福大软工1816 · 第五次作业 - 结对项目2
博客链接
刘浩:https://www.cnblogs.com/peacepeacepeace/p/9748998.html
后敬甲:https://www.cnblogs.com/hjjLcherry/p/9762622.html
具体分工
后敬甲负责.txt文件处理中的总行数统计和总字符串的统计,博客一部分撰写
Github项目地址
https://github.com/TragedyN/pair-project
PSP表格

解题思路描述与设计实现说明
爬虫使用
使用python语言实现,其中使用到了requests库和beautifulsoup库,主要使用bs的.select函数选择html中所需要的标签的id,class属性,以找到并获取对应的信息
代码组织与内部实现设计(类图)
主要流程图如下
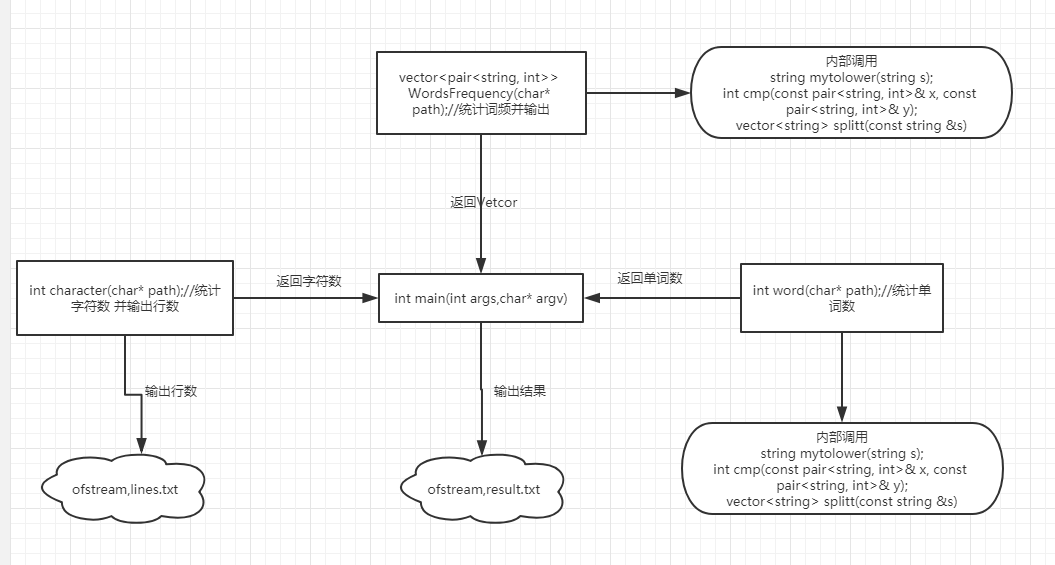
说明算法的关键与关键实现部分流程图
处理自定义输入
简单使用条件语句逐个判断输入的参数,分析其对应的功能,并给出可能发生的错误分析
while (argv[p] != NULL) {
if (argv[p][0]!= '-') {
printf("错误输入格式\n");
return -1;
}
else if(argv[p][1]=='i'){
if (argv[p + 1] == NULL) {
printf("缺少输入路径\n");
return -1;
}
ipath = argv[p + 1];//输入.txt文件的路径
p=p+2;
continue;
}
else if (argv[p][1] == 'o') {
if (argv[p + 1] == NULL) {
printf("缺少输出路径\n");
return -1;
}
opath = argv[p + 1];//输出.txt文件的路径
