
机器学习工程师 - Udacity 项目:实现一个狗品种识别算法App
步骤 0: 导入数据集
导入狗数据集
在下方的代码单元(cell)中,我们导入了一个狗图像的数据集。我们使用 scikit-learn 库中的 load_files 函数来获取一些变量:
train_files,valid_files,test_files- 包含图像的文件路径的numpy数组train_targets,valid_targets,test_targets- 包含独热编码分类标签的numpy数组dog_names- 由字符串构成的与标签相对应的狗的种类
from sklearn.datasets import load_files
from keras.utils import np_utils
import numpy as np
from glob import glob
# define function to load train, test, and validation datasets
def load_dataset(path):
data = load_files(path)
dog_files = np.array(data['filenames'])
dog_targets = np_utils.to_categorical(np.array(data['target']), 133)
return dog_files, dog_targets
# load train, test, and validation datasets
train_files, train_targets = load_dataset('/data/dog_images/train')
valid_files, valid_targets = load_dataset('/data/dog_images/valid')
test_files, test_targets = load_dataset('/data/dog_images/test')
# load list of dog names
dog_names = [item[20:-1] for item in sorted(glob("/data/dog_images/train/*/"))]
# print statistics about the dataset
print('There are %d total dog categories.' % len(dog_names))
print('There are %s total dog images.\n' % len(np.hstack([train_files, valid_files, test_files])))
print('There are %d training dog images.' % len(train_files))
print('There are %d validation dog images.' % len(valid_files))
print('There are %d test dog images.'% len(test_files))
导入人脸数据集
在下方的代码单元中,我们导入人脸图像数据集,文件所在路径存储在名为 human_files 的 numpy 数组。
import random
random.seed(8675309)
# 加载打乱后的人脸数据集的文件名
human_files = np.array(glob("/data/lfw/*/*"))
random.shuffle(human_files)
# 打印数据集的数据量
print('There are %d total human images.' % len(human_files))
步骤1:检测人脸
我们将使用 OpenCV 中的 Haar feature-based cascade classifiers 来检测图像中的人脸。OpenCV 提供了很多预训练的人脸检测模型,它们以XML文件保存在 github。我们已经下载了其中一个检测模型,并且把它存储在 haarcascades 的目录中。
在如下代码单元中,我们将演示如何使用这个检测模型在样本图像中找到人脸。
import cv2
import matplotlib.pyplot as plt
%matplotlib inline
# 提取预训练的人脸检测模型
face_cascade = cv2.CascadeClassifier('haarcascades/haarcascade_frontalface_alt.xml')
# 加载彩色(通道顺序为BGR)图像
img = cv2.imread(human_files[3])
# 将BGR图像进行灰度处理
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 在图像中找出脸
faces = face_cascade.detectMultiScale(gray)
# 打印图像中检测到的脸的个数
print('Number of faces detected:', len(faces))
# 获取每一个所检测到的脸的识别框
for (x,y,w,h) in faces:
# 在人脸图像中绘制出识别框
cv2.rectangle(img,(x,y),(x+w,y+h),(255,0,0),2)
# 将BGR图像转变为RGB图像以打印
cv_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 展示含有识别框的图像
plt.imshow(cv_rgb)
plt.show()

在使用任何一个检测模型之前,将图像转换为灰度图是常用过程。detectMultiScale 函数使用储存在 face_cascade 中的数据,对输入的灰度图像进行分类。
在上方的代码中,faces 以 numpy 数组的形式,保存了识别到的面部信息。它其中每一行表示一个被检测到的脸,该数据包括如下四个信息:前两个元素 x、y 代表识别框左上角的 x 和 y 坐标(参照上图,注意 y 坐标的方向和我们默认的方向不同);后两个元素代表识别框在 x 和 y 轴两个方向延伸的长度 w 和 d。
写一个人脸识别器
我们可以将这个程序封装为一个函数。该函数的输入为人脸图像的路径,当图像中包含人脸时,该函数返回 True,反之返回 False。该函数定义如下所示。
# 如果img_path路径表示的图像检测到了脸,返回"True"
def face_detector(img_path):
img = cv2.imread(img_path)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray)
return len(faces) > 0
【练习】 评估人脸检测模型
问题 1:
在下方的代码块中,使用 face_detector 函数,计算:
human_files的前100张图像中,能够检测到人脸的图像占比多少?dog_files的前100张图像中,能够检测到人脸的图像占比多少?
