank方法和select方法服务的。
以rank方法为例( key在键中的排):
如果用有序数组实现字典,实现rank方法只要查找到给定的key,然后返回下标就可以了。
但对于二叉查找树而言,它没有“下标”的概念,所以如果它想要计算某个结点的排名(rank),只能根据该结点左儿子的N值去判断。
如下图中, A结点的排名(3)等于它的左儿子B的N值(3)

实际的rank方法编码当然不会像“rank(A)=B.N”这么简单, 但道理是类似的,可以通过递归的方式对一系列的N进行累加,从而得到目标key的排名。
综上所述
N到底设为Node类的成员变量还是BST类的成员变量取决于你的实际需求。
- 如果你不需要rank/select方法, 那么N完全可以设为BST的成员变量, 表示的是整棵树的结点总数, 维护N的代码编写很简单:在调用put方法时候使其加1, 在调用delete方法时使其减1。
- 如果你需要rank/select方法,则需对每个结点单独设N,代表的是该结点为根的子树中的结点总数,维护N的代码编写将会复杂很多,但这是必要的。(具体往下看)
因为文中代码包含rank/select方法,所以选择的当然是后者
方法设计的共同点
下面介绍的多数方法都是按下面这个“板式”,以get方法为例
// 针对某个结点设计的递归处理方法 private int get(Node x, int key) { // 递归调用get方法 } // 将root作为上面方法的参数,从根结点开始处理整颗二叉树 public int get(int key) { return get(root, key) }
基于函数重载的原理,编写两个同名函数, 一个向外部暴露(public), 一个隐藏在类里(private)
size方法
size方法
获取字典中键值对的总数量(结点总数量)
private int size (Node x) { if(x == null) return 0; return x.N; } public int size () { return size(root); }
对于private int size(Node x)
- 当结点存在的时候,返回结点所在子树的结点总数(包括自身)
- 当结点不存在的时候,即x为null时,返回0
结点不存在有两种可能的情况
1. 整棵树为空,即整棵树还没有任何结点,root = null
2. 树不为空,但在递归操作的过程中(例如put、delete),x下行至最下方的结点的左/右空链接
(一开始运行不了就多点几遍运行,或者拷贝到自己的IDE上跑。平台问题,不是我的锅哟。。。)
get方法
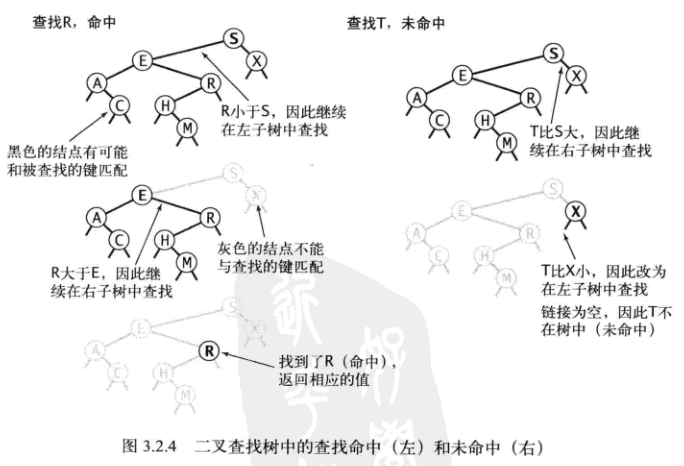
根据二叉树:每个结点的键都大于其左子树中任意结点的键而小于其右子树中任意结点的键,这一大小关系,我们可以很容易地写出get方法的代码。