p = p + 2;
continue;
}
else if (argv[p][1] == 'n') {
if (argv[p + 1] == NULL) {
break;
}
if (isdigit(argv[p + 1][0]) == NULL) {
p++;
}
else {
diy = atoi(argv[p + 1]);//词频输出个数
p = p + 2;
}
continue;
}
else if (argv[p][1] == 'm') {
if (argv[p + 1]== NULL) {
break;
}
if (isdigit(argv[p + 1][0]) == NULL) {
p++;
}
else {
if (atoi(argv[p + 1]) < 2 || atoi(argv[p + 1]) > 10){
printf("错误词组长度");
return -1;
}
cizulen = atoi(argv[p + 1]);//词组长度
p = p + 2;
}
continue;
}
else if (argv[p][1] == 'w') {
if (argv[p + 1] == NULL || (atoi(argv[p + 1])!=1 && atoi(argv[p + 1])!=0)) {
printf("错误权重\n");
return -1;
}
weight = atoi(argv[p + 1]);//词频权重
p = p + 2;
continue;
}
else {
printf("错误参数\n");
return -1;
}
}
统计字符数
int character(char* path) {
/*
ifstream 读取文件路径
逐个读取字符数,统计读入的所有字符
将所有字符连接后按分割符进行分割,将一个个子字符串放入vector中
/*