理想情况下,人图像中检测到人脸的概率应当为100%,而狗图像中检测到人脸的概率应该为0%。你会发现我们的算法并非完美,但结果仍然是可以接受的。我们从每个数据集中提取前100个图像的文件路径,并将它们存储在human_files_short和dog_files_short中。
human_files_short = human_files[:100]
dog_files_short = train_files[:100]
## 请不要修改上方代码
## TODO: 基于human_files_short和dog_files_short
## 中的图像测试face_detector的表现
print(np.mean([face_detector(human) for human in human_files_short]))
print(np.mean([face_detector(dog) for dog in dog_files_short]))
问题 2:
就算法而言,该算法成功与否的关键在于,用户能否提供含有清晰面部特征的人脸图像。 那么你认为,这样的要求在实际使用中对用户合理吗?如果你觉得不合理,你能否想到一个方法,即使图像中并没有清晰的面部特征,也能够检测到人脸?
回答: 不合理;使用CNN;
Tips:
进一步提升人脸识别的准确度,可以尝试HOG(Histograms of Oriented Gradients)或一些基于深度学习的算法,如YOLO(Real-Time Object Detection algorithm)、FaceNet、MTCNN等。此外,你可以使用[imgaug]来对训练集进行增强、扩充,以增加训练集中的多样性。
补充阅读材料:
- Tutorial - Face Detection using Haar Cascades
- Face Detection using OpenCV
- YouTube video - Haar Cascade Object Detection Face & Eye
- Haar caascade classifiers
- YouTube video - VIOLA JONES FACE DETECTION EXPLAINED
- How can I understand Haar-like feature for face detection?
- A simple facial recognition api for Python and the command line
- 这个知乎专栏介绍了目前主流的基于深度学习的人脸识别算法。
选做:
我们建议在你的算法中使用opencv的人脸检测模型去检测人类图像,不过你可以自由地探索其他的方法,尤其是尝试使用深度学习来解决它:)。请用下方的代码单元来设计和测试你的面部监测算法。如果你决定完成这个选做任务,你需要报告算法在每一个数据集上的表现。
## (选做) TODO: 报告另一个面部检测算法在LFW数据集上的表现
### 你可以随意使用所需的代码单元数
步骤 2: 检测狗狗
在这个部分中,我们使用预训练的 ResNet-50 模型去检测图像中的狗。下方的第一行代码就是下载了 ResNet-50 模型的网络结构参数,以及基于 ImageNet 数据集的预训练权重。
ImageNet 这目前一个非常流行的数据集,常被用来测试图像分类等计算机视觉任务相关的算法。它包含超过一千万个 URL,每一个都链接到 1000 categories 中所对应的一个物体的图像。任给输入一个图像,该 ResNet-50 模型会返回一个对图像中物体的预测结果。
from keras.applications.resnet50 import ResNet50
# 定义ResNet50模型
ResNet50_model = ResNet50(weights='imagenet')
数据预处理
- 在使用 TensorFlow 作为后端的时候,在 Keras 中,CNN 的输入是一个4维数组(也被称作4维张量),它的各维度尺寸为
(nb_samples, rows, columns, channels)。其中nb_samples表示图像(或者样本)的总数,rows,columns, 和channels分别表示图像的行数、列数和通道数。
- 下方的
path_to_tensor函数实现如下将彩色图像的字符串型的文件路径作为输入,返回一个4维张量,作为 Keras CNN 输入。因为我们的输入图像是彩色图像,因此它们具有三个通道(channels为3)。- 该函数首先读取一张图像,然后将其缩放为 224×224 的图像。
- 随后,该图像被调整为具有4个维度的张量。
- 对于任一输入图像,最后返回的张量的维度是:
(1, 224, 224, 3)。
paths_to_tensor函数将图像路径的字符串组成的 numpy 数组作为输入,并返回一个4维张量,各维度尺寸为(nb_samples, 224, 224, 3)。 在这里,nb_samples是提供的图像路径的数据中的样本数量或图像数量。你也可以将nb_samples理解为数据集中3维张量的个数(每个3维张量表示一个不同的图像。
from keras.preprocessing import image
from tqdm import tqdm
def path_to_tensor(img_path):
# 用PIL加载RGB图像为PIL.Image.Image类型
img = image.load_img(img_path, target_size=(224, 224))
# 将PIL.Image.Image类型转化为格式为(224, 224, 3)的3维张量
x = image.img_to_array(img)