从根结点root开始,比较给定key和当前结点的键大小关系
- key小于当前结点的键,说明key在左子树,向左儿子递归调用get
- key大于当前结点的键,说明key在右子树,向右儿子递归调用get
- key等于当前结点的键,查找成功并返回对应的值
最后结果有两种:
- 查找到给定的key,返回对应的值
- x迭代至最下方的结点也没有查找到key,因为x.left=x.right=null,在下一次调用get返回-1,结束递归
private int get (Node x,int key) { if(x == null) return -1; // 结点为空, 未查找到 if(key<x.key) { return get(x.left,key); // 键在左子树,向左子树查找 }else if(key>x.key) { return get(x.right, key); // 键在右子树,向右子树查找 }else{ return x.val; // 查找成功,返回值 } } public int get (int key) { return get(root,key); }
调用轨迹
put方法
put方法的实现思路和get方法相似
从根结点root开始,比较给定key和当前结点的键大小关系
- key小于当前结点的键,向左子树插入
- key大于当前结点的键,向右子树插入
- key等于当前结点的键,则将值替换为给定的val
如果到最后都没有查找到key,则创建新结点插入二叉树中
代码如下
private Node put (Node x, int key, int val) { if(x == null) return new Node(key,val,1); // 未查找到key,创建新结点,并插入树中 if(key<x.key){ x.left = put(x.left,key,val); // 向左子树插入 }else if(key>x.key){ x.right = put(x.right,key,val); // 向右子树插入 }else { x.val = val; // 查找到给定key, 更新对应val } x.N =size(x.left) + size(x.right) + 1; // 更新结点计数器 return x; // } public void put (int key,int val) { if(root == null) root = put(root,key,val); // 向空树中插入第一个结点 put(root,key,val); }
解释下put方法的代码中比较关键的几个点
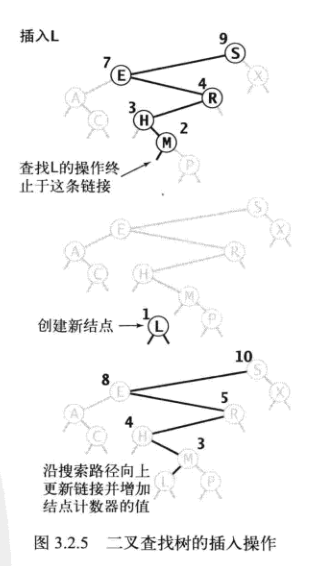
1.插入新结点的操作涉及两个递归层次