for (vector<string>::size_type i = 0; i != split.size(); ++i) {
//逐个读入子字符串,计算子字符串为“Title“的次数,
string key = split[i];
if (i+2<=split.size()&&split[i + 1] == "Title"&&key.size() <= 3) {
//字符数还要减去Title前的文章编号
count = count - key.size()-1;
//cout << count << endl;
}
if (m1.count(key) == 0)
{
m1.insert(pair <string, int>(key, 1));
}
else
{
m1[key]++;
}
}
/*
因为Title不会在正文(需要统计的范围)中出现,
而每一个Title对应着一个同样不需要统计的Abstract,按照题意每一篇文章要减去17个字符
*/
count = count - m1["title"] * 17;
return count;
}
统计单词数
与统计字符数原理相似,也是算出总的单词数然后再减去出现的Title和Abstract的次数,还有两论文之间的换行
统计词频输出
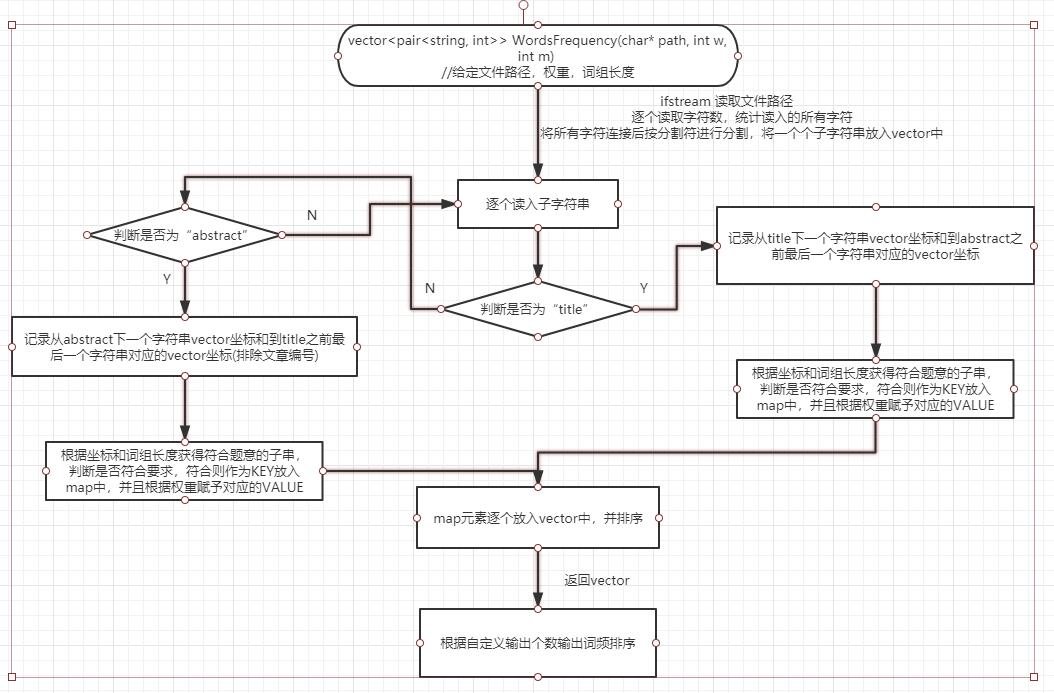
附加题设计与展示
- 设计的创意独到之处
- 分析论文列表中各位作者之间的关系,论文A的第一作者可能同时是论文B的第二作者,不同论文多位作者之间可能存在着联系
- 对数据的图形可视化做出一些努力,比如对上一条功能可以形成关系图谱
- 实现思路-
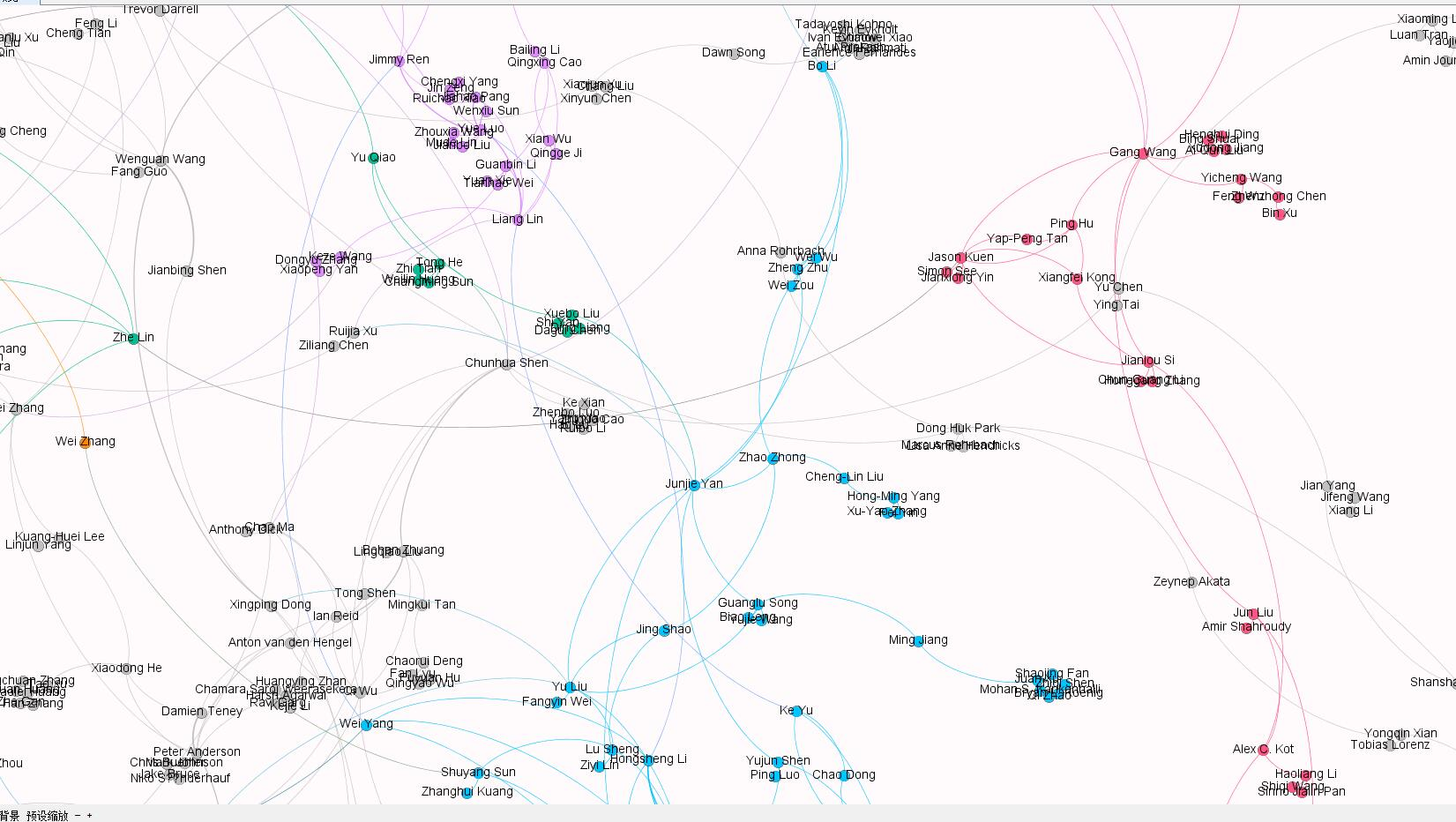
利用爬虫获取每篇文章的作者信息,存入.txt文件中,再利用excel读取.txt信息,按照文章次序和第一作者,第二作者这样的排序来整理,之后再利用gephi工具读取要处理的excel文件,利用该工具自带的功能实现作者之间的关系网络力向图 - 实现成果展示