# 将3维张量转化为格式为(1, 224, 224, 3)的4维张量并返回
return np.expand_dims(x, axis=0)
def paths_to_tensor(img_paths):
list_of_tensors = [path_to_tensor(img_path) for img_path in tqdm(img_paths)]
return np.vstack(list_of_tensors)
基于 ResNet-50 架构进行预测
对于通过上述步骤得到的四维张量,在把它们输入到 ResNet-50 网络、或 Keras 中其他类似的预训练模型之前,还需要进行一些额外的处理:
- 首先,这些图像的通道顺序为 RGB,我们需要重排他们的通道顺序为 BGR。
- 其次,预训练模型的输入都进行了额外的归一化过程。因此我们在这里也要对这些张量进行归一化,即对所有图像所有像素都减去像素均值
[103.939, 116.779, 123.68](以 RGB 模式表示,根据所有的 ImageNet 图像算出)。
导入的 preprocess_input 函数实现了这些功能。如果你对此很感兴趣,可以在 这里 查看 preprocess_input的代码。
在实现了图像处理的部分之后,我们就可以使用模型来进行预测。这一步通过 predict 方法来实现,它返回一个向量,向量的第 i 个元素表示该图像属于第 i 个 ImageNet 类别的概率。这通过如下的 ResNet50_predict_labels 函数实现。
通过对预测出的向量取用 argmax 函数(找到有最大概率值的下标序号),我们可以得到一个整数,即模型预测到的物体的类别。进而根据这个 清单,我们能够知道这具体是哪个品种的狗狗。
from keras.applications.resnet50 import preprocess_input, decode_predictions
def ResNet50_predict_labels(img_path):
# 返回img_path路径的图像的预测向量
img = preprocess_input(path_to_tensor(img_path))
return np.argmax(ResNet50_model.predict(img))
完成狗检测模型
在研究该 清单 的时候,你会注意到,狗类别对应的序号为151-268。因此,在检查预训练模型判断图像是否包含狗的时候,我们只需要检查如上的 ResNet50_predict_labels 函数是否返回一个介于151和268之间(包含区间端点)的值。
我们通过这些想法来完成下方的 dog_detector 函数,如果从图像中检测到狗就返回 True,否则返回 False。
def dog_detector(img_path):
prediction = ResNet50_predict_labels(img_path)
return ((prediction <= 268) & (prediction >= 151))
【作业】评估狗狗检测模型
问题 3:
在下方的代码块中,使用 dog_detector 函数,计算:
human_files_short中图像检测到狗狗的百分比?dog_files_short中图像检测到狗狗的百分比?
### TODO: 测试dog_detector函数在human_files_short和dog_files_short的表现
print(np.mean([dog_detector(human) for human in human_files_short]))
print(np.mean([dog_detector(dog) for dog in dog_files_short]))
步骤 3: 从头开始创建一个CNN来分类狗品种
现在我们已经实现了一个函数,能够在图像中识别人类及狗狗。但我们需要更进一步的方法,来对狗的类别进行识别。在这一步中,你需要实现一个卷积神经网络来对狗的品种进行分类。你需要从头实现你的卷积神经网络(在这一阶段,你还不能使用迁移学习),并且你需要达到超过1%的测试集准确率。在本项目的步骤五种,你还有机会使用迁移学习来实现一个准确率大大提高的模型。
在添加卷积层的时候,注意不要加上太多的(可训练的)层。更多的参数意味着更长的训练时间,也就是说你更可能需要一个 GPU 来加速训练过程。万幸的是,Keras 提供了能够轻松预测每次迭代(epoch)花费时间所需的函数。你可以据此推断你算法所需的训练时间。
值得注意的是,对狗的图像进行分类是一项极具挑战性的任务。因为即便是一个正常人,也很难区分布列塔尼犬和威尔士史宾格犬。
| 布列塔尼犬(Brittany) | 威尔士史宾格犬(Welsh Springer Spaniel) |
|---|---|
 |
 |
不难发现其他的狗品种会有很小的类间差别(比如金毛寻回犬和美国水猎犬)。
| 金毛寻回犬(Curly-Coated Retriever) | 美国水猎犬(American Water Spaniel) |
|---|---|
 |
 |
同样,拉布拉多犬(labradors)有黄色、棕色和黑色这三种。那么你设计的基于视觉的算法将不得不克服这种较高的类间差别,以达到能够将这些不同颜色的同类狗分到同一个品种中。
黄色拉布拉多犬(Yellow Labrador) | 棕色拉布拉多犬(Chocolate Labrador) | 黑色拉布拉多犬(Black Labrador)
- | -
![]() |
|![]() |
|![]()
 |
| |
|
我们也提到了随机分类将得到一个非常低的结果:不考虑品种略有失衡的影响,随机猜测到正确品种的概率是1/133,相对应的准确率是低于1%的。
请记住,在深度学习领域,实践远远高于理论。大量尝试不同的框架吧,相信你的直觉!当然,玩得开心!