插入新结点的表达式要结合最后的两个递归层次进行分析
倒数第二次递归时的 x.left = put(x.left,key,val) 或x.right = put(x.right,key,val); 要和
倒数第一次递归时的 return new Node(key,val,1); 结合起来
即得到x.left = new Node(key,val,1) 或 x.right = new Node(key,val,1)
如下图所示

后一次递归创建的新结点将赋给前一次递归中结点的左链接(或右链接),从而插入二叉树中。
2. 更新结点计数器代码的实际调用顺序
另一个比较难理解的可能是这行代码:
x.N =size(x.left) + size(x.right) + 1; // 更新结点计数器
关于这点, 首先我们要分清两段不同的代码:
递归调用前代码和递归调用后代码
put的递归将一段代码分割成两部分: 递归调用前代码和递归调用后代码,如图所示
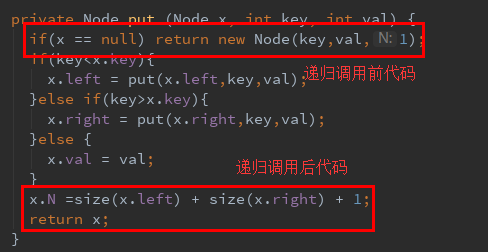
而递归调用前代码和递归调用后代码的执行顺序是不一样的。
- 递归调用前代码先执行, 而递归调用后代码后执行
- 递归调用前代码是一个“沿着树向下走”的过程,即递归层次是由浅到深, 而递归调用后代码是一个“沿着树向上爬”的过程, 即递归层次是由深到浅
如图
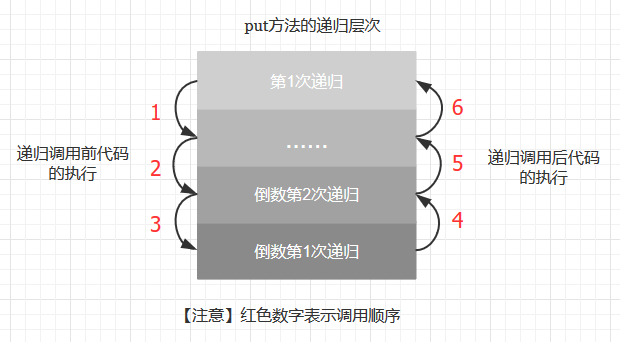
所以和我们的主观逻辑逻辑不同的是, x.N =size(x.left) + size(x.right) + 1;这段递归调用后代码是按递归层次由深到浅的顺序执行的,从而从新插入的结点开始,依次增加插入路径中每个结点上计数器N的值。 如图所示
整体过程
从图中可以看出, 整体的过程:
- 先“沿着树向下走”, 插入或更新结点
- 再“沿着树向上爬”, 更新结点计数器N
min,max方法
min方法
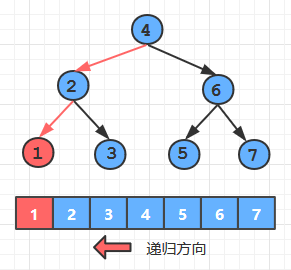
由结点键间的大小关系可知, 键值最小的结点也就是整棵树中位于最左端的结点。
所以我们的思路是: 从根结点开始, 不断向当前结点的左儿子递归,直到左儿子为空时,返回当前结点的键值, 此时的键值就是所有键值中的最小值
代码如下所示:
private Node min (Node x) { if(x.left == null) return x; // 如果左儿子为空,则当前结点键为最小值,返回 return min(x.left); // 如果左儿子不为空,则继续向左递归 } public int min () { if(root == null) return -1; return min(root).key; }
max方法实现的思路是相同的,这里就不多赘述了
