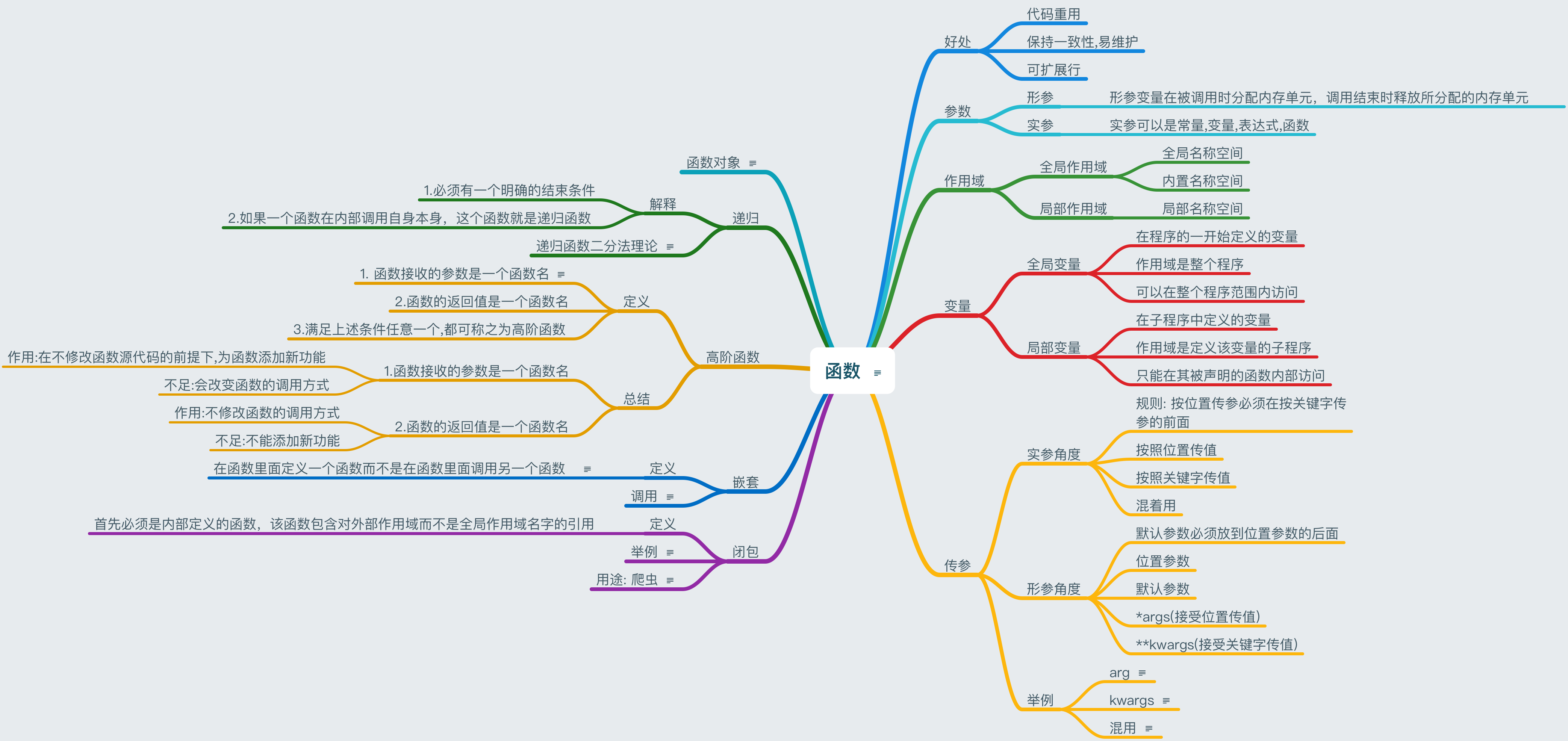
- 函数
-
- 好处
- 参数
- 形参
- 形参变量在被调用时分配内存单元,调用结束时释放所分配的内存单元
- 实参
- 作用域
- 变量
- 全局变量
- 在程序的一开始定义的变量
- 作用域是整个程序
- 可以在整个程序范围内访问
- 局部变量
- 在子程序中定义的变量
- 作用域是定义该变量的子程序
- 只能在其被声明的函数内部访问
- 传参
- 实参角度
- 规则: 按位置传参必须在按关键字传参的前面
- 按照位置传值
- 按照关键字传值
- 混着用
- 形参角度
- 默认参数必须放到位置参数的后面
- 位置参数
- 默认参数
- *args(接受位置传值)
- **kwargs(接受关键字传值)
- 举例
- arg
- def fun_var_args(farg, *args):
- print('args:', farg)
- print(args)
- print(*args)
- for value in args:
- print('another arg:',value)
- # *args可以当作可容纳多个变量组成的list或tuple
- fun_var_args(1, 'two', 3, None)
- #args: 1
- #('two', 3, None)
- #two 3 None
- #another arg: two
- #another arg: 3
- ———————————————————————
- def fun_args(arg1, arg2, arg3):
- print ('arg1:', arg1)
- print ('arg2:', arg2)
- print ('arg3:', arg3)
- myargs = ['1', 'two', None] # 定义列表
- fun_args(*myargs)
- # 输出:
- #arg1: 1
- #arg2: two
- #arg3: None
- kwargs
- def fun_var_kwargs(farg, **kwargs):
- print('args:', farg)
- # print(**kwargs) #直接报错
- print(kwargs)
- for key in kwargs:
- print('another keyword arg:%s:%s' % (key, kwargs[key]))
- # myarg1,myarg2和myarg3被视为key, 感觉**kwargs可以当作容纳多个key和value的dictionary
-
- fun_var_kwargs(1, myarg1='two', myarg2=3, myarg3=None)
-
- --------------------------------------------
- #args: 1
- #{'myarg2': 3, 'myarg1': 'two', 'myarg3': None}
- #another keyword arg:myarg2:3
- #another keyword arg:myarg1:two
- #another keyword arg:myarg3:None
- #######################################################
- def fun_args(arg1, arg2, arg3):
- print ('arg1:', arg1)
- print ('arg2:', arg2)
- print ('arg3:', arg3)
- mykwargs = {'arg1': '1', 'arg2': 'two', 'arg3': None} # 定义字典类型
- fun_args(**mykwargs)
- # 输出:
- #arg1: 1
- #arg2: two
- #arg3: None
- 混用
- def fun_args_kwargs(*args, **kwargs):
