

Linux内核实验作业六
实验作业:分析Linux内核创建一个新进程的过程
20135313吴子怡.北京电子科技学院
【第一部分】阅读理解task_struct数据结构
1.进程是计算机中已运行程序的实体。在面向线程设计的系统(Linux 2.6及更新的版本)中,进程本身不是基本运行单位,而是线程的容器。
2.在Linux中,task_struct其实就是通常所说的PCB。该结构定义位于:
/include/linux/sched.h
3.task_struct比较庞大,其中比较重要的几个参数:
volatile long state;进程状态【可见/include/linux/sched.h文件中的宏,TASK_RUNNING等】实时优先级
unsigned int rt_priority;调度策略
unsigned int policy;real parent
struct task_struct __rcu *real_parent;list of my children
struct list_head children;进程标识符
pid_t pid;系统打开文件
struct files_struct *files;
4.操作系统的三大功能:进程管理、内存管理和文件系统
5.进程控制块PCB——task_struct
1)进程在TASK_RUNNING下是可运行的,但它有没有运行取决于它有没有获得cpu的控制权,即这个进程有没有在cpu上实际的执行
2)进程的标示pid
3)程序创建的进程具有父子关系,在编程时往往需要引用这样的父子关系。进程描述符中有几个域用来表示这样的关系。
【第二部分】分析fork函数对应的内核处理过程sys_clone,理解创建一个新进程如何创建和修改task_struct数据结构
1.Linux中创建进程一共有三个函数:
fork,创建子进程 vfork,与fork类似,但是父子进程共享地址空间,而且子进程先于父进程运行。 clone,主要用于创建线程
【fork是通过触发0x80中断,陷入内核,来使用内核提供的提供调用。】
SYSCALL_DEFINE0(fork)
{
return do_fork(SIGCHLD, 0, 0, NULL, NULL);
}
#endif
SYSCALL_DEFINE0(vfork)
{
return do_fork(CLONE_VFORK | CLONE_VM | SIGCHLD, 0,
0, NULL, NULL);
}
SYSCALL_DEFINE5(clone, unsigned long, clone_flags, unsigned long, newsp,
int __user *, parent_tidptr,
int __user *, child_tidptr,
int, tls_val)
{
return do_fork(clone_flags, newsp, 0, parent_tidptr, child_tidptr);
}
分析:fork、vfork和clone这三个函数最终都是通过do_fork函数实现的。
3.分析do_fork的代码:
long do_fork(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr)
{
struct task_struct *p;
int trace = 0;
long nr;
// ...
// 复制进程描述符,返回创建的task_struct的指针
p = copy_process(clone_flags, stack_start, stack_size,
child_tidptr, NULL, trace);
if (!IS_ERR(p)) {
struct completion vfork;
struct pid *pid;
trace_sched_process_fork(current, p);
// 取出task结构体内的pid
pid = get_task_pid(p, PIDTYPE_PID);
nr = pid_vnr(pid);
if (clone_flags & CLONE_PARENT_SETTID)
put_user(nr, parent_tidptr);
// 如果使用的是vfork,那么必须采用某种完成机制,确保父进程后运行
if (clone_flags & CLONE_VFORK) {
p->vfork_done = &vfork;
init_completion(&vfork);
get_task_struct(p);
}
// 将子进程添加到调度器的队列,使得子进程有机会获得CPU
wake_up_new_task(p);
// ...
// 如果设置了 CLONE_VFORK 则将父进程插入等待队列,并挂起父进程直到子进程释放自己的内存空间
// 保证子进程优先于父进程运行
if (clone_flags & CLONE_VFORK) {
if (!wait_for_vfork_done(p, &vfork))
ptrace_event_pid(PTRACE_EVENT_VFORK_DONE, pid);
}
put_pid(pid);
} else {
nr = PTR_ERR(p);
}
return nr;
}
do_fork处理了以下内容:
1. 调用copy_process,将当期进程复制一份出来为子进程,并且为子进程设置相应地上下文信息。
2. 初始化vfork的完成处理信息(如果是vfork调用)
3. 调用wake_up_new_task,将子进程放入调度器的队列中,此时的子进程就可以被调度进程选中,得以运行。
4. 如果是vfork调用,需要阻塞父进程,知道子进程执行exec。上面的过程对vfork稍微做了处理,因为vfork必须保证子进程优先运行,执行exec,替换自己的地址空间。抛开vfork,进程创建的大部分过程都在copy_process函数中。
4.进程创建的关键copy_process【以下指示部分关键代码】
/*
创建进程描述符以及子进程所需要的其他所有数据结构
为子进程准备运行环境
*/