delete方法是二叉查找树中最复杂的一个API,在讲解delete前,我们要先实现deleteMin方法,这是实现delete的基础
deleteMin方法
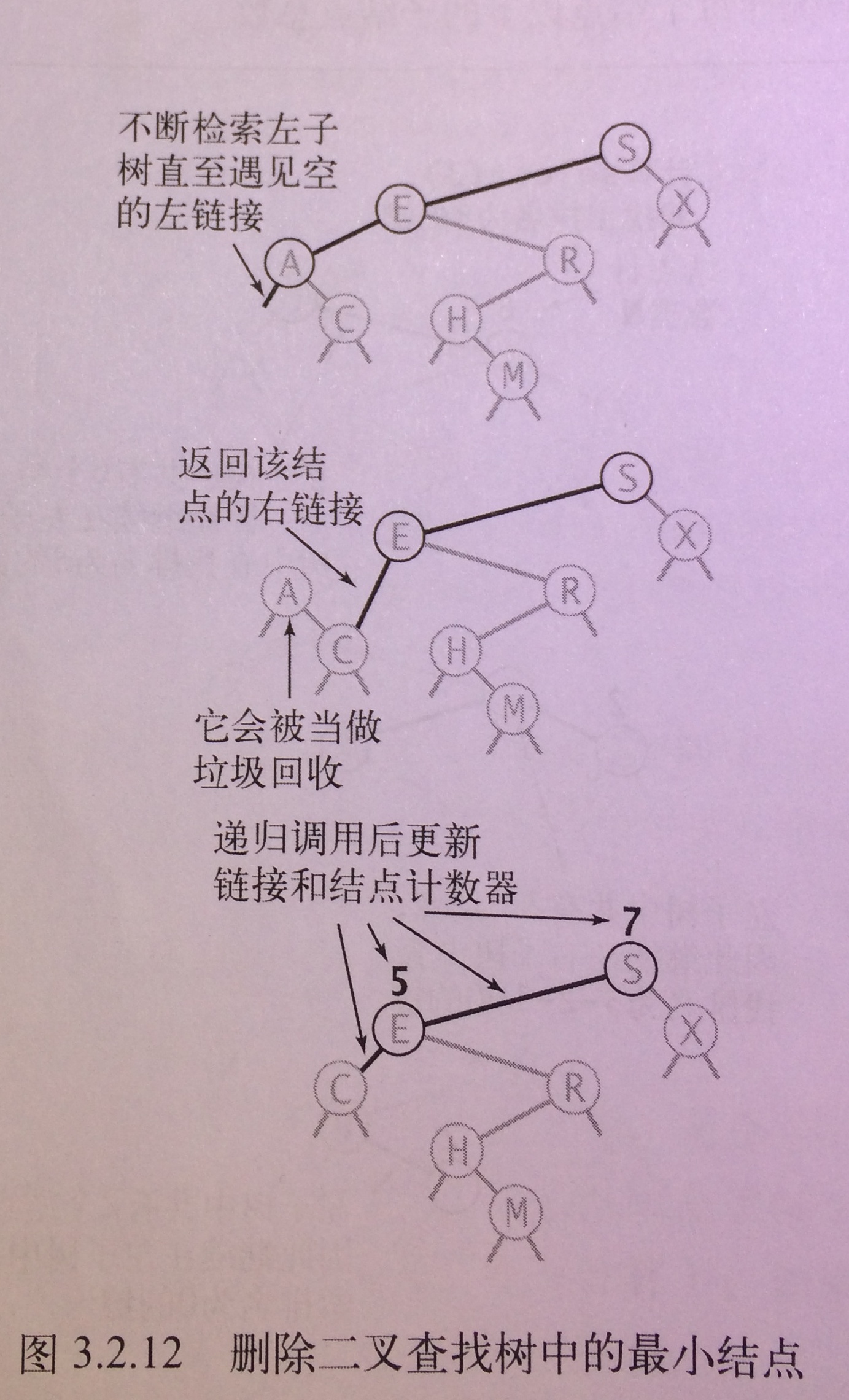
deleteMin的作用是:删除整颗树中键最小的那个结点。
deleteMin的实现思路就是在前面介绍的min方法的基础上再对查找到的结点进行删除。
假设查找到的键最小的结点为min结点, min结点的父节点为min.parent, min结点的右儿子为min.right, 那么:
删除min结点的方法就是将min.parent的左链接指向min.right, 这样min结点就被删除了。
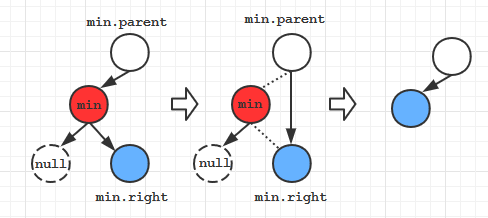
【注意】我们不能直接对min.parent的左链接赋null: min.parent.left = null, 因为min结点可能有右子树(如上图所示), 这样我们会把不该删除的min的右子树也一并删除了
代码如下:
public Node deleteMin (Node x) { if(x.left==null) return x.right; // 如果当前结点左儿子空,则将右儿子返回给上一层递归的x.left x.left = deleteMin(x.left);// 向左子树递归, 同时重置搜索路径上每个父结点指向左儿子的链接 x.N = size(x.left) + size(x.right) + 1; // 更新结点计数器N return x; // 当前结点不是min ### } public void deleteMin () { root = deleteMin(root); }
这段代码的作用有两方面:
- 沿搜索路径重置结点链接
- 更新路径上的结点计数器
沿搜索路径重置结点链接
如上文所说, 重置结点链接要结合上下两层递归来看
- 在递归到最后一个结点前, 下一层递归返回值是x(代码中###处), 这时,对上一层递归来说, x.left = deleteMin(x.left)等同于x.left = x.left
- 当递归到最后一个结点时,下一层递归中x = min, x.left==null判定为true, 返回x.right给上一层递归, 对上一层递归来说,x.left = deleteMin(x.left)等同于x.left = x.left.right;
请注意,上面表述中的上下两层递归里的x的含义是不同的
更新结点计数器N
同上文所述, x.N = size(x.left) + size(x.right) + 1是递归调用后代码, 执行顺序是从深的递归层次到 浅的递归层次执行, 调用“沿着树往上爬”, 从下往上更新路径上各结点的N值
调用轨迹