数据预处理
通过对每张图像的像素值除以255,我们对图像实现了归一化处理。
from PIL import ImageFile
ImageFile.LOAD_TRUNCATED_IMAGES = True
# Keras中的数据预处理过程
train_tensors = paths_to_tensor(train_files).astype('float32')/255
valid_tensors = paths_to_tensor(valid_files).astype('float32')/255
test_tensors = paths_to_tensor(test_files).astype('float32')/255
【练习】模型架构
创建一个卷积神经网络来对狗品种进行分类。在你代码块的最后,执行 model.summary() 来输出你模型的总结信息。
我们已经帮你导入了一些所需的 Python 库,如有需要你可以自行导入。如果你在过程中遇到了困难,如下是给你的一点小提示——该模型能够在5个 epoch 内取得超过1%的测试准确率,并且能在CPU上很快地训练。
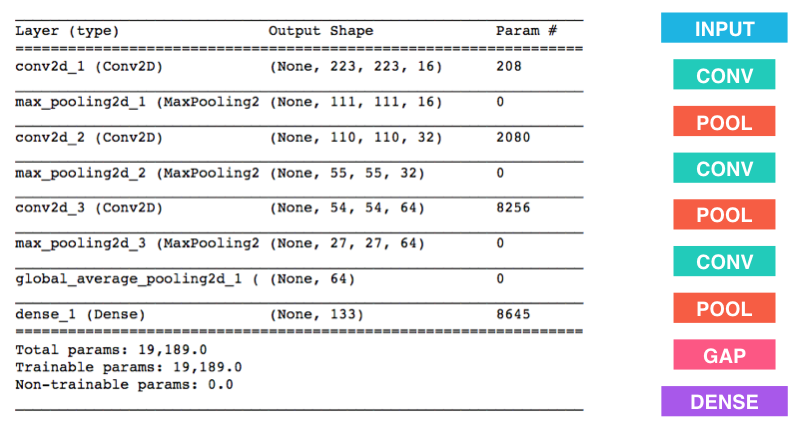
问题 4:
在下方的代码块中尝试使用 Keras 搭建卷积网络的架构,并回答相关的问题。
- 你可以尝试自己搭建一个卷积网络的模型,那么你需要回答你搭建卷积网络的具体步骤(用了哪些层)以及为什么这样搭建。
- 你也可以根据上图提示的步骤搭建卷积网络,那么请说明为何如上的架构能够在该问题上取得很好的表现。
回答: 我使用上图提示的步骤搭建卷积网络,该架构能取得很好表现的原因有: 1)卷积层对图片中的特征进行局部感知,以便后续从更高层次对局部进行综合操作,从而得到全局信息; 2)池化层用于特征降维,压缩数据和参数的数量,减小过拟合,同时提高模型的容错性;MaxPooling能够保留最强的特征,抛弃其他弱的此类特征。GlobalAveragePooling将最后一层的特征进行均值池化,形成一个特征点,将这些特征点组成最后的特征向量以进行softmax计算; 3)密集层里是高度提纯的特征,它将进行最后的分类;sigmoid的梯度在饱和区域非常平缓,接近于0,很容易造成梯度消失的问题。而Relu的梯度大多数情况下是常数,有助于解决深层网络的收敛问题。
from keras.layers import Conv2D, MaxPooling2D, GlobalAveragePooling2D
from keras.layers import Dropout, Flatten, Dense
from keras.models import Sequential
model = Sequential()
### TODO: 定义你的网络架构
model.add(Conv2D(filters=16, kernel_size=2, padding='valid', activation='relu',input_shape=(224,224,3)))
model.add(MaxPooling2D(pool_size=2))
model.add(Conv2D(filters=32, kernel_size=2, padding='valid', activation='relu'))
model.add(MaxPooling2D(pool_size=2))
model.add(Conv2D(filters=64, kernel_size=2, padding='valid', activation='relu'))
model.add(MaxPooling2D(pool_size=2))
model.add(GlobalAveragePooling2D(data_format='channels_last'))
model.add(Dense(133, activation='softmax'))
model.summary()
## 编译模型
model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
Tips:
提高准确率有很多小技巧~
- 你可以使劲往上加层,直到它在测试集上过拟合,然后再加正则化和数据增强
- 如果不过拟合了,再接着往上加层
通常模型的大小取决于数据的量和复杂度,但是如果你使用max-pooling,你需要增加向上的每一层的神经元(比如你可以double一下)。通常在dense layer之前有2-5层,kernel size 3-5就差不多。你也可以用grid search找一组比较满意的参数~
常用的正则化方法:
- batch normalization. 防止梯度消失~你可以参阅这篇文章:Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
- Max-Norm regularization & Dropout. 你可以参阅这篇文章: Dropout: A Simple Way to Prevent Neural Networks from Overfitting
- L1 / L2 weight regularization
- Sparsity regularization (e.g. [Sparse deep belief net model for visual area V2] (http://web.eecs.umich.edu/~honglak/nips07-sparseDBN.pdf))
- Gradient clipping (在成本领域进行更彻底的搜索)
- Data augmentation. Data augmentation可以增加你的数据集,从而防止过度拟合。而且max-out units在最近的图像分类竞赛中很成功: Galaxy Zoo challenge on Kaggle 和 Classifying plankton with deep neural networks
(出自: some advices about how to improve the performance of Convolutional Neural Networks)
更多的阅读资料:
- What is maxout in neural network?