static struct task_struct *copy_process(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *child_tidptr,
struct pid *pid,
int trace)
{
int retval;
struct task_struct *p;
// 分配一个新的task_struct,此时的p与当前进程的task,仅仅是stack地址不同
p = dup_task_struct(current);
// 检查该用户的进程数是否超过限制
if (atomic_read(&p->real_cred->user->processes) >=
task_rlimit(p, RLIMIT_NPROC)) {
// 检查该用户是否具有相关权限,不一定是root
if (p->real_cred->user != INIT_USER &&
!capable(CAP_SYS_RESOURCE) && !capable(CAP_SYS_ADMIN))
goto bad_fork_free;
}
retval = -EAGAIN;
// 检查进程数量是否超过 max_threads,后者取决于内存的大小
if (nr_threads >= max_threads)
goto bad_fork_cleanup_count;
// 初始化自旋锁
// 初始化挂起信号
// 初始化定时器
// 完成对新进程调度程序数据结构的初始化,并把新进程的状态设置为TASK_RUNNING
retval = sched_fork(clone_flags, p);
// .....
// 复制所有的进程信息
// copy_xyz
// 初始化子进程的内核栈
retval = copy_thread(clone_flags, stack_start, stack_size, p);
if (retval)
goto bad_fork_cleanup_io;
if (pid != &init_struct_pid) {
retval = -ENOMEM;
// 这里为子进程分配了新的pid号
pid = alloc_pid(p->nsproxy->pid_ns_for_children);
if (!pid)
goto bad_fork_cleanup_io;
}
/* ok, now we should be set up.. */
// 设置子进程的pid
p->pid = pid_nr(pid);
// 如果是创建线程
if (clone_flags & CLONE_THREAD) {
p->exit_signal = -1;
// 线程组的leader设置为当前线程的leader
p->group_leader = current->group_leader;
// tgid是当前线程组的id,也就是main进程的pid
p->tgid = current->tgid;
} else {
if (clone_flags & CLONE_PARENT)
p->exit_signal = current->group_leader->exit_signal;
else
p->exit_signal = (clone_flags & CSIGNAL);
// 创建的是进程,自己是一个单独的线程组
p->group_leader = p;
// tgid和pid相同
p->tgid = p->pid;
}
if (clone_flags & (CLONE_PARENT|CLONE_THREAD)) {
// 如果是创建线程,那么同一线程组内的所有线程、进程共享parent
p->real_parent = current->real_parent;
p->parent_exec_id = current->parent_exec_id;
} else {
// 如果是创建进程,当前进程就是子进程的parent
p->real_parent = current;
p->parent_exec_id = current->self_exec_id;
}
// 将pid加入PIDTYPE_PID这个散列表
attach_pid(p, PIDTYPE_PID);
// 递增 nr_threads的值
nr_threads++;
// 返回被创建的task结构体指针
return p;
}
分析copy_process的大体流程:
1. 检查各种标志位(已经省略)
2. 调用dup_task_struct复制一份task_struct结构体,作为子进程的进程描述符。
3. 检查进程的数量限制。
4. 初始化定时器、信号和自旋锁。
5. 初始化与调度有关的数据结构,调用了sched_fork,这里将子进程的state设置为TASK_RUNNING。
6. 复制所有的进程信息,包括fs、信号处理函数、信号、内存空间(包括写时复制)等。
7. 调用copy_thread,这又是关键的一步,这里设置了子进程的堆栈信息。
8. 为子进程分配一个pid
9. 设置子进程与其他进程的关系,以及pid、tgid等。这里主要是对线程做一些区分。简化后的代码如下:
static struct task_struct *dup_task_struct(struct task_struct *orig)
{
struct task_struct *tsk;
struct thread_info *ti;
int node = tsk_fork_get_node(orig);
int err;
// 分配一个task_struct结点
tsk = alloc_task_struct_node(node);
if (!tsk)
return NULL;
// 分配一个thread_info结点,其实内部分配了一个union,包含进程的内核栈
// 此时ti的值为栈底,在x86下为union的高地址处。
ti = alloc_thread_info_node(tsk, node);
if (!ti)
goto free_tsk;
err = arch_dup_task_struct(tsk, orig);