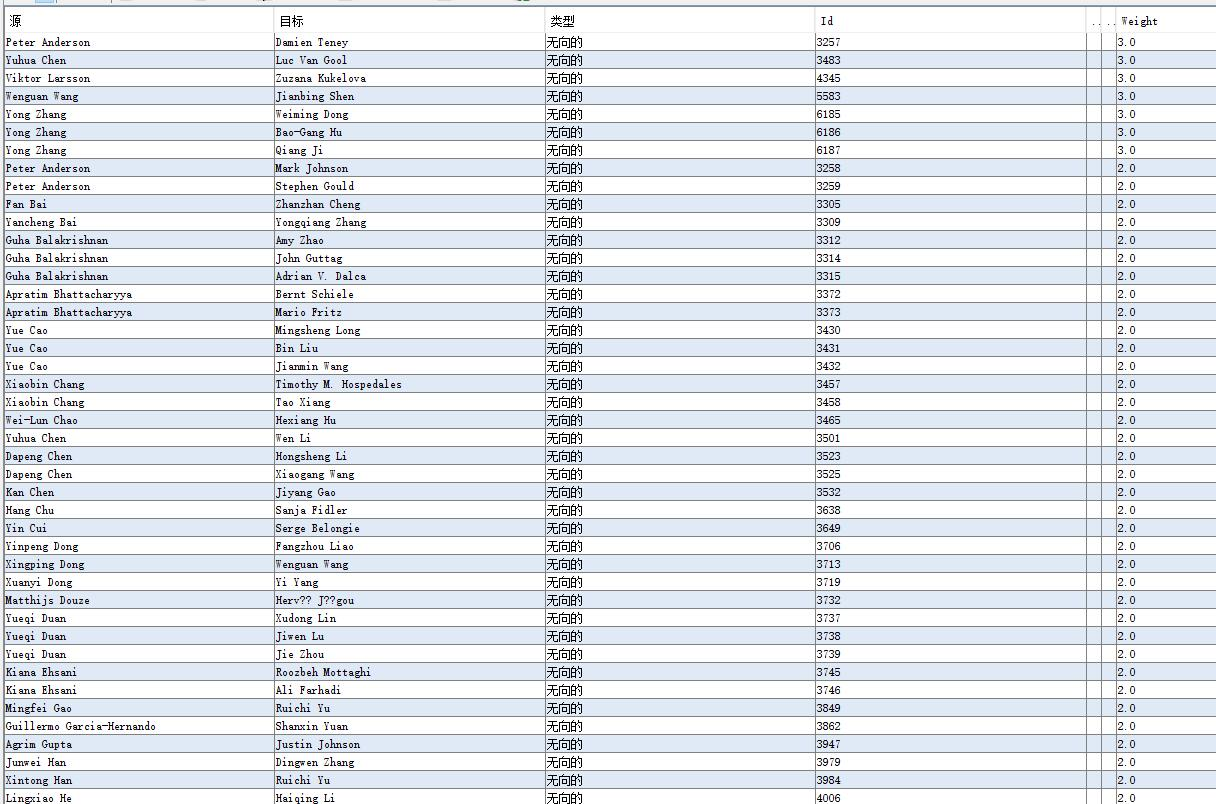
作者权重
效果局部图
关键代码解释
int character(char* path) {
/*
ifstream 读取文件路径
逐个读取字符数,统计读入的所有字符
将所有字符连接后按分割符进行分割,将一个个子字符串放入vector中
/*
for (vector<string>::size_type i = 0; i != split.size(); ++i) {
//逐个读入子字符串,计算子字符串为“Title“的次数,
string key = split[i];
if (i+2<=split.size()&&split[i + 1] == "Title"&&key.size() <= 3) {
//字符数还要减去Title前的文章编号
count = count - key.size()-1;
//cout << count << endl;
}
if (m1.count(key) == 0)
{
m1.insert(pair <string, int>(key, 1));
}
else
{
m1[key]++;
}
}
/*
因为Title不会在正文(需要统计的范围)中出现,
而每一个Title对应着一个同样不需要统计的Abstract,按照题意每一篇文章要减去17个字符
*/
count = count - m1["title"] * 17;
return count;
}
性能分析与改进
减少不同功能对读入字符后的操作,如只记录字符数的话就不需要将字符串统一转小写,若只记录单词数的话就不需要放入map中等等
* 性能分析图
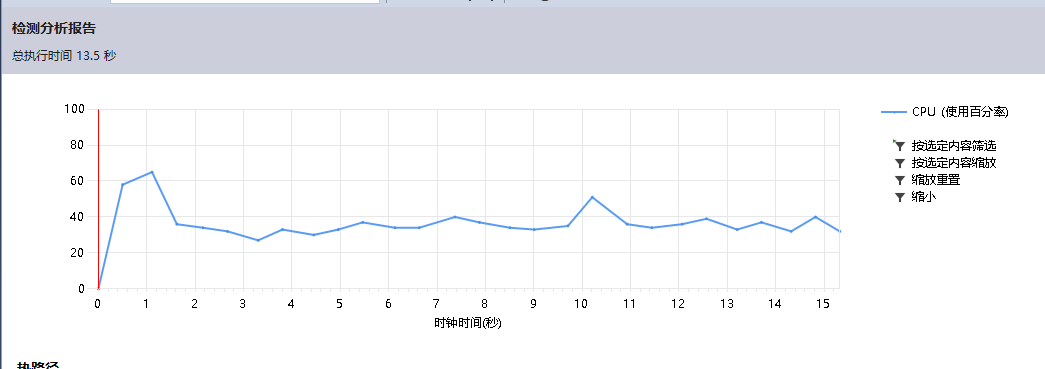