- What is the difference between max pooling and max out?
- Maxout Networks
【练习】训练模型
问题 5:
在下方代码单元训练模型。使用模型检查点(model checkpointing)来储存具有最低验证集 loss 的模型。
可选题:你也可以对训练集进行 数据增强,来优化模型的表现。
from keras.callbacks import ModelCheckpoint
### TODO: 设置训练模型的epochs的数量
epochs = 5
### 不要修改下方代码
checkpointer = ModelCheckpoint(filepath='saved_models/weights.best.from_scratch.hdf5',
verbose=1, save_best_only=True)
model.fit(train_tensors, train_targets,
validation_data=(valid_tensors, valid_targets),
epochs=epochs, batch_size=20, callbacks=[checkpointer], verbose=1)
## 加载具有最好验证loss的模型
model.load_weights('saved_models/weights.best.from_scratch.hdf5')
Tips:
- 从日志来看,到第5个epoch的时候validation loss还是在下降的,可以试试再多加几个epoch,直到validation loss不再下降为止,看看模型最好到什么程度~
-
或者可以使用keras里的回调函数,就是当validation loss开始上升的时候,就马上停止训练,是为了防止过拟合的,参考代码如下:
keras.callbacks.ModelCheckpoint(filepath, monitor='val_loss', verbose=0, save_best_only=False, save_weights_only=False, mode='auto', period=1) -
或者你也可以把epoch & model accuracy和epoch & model loss的关系图打印出来,然后找一个比较满意的epoch,参考代码如下:
# Fit the model
history = model.fit(X, Y, validation_split=0.33, epochs=150, batch_size=10, verbose=0)
# list all data in history
print(history.history.keys())
# summarize history for accuracy
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
# summarize history for loss
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
Tips:
如果你想让算法自动选择epoch参数,并且避免epoch过多造成过拟合,我推荐你使用Keras中提供的early stopping callback(提前结束)方法。early stopping可以基于一些指定的规则自动结束训练过程,比如说连续指定次数epoch验证集准确率或误差都没有进步等。你可以参照[Keras' callback]官方文档来了解更多。
更多阅读材料:
测试模型
在狗图像的测试数据集上试用你的模型。确保测试准确率大于1%。
# 获取测试数据集中每一个图像所预测的狗品种的index
dog_breed_predictions = [np.argmax(model.predict(np.expand_dims(tensor, axis=0))) for tensor in test_tensors]
# 报告测试准确率
test_accuracy = 100*np.sum(np.array(dog_breed_predictions)==np.argmax(test_targets, axis=1))/len(dog_breed_predictions)
print('Test accuracy: %.4f%%' % test_accuracy)
步骤 4: 使用一个CNN来区分狗的品种
使用 迁移学习(Transfer Learning)的方法,能帮助我们在不损失准确率的情况下大大减少训练时间。在以下步骤中,你可以尝试使用迁移学习来训练你自己的CNN。
得到从图像中提取的特征向量(Bottleneck Features)
bottleneck_features = np.load('/data/bottleneck_features/DogVGG16Data.npz')
train_VGG16 = bottleneck_features['train']
valid_VGG16 = bottleneck_features['valid']
test_VGG16 = bottleneck_features['test']
模型架构
该模型使用预训练的 VGG-16 模型作为固定的图像特征提取器,其中 VGG-16 最后一层卷积层的输出被直接输入到我们的模型。我们只需要添加一个全局平均池化层以及一个全连接层,其中全连接层使用 softmax 激活函数,对每一个狗的种类都包含一个节点。
VGG16_model = Sequential()
VGG16_model.add(GlobalAveragePooling2D(input_shape=train_VGG16.shape[1:]))
VGG16_model.add(Dense(133, activation='softmax'))
VGG16_model.summary()
## 编译模型
VGG16_model.compile(loss='categorical_crossentropy', optimizer='rmsprop', metrics=['accuracy'])
## 训练模型
checkpointer = ModelCheckpoint(filepath='saved_models/weights.best.VGG16.hdf5',
verbose=1, save_best_only=True)