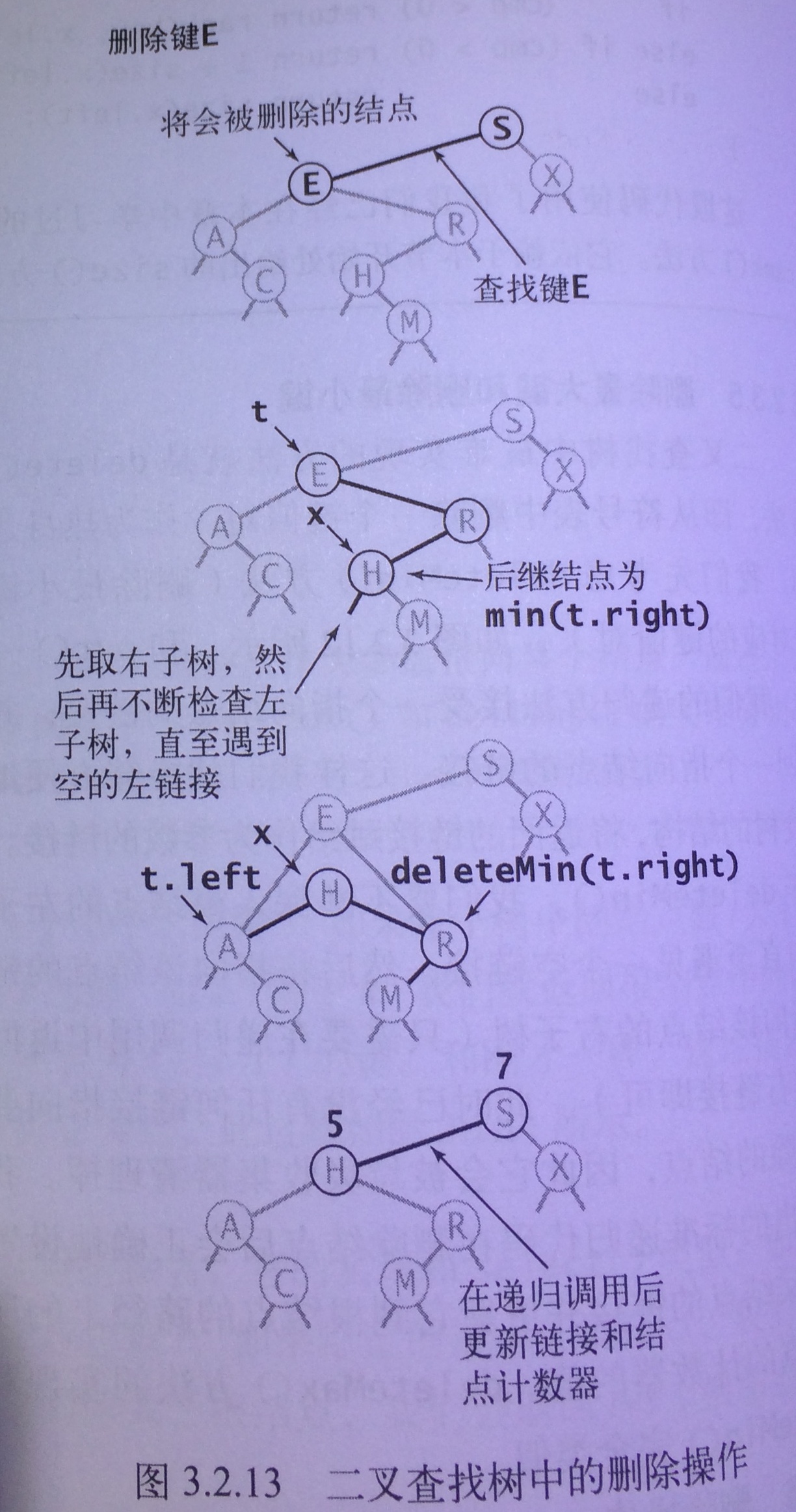
delete方法
delete方法: 根据给定键从字典中删除键值对
delete方法的实现还要依赖于BST中的一种特殊的结点——继承结点
继承结点
继承结点的定义如下:

例如, 下图中14的继承结点是15, 它是14的右子树中的最左结点,也即它是右子树中的最小键

为什么称15为14的继承结点呢? 因为用它去替换14后,将仍然能保持整颗二叉查找树的有序性
例如图,如果我们把15放到14的位置(相当于把14从原来位置删除,18和16相接)

此时, 放在新位置的15:
- 相对于父节点(A)而言是有序的。
- 相对于左子树(B)而言是有序的(15原本位于14右子树,所以大于14的左子树)
- 相对于右子树(C)而言是有序的(15是原来14右子树的最小键,移动后也小于C中其他结点)
所以故名思议, 继承结点就是某个结点被删除后,能够“继承”某个结点的结点
删除的实现思路
- 查找到相应的结点
- 将其删除
分析删除某个结点的三种情况
删除结点时, 按结点的位置,可以分三种情况分析:
第一种情况: 当被删除的结点没有子树时, 直接将它父节点指向它的链接置为null
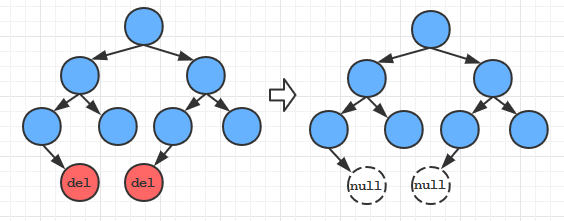
第二种情况: 当被删除的结点有且仅有一个子树时候,则将父节点指向该结点的链接, 改为指向该节点的子节点。

总结情况一和二, 如果我们把null结点也看作“结点”的话, 第一/二种情况的处理逻辑是一样的。
都是:在查找到待删除结点后,判断左子树或右子树是否为空, 若其中一个子树为空,则将该结点的父节点指向该节点的链接, 改为指向该节点的另一颗子树(左子树为null则指向右子树,右子树为null则指向右子树)。
比较复杂的是第三种情况
第三种情况: 当被删除的结点既有左子树又有右子树的时候
首先让我们思考一个问题: 在下面这种情况中,直接的“删除”是不可能做到的。
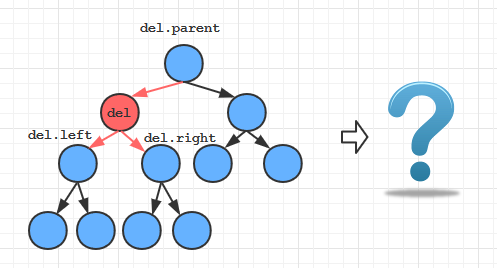
因为del结点被删除后,我们要同时处理两颗子树:del.left和del.right,有两条链接需要“重新接上”,但是del的父节点却只能提供一条链接, 这种不匹配使得“原地删除”变成了一件不可能做到的事情
所以我们的思路并不是使del结点“原地删除”,而是想办法寻找树中另一个结点去替代它,实现覆盖,而且希望在覆盖后仍能保持整颗树的有序性。
没错!轮到你出场了!—— 继承结点
如果我们先“删除”继承结点inherit,然后把inherit放在待删除结点del的位置上,去覆盖它,就可以啦。

由继承结点的性质可知覆盖后整颗树的有序性是仍能够得到保持的, 美滋滋~~
代码如下:
public Node delete (int key,Node x) { if(x == null) return null; if(key<x.key){ x.left = delete(key,x.left); // 向左子树查找键为key的结点 #1 }else if (key>x.key){ x.right = delete(key,x.right); // 向右子树查找键为key的结点 #2 }else{ // 在这个else里结点已经被找到,就是当前的x // 这里处理的是上述的 第一种情况和第二种情况:左子树为null或右子树为null(或都为null) if(x.left==null) return x.right; // 如果左子树为空,则将右子树赋给父节点的链接 #3 if(x.right==null) return x.left; // 如果右子树为空,则将左子树赋给父节点的链接 #4 // 这里处理的是上述的第三种情况 Node inherit = min(x.right); // 取得结点x的继承结点 inherit.right = deleteMin(x.right); // 将继承结点从原来位置删除,并重置继承结点右链接 inherit.left = x.left; // 重置继承结点左链接 x = inherit; // 将x替换为继承结点 } x.N = size(x.left)+ size(x.right) + 1; // 更新结点计数器 return x; // #5 } public void delete (int key) { root = delete(key, root); }
还是和之前一样, 按上下两个递归层次分析代码
在查找到和key值相等的结点后:
1.如果结点的位置是第一种情况:即被删除的结点没有子子树。对于下一层递归:在上面的#3处, if(x.left==null) 判定为true, 接着执行if语句里的return x.right, 等同于return null, 将值返回给上一层递归中的x.left = delete(key,x.left); 或x.right = delete(key,x.right); (#1和#2处)。等同于x.left = null或x.right =null。结点删除成功
2. 如果结点的位置是第二种情况:即当被删除的结点有且仅有一个子树。对于下一层递归: 如果左子树为null,则执行if(x.left==null) return x.right 返回非空的右子树,同理如果是右子树为null则返回非空的左子树。 上一层的递归通过x.left = delete(key,x.left);或x.right = delete(key,x.right); 接收到返回值,重置链接,结点删除成功
。
