函数 装饰器 内置函数
一.命名空间和作用域

二.装饰器
1.无参数
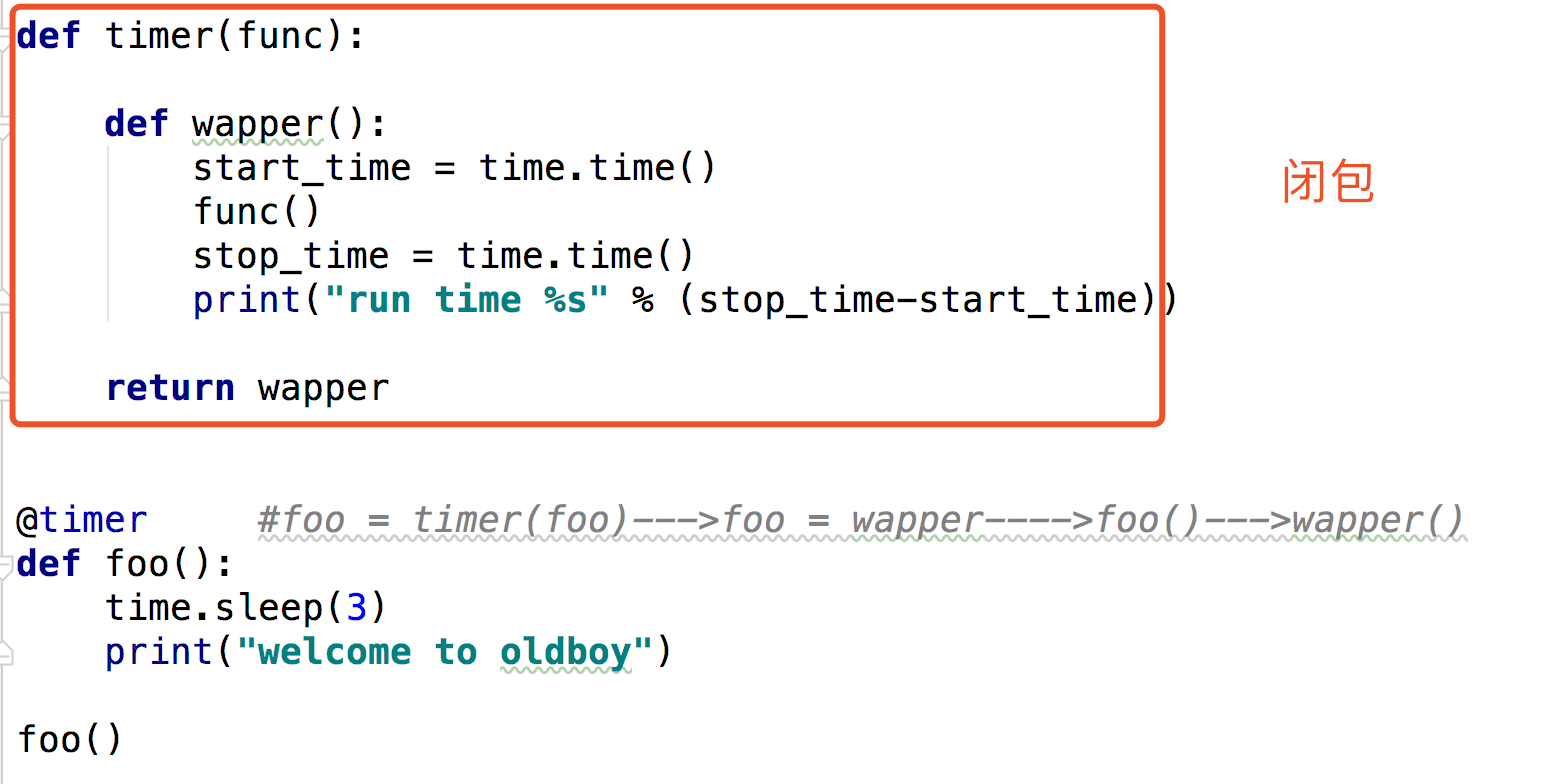
2.函数有参数