VGG16_model.fit(train_VGG16, train_targets,
validation_data=(valid_VGG16, valid_targets),
epochs=20, batch_size=20, callbacks=[checkpointer], verbose=1)
## 加载具有最好验证loss的模型
VGG16_model.load_weights('saved_models/weights.best.VGG16.hdf5')
Tips:推荐使用Adam [Ref] 或者 Adagrad[Ref]作为优化器,这也是目前最常使用的优化器算法。想要了解更多的话, An overview of gradient descent optimization algorithms这篇文章介绍了当前流行的一些优化器算法的优劣比较,Usage of optimizers in Keras这篇文章介绍了Keras中各类优化器的使用方法。
测试模型
现在,我们可以测试此CNN在狗图像测试数据集中识别品种的效果如何。我们在下方打印出测试准确率。
# 获取测试数据集中每一个图像所预测的狗品种的index
VGG16_predictions = [np.argmax(VGG16_model.predict(np.expand_dims(feature, axis=0))) for feature in test_VGG16]
# 报告测试准确率
test_accuracy = 100*np.sum(np.array(VGG16_predictions)==np.argmax(test_targets, axis=1))/len(VGG16_predictions)
print('Test accuracy: %.4f%%' % test_accuracy)
使用模型预测狗的品种
from extract_bottleneck_features import *
def VGG16_predict_breed(img_path):
# 提取bottleneck特征
bottleneck_feature = extract_VGG16(path_to_tensor(img_path))
# 获取预测向量
predicted_vector = VGG16_model.predict(bottleneck_feature)
# 返回此模型预测的狗的品种
return dog_names[np.argmax(predicted_vector)]
步骤 5: 建立一个CNN来分类狗的品种(使用迁移学习)
现在你将使用迁移学习来建立一个CNN,从而可以从图像中识别狗的品种。你的 CNN 在测试集上的准确率必须至少达到60%。
在步骤4中,我们使用了迁移学习来创建一个使用基于 VGG-16 提取的特征向量来搭建一个 CNN。在本部分内容中,你必须使用另一个预训练模型来搭建一个 CNN。为了让这个任务更易实现,我们已经预先对目前 keras 中可用的几种网络进行了预训练:
- VGG-19 bottleneck features
- ResNet-50 bottleneck features
- Inception bottleneck features
- Xception bottleneck features
这些文件被命名为为:
Dog{network}Data.npz其中 {network} 可以是 VGG19、Resnet50、InceptionV3 或 Xception 中的一个。选择上方网络架构中的一个,他们已经保存在目录 /data/bottleneck_features/ 中。
【练习】获取模型的特征向量
在下方代码块中,通过运行下方代码提取训练、测试与验证集相对应的bottleneck特征。
bottleneck_features = np.load('/data/bottleneck_features/Dog{network}Data.npz')
train_{network} = bottleneck_features['train']
valid_{network} = bottleneck_features['valid']
test_{network} = bottleneck_features['test']### TODO: 从另一个预训练的CNN获取bottleneck特征
bottleneck_features = np.load('/data/bottleneck_features/DogXceptionData.npz')
train_Xception = bottleneck_features['train']
valid_Xception = bottleneck_features['valid']
test_Xception = bottleneck_features['test']
当下比较主流的架构非ResNet-50和Xception莫属~轻易就能达到80%以上的准确率~
关于四个架构的区别,请参考这篇文章:ImageNet: VGGNet, ResNet, Inception, and Xception with Keras
Tips:
更多阅读材料:
- ResNet, AlexNet, VGGNet, Inception: Understanding various architectures of Convolutional Networks
- (上一篇的中文翻译版)ResNet, AlexNet, VGG, Inception: 理解各种各样的CNN架构
- Systematic evaluation of CNN advances on the ImageNet
【练习】模型架构
建立一个CNN来分类狗品种。在你的代码单元块的最后,通过运行如下代码输出网络的结构:
<your model's name>.summary()
问题 6:
在下方的代码块中尝试使用 Keras 搭建最终的网络架构,并回答你实现最终 CNN 架构的步骤与每一步的作用,并描述你在迁移学习过程中,使用该网络架构的原因。
回答: 1)将Xception最后一层的输出作为全局平均池化层的输入; 2)增加一个全连接层,使用softmax激活函数,节点数设置为狗的种类数133。 选用Xception是因为该模型在狗狗分类中准确率较高; 这一架构会在这一分类任务中成功的原因: 1)利用迁移学习获取了优良的模型和参数; 2)训练次数提高到了20次; 早期(第三步)尝试不成功的原因: 1)模型相对来说没有迁移学习中的好; 2)训练次数只有5次,太少了。