- print ('args:', args)
- print ('kwargs:', kwargs)
- args = [1, 2, 3, 4]
- kwargs = {'name': 'BeginMan', 'age': 22}
- fun_args_kwargs(*args,**kwargs)
- -------------------------------------------
- args: (1, 2, 3, 4)
- kwargs: {'age': 22, 'name': 'BeginMan'}
- -------------------------------------------
- fun_args_kwargs(1,2,3,a=100)
- #args: (1, 2, 3)
- #kwargs: {'a': 100}
- —————————————————————
- fun_args_kwargs(*(1,2,3,4),**{'a':None})
- #args: (1, 2, 3, 4)
- #kwargs: {'a': None}
- 闭包
- 定义
- 首先必须是内部定义的函数,该函数包含对外部作用域而不是全局作用域名字的引用
- 举例
- #闭包
- x=1000000000
- def f1():
- x=1
- y=2
- def f2():
- print(x)
- print(y)
- return f2 #返回得f2不仅是返回了f2函数局部作用域还返回了引用的外部作用域的变量
- f=f1()
- print(f)
- print(f.__closure__)#必须是闭包才能用此命令
- print(f.__closure__[0].cell_contents)#查看值
- print(f.__closure__[1].cell_contents)
- -------------------------------------------------------------------------------------------------------------------------------###############################################################################################################################
- <function f1.<locals>.f2 at 0x0000000000A7E1E0>
- (<cell at 0x0000000000686D08: int object at 0x000000005E5522D0>, <cell at 0x0000000000686D38: int object at 0x000000005E5522F0>)
- #代表引用外部作用域变量的个数
- 1 #代表f2引用了,f1中的x=1
- 2 #代表f2引用了,f2中的y=2
- 用途: 爬虫
- #爬虫
- from urllib.request import urlopen
- def get(url):
- return urlopen(url).read()
- print(get('http://www.baidu.com'))
-
-
- #专门爬百度页面
- def f1(url):
- def f2():
- print(urlopen(url).read())
- return f2 #返回的是f2的内存地址 和 url
- baidu=f1('http://www.baidu.com')#等式右边就是return的值,也就是f2的内存地址
- #此时的baidu包括f2的内存地址和url外部变量
- baidu()
- baidu()
- baidu()
- baidu()
- 嵌套
- 定义
- 在函数里面定义一个函数而不是在函数里面调用另一个函数
- x=1111111
- def f1():
- x=1
- print("----->f1",x)