if (err)
goto free_ti;
// 将栈底的值赋给新结点的stack
tsk->stack = ti;
// ...
// 返回新申请的结点
return tsk;
}
dup_task_struct的代码要结合一个联合体的定义来分析。
union thread_union {
struct thread_info thread_info;
unsigned long stack[THREAD_SIZE/sizeof(long)];
};
分析:x86体系结构的栈空间,按照从高到低的方式增长。而C中的结构体,是按从低到高的方式使用。因此我们声明一个联合体,低地址用作thread_info,高地址用作栈底。这样做还有一个好处,就是thread_info中存放着一个task_struct的指针,这样我们根据栈底地址就可以通过thread_info快速定位到进程对应的task_struct指针。
在dup_task_struct中:
1. 先调用alloc_task_struct_node分配一个task_struct结构体。
2. 调用alloc_thread_info_node,分配了一个union,注意,这里不仅仅分配了一个thread_info结构体,还分配了一个stack数组。返回值为ti,实际上就是栈底。
3. tsk->stack = ti;这句话,就是将栈底的地址赋给task的stack变量。所以,最后为子进程分配了内核栈空间。
执行完dup_task_struct之后,子进程和父进程的task结构体,除了stack指针之外,完全相同。
在copy_process中,copy_thread函数为子进程准备了上下文堆栈信息。代码如下:
// 初始化子进程的内核栈
int copy_thread(unsigned long clone_flags, unsigned long sp,
unsigned long arg, struct task_struct *p)
{
// 获取寄存器信息
struct pt_regs *childregs = task_pt_regs(p);
struct task_struct *tsk;
int err;
// 栈顶 空栈
p->thread.sp = (unsigned long) childregs;
p->thread.sp0 = (unsigned long) (childregs+1);
memset(p->thread.ptrace_bps, 0, sizeof(p->thread.ptrace_bps));
// 如果是创建的内核线程
if (unlikely(p->flags & PF_KTHREAD)) {
/* kernel thread */
memset(childregs, 0, sizeof(struct pt_regs));
// 内核线程开始执行的位置
p->thread.ip = (unsigned long) ret_from_kernel_thread;
task_user_gs(p) = __KERNEL_STACK_CANARY;
childregs->ds = __USER_DS;
childregs->es = __USER_DS;
childregs->fs = __KERNEL_PERCPU;
childregs->bx = sp; /* function */
childregs->bp = arg;
childregs->orig_ax = -1;
childregs->cs = __KERNEL_CS | get_kernel_rpl();
childregs->flags = X86_EFLAGS_IF | X86_EFLAGS_FIXED;
p->thread.io_bitmap_ptr = NULL;
return 0;
}
// 将当前进程的寄存器信息复制给子进程
*childregs = *current_pt_regs();
// 子进程的eax置为0,所以fork的子进程返回值为0
childregs->ax = 0;
if (sp)
childregs->sp = sp;
// 子进程从ret_from_fork开始执行
p->thread.ip = (unsigned long) ret_from_fork;
task_user_gs(p) = get_user_gs(current_pt_regs());
return err;
}
分析:copy_thread的流程如下:
1. 获取子进程寄存器信息的存放位置
2. 对子进程的thread.sp赋值,将来子进程运行,这就是子进程的esp寄存器的值。
3. 如果是创建内核线程,那么它的运行位置是ret_from_kernel_thread,将这段代码的地址赋给thread.ip,之后准备其他寄存器信息,退出
4. 将父进程的寄存器信息复制给子进程。
5. 将子进程的eax寄存器值设置为0,所以fork调用在子进程中的返回值为0.
6. 子进程从ret_from_fork开始执行,所以它的地址赋给thread.ip,也就是将来的eip寄存器。子进程复制了父进程的上下文信息,仅仅对某些地方做了改动,运行逻辑和父进程完全一致。
另外,子进程从ret_from_fork处开始执行。
7.新进程的执行新进程从ret_from_fork处开始执行,子进程的运行是由这几处保证的:
1. dup_task_struct中为其分配了新的堆栈
2. copy_process中调用了sched_fork,将其置为TASK_RUNNING
3. copy_thread中将父进程的寄存器上下文复制给子进程,这是非常关键的一步,这里保证了父子进程的堆栈信息是一致的。
4. 将ret_from_fork的地址设置为eip寄存器的值,这是子进程的第一条指令。【第三部分】使用gdb跟踪分析一个fork系统调用内核处理函数sys_clone ,创建一个新进程
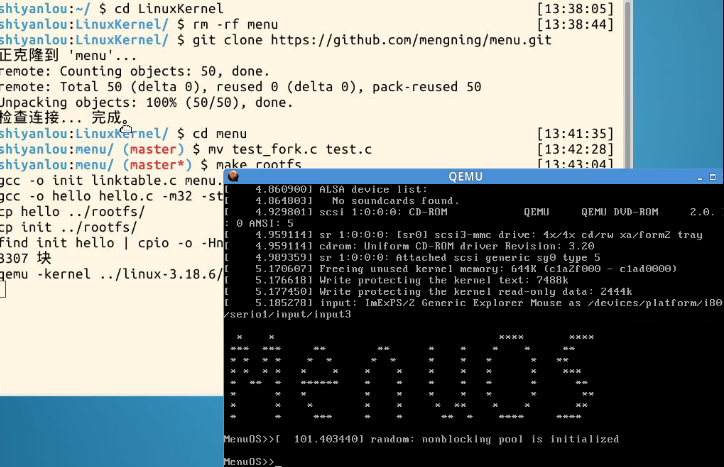
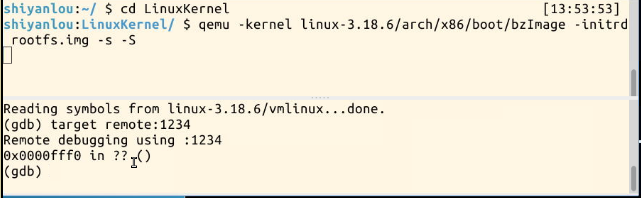
①首先,设置以下断点:

②运行后首先停在sys_clone处:



⑤在copy_thread中,我们可以查看p的值

⑥返回copy_process后再查看,将得到一个value optimized out的提示,这是因为Linux内核打开gcc的-O2选项优化导致。

⑦ret_from_fork按照之前的分析被调用,跟踪到syscall_exit后无法继续.如果想在本机调试system call,那么当你进入system call时,系统已经在挂起状态了。如果想要跟踪调试system_call,可以使用kgdb等

【第四部分】新进程是从哪里开始执行的?为什么从哪里能顺利执行下去?执行起点与内核堆栈如何保证一致?
【Q1&2】//函数copy_process中的copy_thread()//
int copy_thread(unsigned long clone_flags, unsigned long sp,
unsigned long arg, struct task_struct *p)
{
...
*childregs = *current_pt_regs();
childregs->ax = 0;
if (sp)
childregs->sp = sp;
p->thread.ip = (unsigned long) ret_from_fork;
...
}
//子进程执行ret_from_fork//
ENTRY(ret_from_fork)
CFI_STARTPROC
pushl_cfi %eax
call schedule_tail
GET_THREAD_INFO(%ebp)
popl_cfi %eax
pushl_cfi $0x0202 # Reset kernel eflags
popfl_cfi
jmp syscall_exit
CFI_ENDPROC
END(ret_from_fork)
首先有两个小问题:
①为什么 fork 在子进程中返回0?原因是childregs->ax = 0;这段代码将子进程的 eax 赋值为0。
②p->thread.ip = (unsigned long) ret_from_fork;这句代码将子进程的 ip 设置为 ret_form_fork 的首地址,因此子进程是从 ret_from_fork 开始执行的。
copy_thread()决定了子进程从系统调用中返回后的执行。在ret_from_fork之前,也就是在copy_thread()函数中:
*childregs = *current_pt_regs();
该句将父进程的regs参数赋值到子进程的内核堆栈,*childregs的类型为pt_regs,里面存放了SAVE ALL中压入栈的参数。故在之后的RESTORE ALL中能顺利执行下去。
【第五部分】总结
“Linux系统创建一个新进程”的理解
Linux通过复制父进程来创建一个新进程,通过调用do_fork来实现并为每个新创建的进程动态地分配一个task_struct结构。为了把内核中的所有进程组织起来,Linux提供了几种组织方式,其中哈希表和双向循环链表方式是针对系统中的所有进程(包括内核线程),而运行队列和等待队列是把处于同一状态的进程组织起来。
fork()函数被调用一次,但返回两次。
以下是进程创建流程图:

可以通过fork,复制一个已有的进程,进而产生一个子进程,新进程几乎但不完全与父进程相同。子进程得到和父进程用户级虚拟地址空间相同的一份拷贝,包括代码段,数据段和bss段,堆以及用户栈。子进程还获得和父进程任何打开文件描述符相同的拷贝,最大的区别就是在于他们拥有不同的PID.
【第六部分】附录
学习笔记请走链接:点我!
作者:吴子怡
学号:20135313
原创作品转载请注明出处
《Linux内核分析》MOOC课程http://mooc.study.163.com/course/USTC-1000029000

 浙公网安备 33010602011771号
浙公网安备 33010602011771号