### TODO: 定义你的框架
Xception_model = Sequential()
Xception_model.add(GlobalAveragePooling2D(input_shape=train_Xception.shape[1:]))
Xception_model.add(Dense(133, activation='softmax'))
Xception_model.summary()
### TODO: 编译模型
Xception_model.compile(loss='categorical_crossentropy', optimizer='rmsprop', metrics=['accuracy'])
Tips:推荐尝试一下Adam优化器的,时下比较流行,相比于AdaGrad, RMSProp, SGDNesterov 和 AdaDelta来说效率更高~可以参考一下这篇文章:Gentle Introduction to the Adam Optimization Algorithm for Deep Learning
【练习】训练模型
问题 7:
在下方代码单元中训练你的模型。使用模型检查点(model checkpointing)来储存具有最低验证集 loss 的模型。
当然,你也可以对训练集进行 数据增强 以优化模型的表现,不过这不是必须的步骤。
### TODO: 训练模型
checkpointer = ModelCheckpoint(filepath='saved_models/weights.best.Xception.hdf5', verbose=1, save_best_only=True)
Xception_model.fit(train_Xception, train_targets, validation_data=(valid_Xception, valid_targets), epochs=20, batch_size=20, callbacks=[checkpointer], verbose=1)
### TODO: 加载具有最佳验证loss的模型权重
Xception_model.load_weights('saved_models/weights.best.Xception.hdf5')
Tips:
训练过程中,注意到第2次epoch之后验证误差就几乎没有提升了,同时因为你保存了最优模型,意味着你后面的训练都是在浪费计算资源;同时也观察到,第20次epoch时,验证误差远大于训练误差,这说明模型出现了过拟合。思考并尝试尽量减轻这种过拟合现象吧~
提示:
- 添加dropout层可以很有效的避免模型过拟合;
- 添加batch normalization层可以降低Covariate Shift并加速运算过程,也能带来一些降低过拟合的效果;
- 数据增强(data augmentation)也可以增加模型的鲁棒性和泛化能力。
你可以用可视化的形式将训练过程中的loss曲线输出到notebook中,具体参考Display Deep Learning Model Training History in Keras这篇文章,这样可以让训练过程更为直观,你可以更方便地判断模型是否出现了欠拟合或过拟合。
【练习】测试模型
问题 8:
在狗图像的测试数据集上试用你的模型。确保测试准确率大于60%。
### TODO: 在测试集上计算分类准确率
Xception_predictions = [np.argmax(Xception_model.predict(np.expand_dims(feature, axis=0))) for feature in test_Xception]
test_accuracy = 100*np.sum(np.array(Xception_predictions)==np.argmax(test_targets, axis=1))/len(Xception_predictions)
print('Test accuracy: %.4f%%' % test_accuracy)
【练习】使用模型测试狗的品种
实现一个函数,它的输入为图像路径,功能为预测对应图像的类别,输出为你模型预测出的狗类别(Affenpinscher, Afghan_hound 等)。
与步骤5中的模拟函数类似,你的函数应当包含如下三个步骤:
- 根据选定的模型载入图像特征(bottleneck features)
- 将图像特征输输入到你的模型中,并返回预测向量。注意,在该向量上使用 argmax 函数可以返回狗种类的序号。
- 使用在步骤0中定义的
dog_names数组来返回对应的狗种类名称。
提取图像特征过程中使用到的函数可以在 extract_bottleneck_features.py 中找到。同时,他们应已在之前的代码块中被导入。根据你选定的 CNN 网络,你可以使用 extract_{network} 函数来获得对应的图像特征,其中 {network} 代表 VGG19, Resnet50, InceptionV3, 或 Xception 中的一个。
问题 9:
### TODO: 写一个函数,该函数将图像的路径作为输入
### 然后返回此模型所预测的狗的品种
def Xception_predict_breed(img_path):
bottleneck_feature = extract_Xception(path_to_tensor(img_path))
predicted_vector = Xception_model.predict(bottleneck_feature)
return dog_names[np.argmax(predicted_vector)]
步骤 6: 完成你的算法
实现一个算法,它的输入为图像的路径,它能够区分图像是否包含一个人、狗或两者都不包含,然后:
- 如果从图像中检测到一只狗,返回被预测的品种。
- 如果从图像中检测到人,返回最相像的狗品种。
- 如果两者都不能在图像中检测到,输出错误提示。
我们非常欢迎你来自己编写检测图像中人类与狗的函数,你可以随意地使用上方完成的 face_detector 和 dog_detector 函数。你需要在步骤5使用你的CNN来预测狗品种。
下面提供了算法的示例输出,但你可以自由地设计自己的模型!