* 调用最大资源的函数

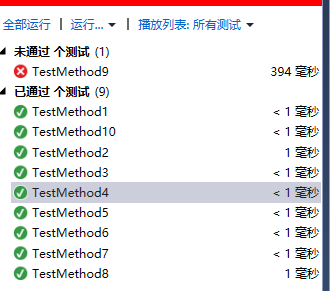
单元测试
* TestMethod1:空文本
* TestMethod2:单字符文本
* TestMethod3:全空格文本
* TestMethod4:非字母与数字文本
* TestMethod5:单词全部大写文本
* TestMethod6:单词数字开头文本
* TestMethod7:最后一行有换行
* TestMethod8:单词长度小于4
* TestMethod9:汉字文本名
* TestMethod10:无输入
贴出Github的代码签入记录
遇到的代码模块异常或结对困难及解决方法
- 困难:
处理输入文档时因为要按照题目要求不能算上每篇文章的title和abstract还有编号的部分,所以和上一回的个人项目还是有挺多的区别,需要改写各种统计功能 - 解决方案:
通过分析爬虫下来的结果,得到了需要统计的部分中不会出现“title”这个信息,利用这个信息可以快速找出有多少篇论文,然后再根据题意减去对应的字符总数和单词数 - 有何收获
学习到了分析需求,和利用现有条件,更加简便和快速的完成需求
评价你的队友
认真负责,积极跟进作业,虽然现在专业知识还略有不足,但是也有很大进步的空间
学习进度条
| 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 4 | 240 | 686 | 10 | 60 | LeetCode代码练习,爬虫学习,学习小程序开发文档 |
| 5 | 320 | 1006 | 40 | 100 | 学习小程序开发文档,LeetCode代码练习 |
参考
[关系图谱] 一.Gephi通过共线矩阵构建知网作者关系图谱
https://blog.csdn.net/eastmount/article/details/81746650