3. 如果结点的位置是第三种情况:当被删除的结点既有左子树又有右子树。那么先通过deleteMin删除该节点的继承结点inherit(右子树的最小结点)。然后,inherit有四个属性:key,value,left,right。保持inherit的key属性和value属性不变,而将left,right属性更改为和待删除结点相同。 这时就可以进行“覆盖”了, 通过x = inherit重置x结点, 并在下面的return x;(#5处)将继承结点覆盖后的x结点赋给上一层递归的x.left/right
运行轨迹
rank方法
rank方法:输入一个key,返回这个key在字典中的排名, 也就是key在查找二叉树对应的有序序列中的排名。
rank方法的思路:从根结点开始,如果给定的键和根结点的键相等, 则返回左子树中的结点总数t;如果给定的键小于根结点,则返回改键在左子树的排名(递归计算);如果给定的键大于根结点,则返回t+1(根结点)加上它在右子树中的排名。
具体解释如下:
在查找键的排名的时候,分三种情况:
1. 如果当前结点键小于key, 则说明key在左子树,向左子树递归。此时尚未确定key排名的下界,不需要增加Rank值。
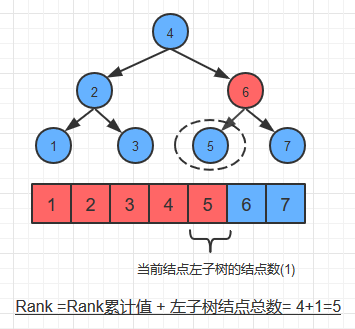
2. 如果当前结点键大于key,说明key在右子树, 向右子树递归。此时能够对key排名的下界进行进一步的计算。 计算方法:Rank = Rank的累计值 + 左子树结点总数+ 1, 如下图所示:
(假设图中查找的key为6)

3. 如果当前结点键刚好等于key, 排名的递归计算结束,此时只要再加上左子树的结点总数就可以了。计算方法:Rank = Rank累计值 + 左子树结点总数
(假设图中查找的key为6,接上图)
代码如下:
public int rank (Node x,int key) { if(x == null) return 0; if(key<x.key) { return rank(x.left,key); }else if(key>x.key) { return size(x.left) + 1 + rank(x.right, key); }else { return size(x.left); } } public int rank (int key) { return rank(root,key); }
select方法
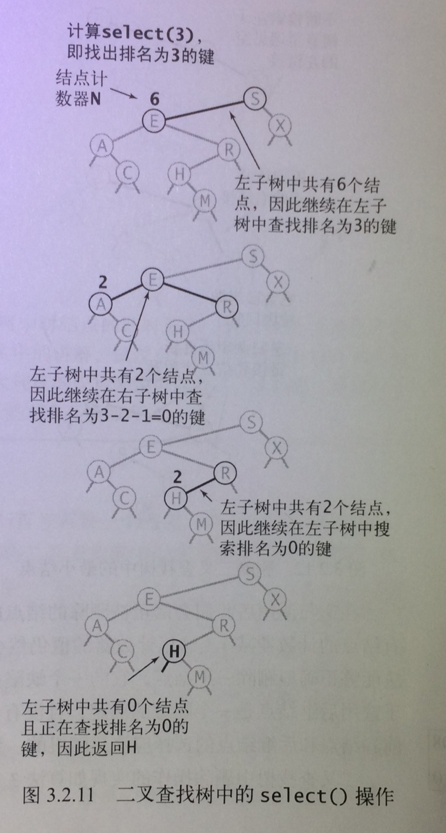
select方法是rank的逆方法: 找到给定排名的键
实现思路: 查找排名为k的键,如果左子树中的结点数大于k, 那么我们就继续(递归地)在左子树中查找排名为k的键; 如果t等于k,我们就返回根结点中的键,如果t小于k,我们就(递归地)在右子树中查找排名为k-t-1的键。
代码如下:
private Node select (Node x,int k) { if(x==null) return null; int t = size(x.left); if(t>k){ return select(x.left,k); }else if(t<k) { return select(x.right,k-t-1); }else { return x; } } public int select (int k) { return select(root,k).key; }
运行轨迹
floor、ceiling方法
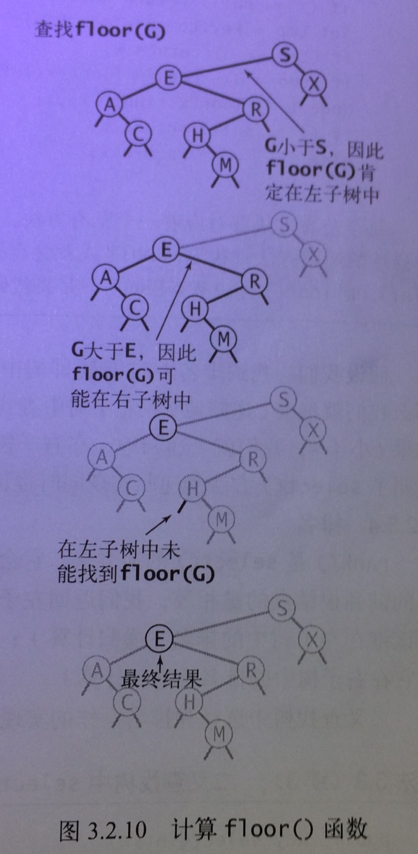
floor: 向下取整,取得小于或等于给定key的最大键
在查找过程中,分3种情况:
1. key小于当前结点的键,所以对key向下取整的结果肯定会在左子树, 所以向左儿子递归处理
2. key等于当前结点的键, 也符合floor的定义, 所以直接返回该键
3. key大于当前结点的键,这种情况只能先排除左子树,在此基础上有两种可能:floor值就是当前结点的键,或者floor在当前结点的右子树中, 但由于条件不足无法立即给出判断,所以只能继续向右子树递归floor方法,并取得递归的返回值,判断递归返回的结果是否为null
- 如果递归返回null,说明右子树没有floor值,所以floor值就是当前结点的键,
- 如果递归不为null,说明右子树还有比当前结点键更大的floor值,所以返回递归后的非null的floor值
代码如下:
private Node floor (Node x,int key) { if(x==null) return null; if(key<x.key){ // key小于当前结点的键 return floor(x.left,key); // key的floor值在左子树,向左递归 }else if(key==x.key) { return x; // 和key相等,也是floor值,返回 }else { // 这里排除floor值在左子树,剩下两种可能:floor值是当前结点或在右子树 Node n = floor(x.right, key); if(n==null) return x; // 右子树没有找到floor值,所以当前结点键就是floor else return n; // 右子树找到floor值,返回找到的floor值 } } public int floor (int key) { if(root==null) return -1; //树为空, 没有floor值 return floor(root, key).key; }
轨迹图示
ceiling方法实现同理,这里就不写代码了
【完】

我叫彭湖湾,请叫我胖湾
标签:
算法


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)