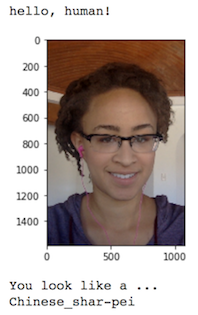
问题 10:
在下方代码块中完成你的代码。
### TODO: 设计你的算法
### 自由地使用所需的代码单元数吧
def dog_check(img_path):
if dog_detector(img_path):
print('It''s a dog. It looks like ')
print(Xception_predict_breed(img_path))
elif face_detector(img_path):
print('It''s human. It looks like ')
print(Xception_predict_breed(img_path))
else:
print('Error!')
Tips:
以下是一些改进模型建议:
建议被分为4个子类:
- 数据 (Data)
- 算法 (algorithms)
- 算法调参 (algorithm tuning)
- 模型融合 (ensembles)
详细信息请参阅这篇:How To Improve Deep Learning Performance
Tips:
推荐阅读以下材料来加深对 CNN和Transfer Learning的理解:
- CS231n: Convolutional Neural Networks for Visual Recognition
- Using Convolutional Neural Networks to Classify Dog Breeds
- Building an Image Classifier
- Tips/Tricks in CNN
- Transfer Learning using Keras
- Transfer Learning in TensorFlow on the Kaggle Rainforest competition
- Transfer Learning and Fine-tuning
相关论文:
- [VGG16] VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION
- [Inception-v1] Going deeper with convolutions
- [Inception-v3] Rethinking the Inception Architecture for Computer Vision
- [Inception-v4] Inception-ResNet and the Impact of Residual Connections on Learning
- [ResNet] Deep Residual Learning for Image Recognition
- [Xception] Deep Learning with Depthwise Separable Convolutions
Tips:
以下是对改进模型提出的建议:
- 交叉验证(Cross Validation)
在本次训练中,我们只进行了一次训练集/测试集切分,而在实际模型训练过程中,我们往往是使用交叉验证(Cross Validation)来进行模型选择(Model Selection)和调参(Parameter Tunning)的。交叉验证的通常做法是,按照某种方式多次进行训练集/测试集切分,最终取平均值(加权平均值),具体可以参考维基百科的介绍。 - 模型融合/集成学习(Model Ensembling)
通过利用一些机器学习中模型融合的技术,如voting、bagging、blending以及staking等,可以显著提高模型的准确率与鲁棒性,且几乎没有风险。你可以参考我整理的机器学习笔记中的Ensemble部分。 - 更多的数据
对于深度学习(机器学习)任务来说,更多的数据意味着更为丰富的输入空间,可以带来更好的训练效果。我们可以通过数据增强(Data Augmentation)、对抗生成网络(Generative Adversarial Networks)等方式来对数据集进行扩充,同时这种方式也能提升模型的鲁棒性。 - 更换人脸检测算法
尽管OpenCV工具包非常方便并且高效,Haar级联检测也是一个可以直接使用的强力算法,但是这些算法仍然不能获得很高的准确率,并且需要用户提供正面照片,这带来的一定的不便。所以如果想要获得更好的用户体验和准确率,我们可以尝试一些新的人脸识别算法,如基于深度学习的一些算法。 - 多目标监测
更进一步,我们可以通过一些先进的目标识别算法,如RCNN、Fast-RCNN、Faster-RCNN或Masked-RCNN等,来完成一张照片中同时出现多个目标的检测任务。
Tips:想要从事Computer Vision领域相关研究和工作的话,除了image classification之外,还要学习image segmentation、object detection、image generation等。
posted on 2018-12-06 20:15 paulonetwo 阅读(5036) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号