- def f2():
- x=2
- print("---->f2",x)
- def f3():
- x=3
- print("--->f3",x)
- f3()
- f2()
- f1()
- 调用
- def my_max(x,y)
- res=x id x>y else y
- return res
- print(my_max(10,100))
-
- def my_max1(a,b,c,d):
- res1=my_max(a,b)
- #调用上面的函数
- res2=my_max(res1,c)
- res3=my_max(res2,d)
- return res3
- print(my_max1(1,23,34,4))
- 高阶函数
- 定义
- 1. 函数接收的参数是一个函数名
- import time
def foo():
time.sleep(3)
print("egon is a dog")
def test(func):
start_time = time.time()
func()
stop_time = time.time()
print("函数运行时间%s"%(stop_time-start_time))
test(foo)
- 2.函数的返回值是一个函数名
- 3.满足上述条件任意一个,都可称之为高阶函数
- 总结
- 1.函数接收的参数是一个函数名
- 作用:在不修改函数源代码的前提下,为函数添加新功能
- 不足:会改变函数的调用方式
- 2.函数的返回值是一个函数名
- 递归
- 解释
- 1.必须有一个明确的结束条件
- 2.如果一个函数在内部调用自身本身,这个函数就是递归函数
- 递归函数二分法理论
- data = [1, 3, 6, 7, 9, 12, 14, 16, 17, 18, 20, 21, 22, 23, 30, 32, 33, 35]
- def search(num,data):
- print(data)
- if len(data) > 1:
- mid_index=int(len(data)/2)
- mid_value=data[mid_index]
- if num > mid_value:
- data = data[mid_index:]
- return search(num,data)
- elif num < mid_value:
- data = data[:mid_index]
- return search(num,data)#这里的return是下一个search函数的return值
- else:
- print('find it')
- return 666 #要想这个地方的return的值能有每个函数上面所有的search前面都要加return因为,这是一个递归函数,
- else:
- if data[0] == num:
- print('find it')
- return 777
- else:
- print('not found')
- return 888
- search(19,data)
- print(search(19,data))
- 函数对象
- def foo():#foo代表函数的内存地址
- print('foo')
- print(foo)#打印出的是foo函数的内存地址,内存地址加括号就可以调用该函数
-
- #函数可以被赋值
- f=foo
- print(f)#打印的是foo函数的内存地址
- f()#等于foo()
-
- #把函数当成参数传递
- def bar(func):
- print(func)
- func()
- bar(foo)#传入的是foo函数的内存地址,运行结果是打印foo函数的内存地址和foo函数的运行结果
-
- #把函数当成返回值
- def bar(func):
- print(func)
- return func
- f=bar(foo)
- print(f)
- f()
posted @
2017-08-05 18:59
golangav
阅读(
276)
评论()
编辑
收藏
举报