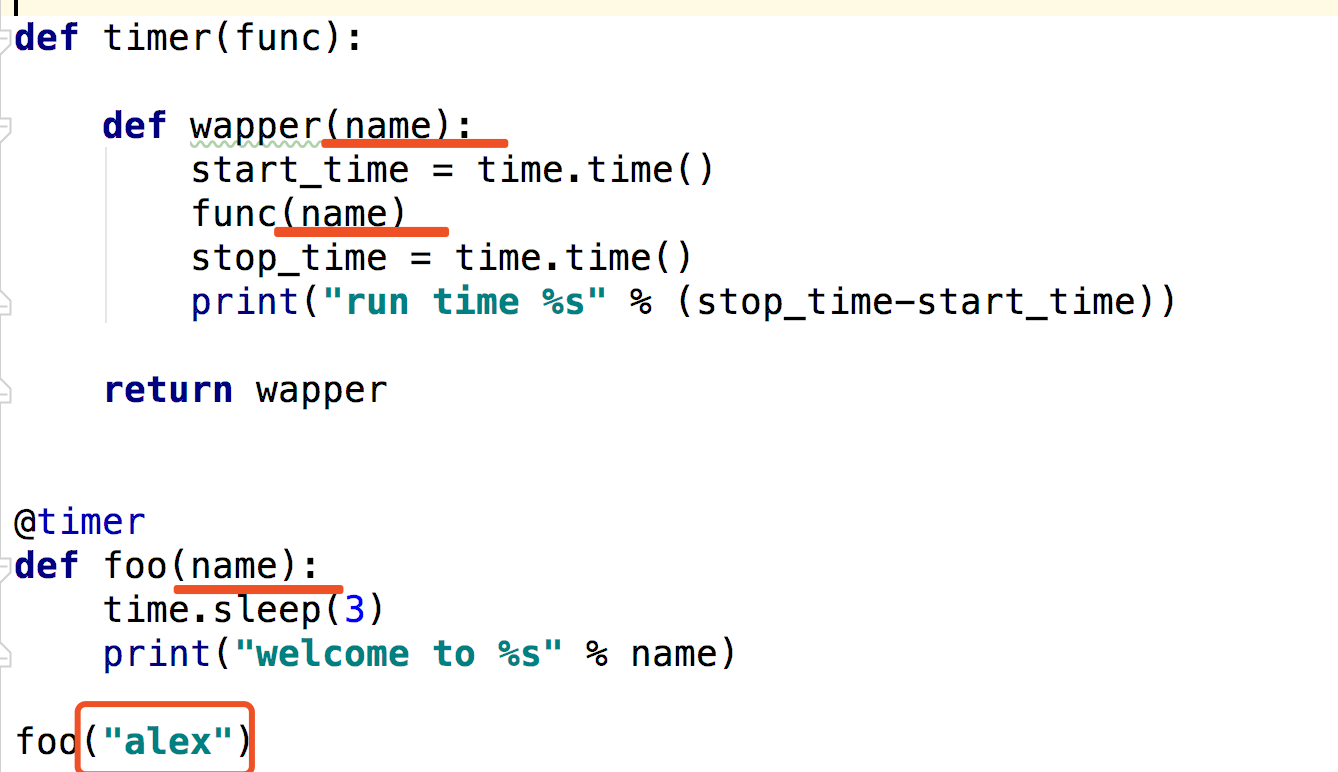
3.函数动态参数
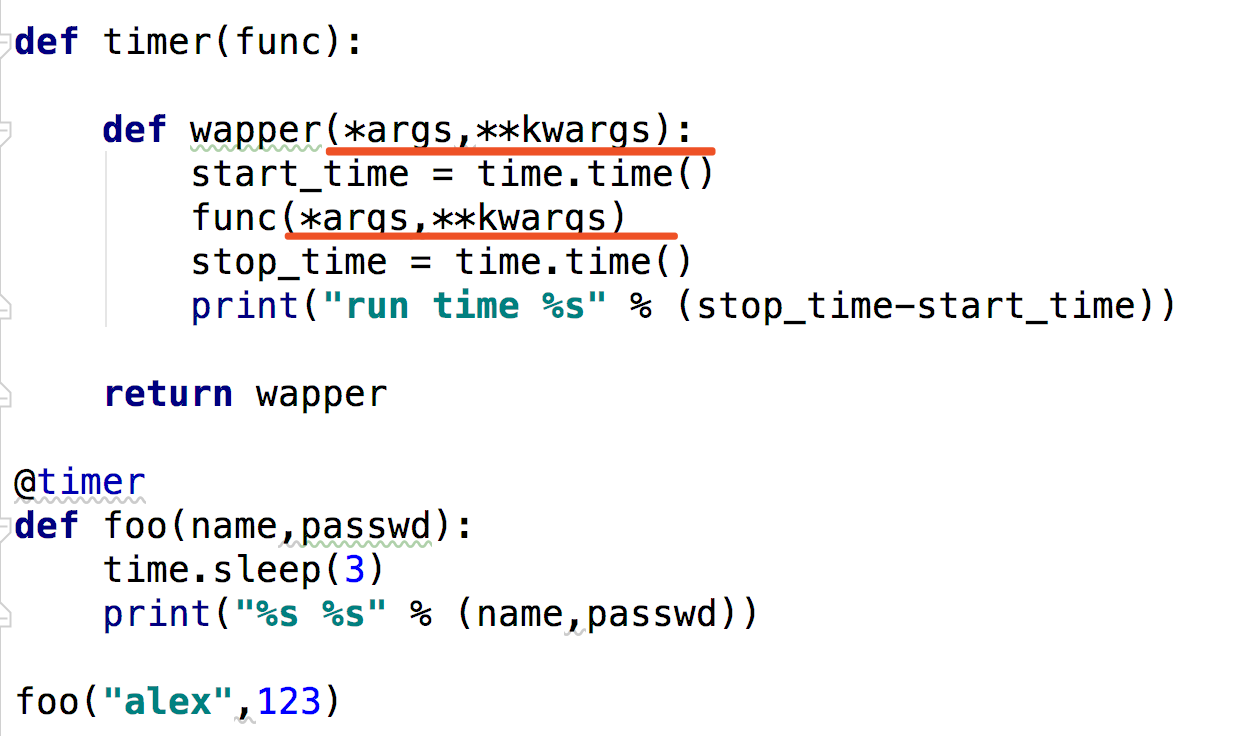
4.装饰器参数
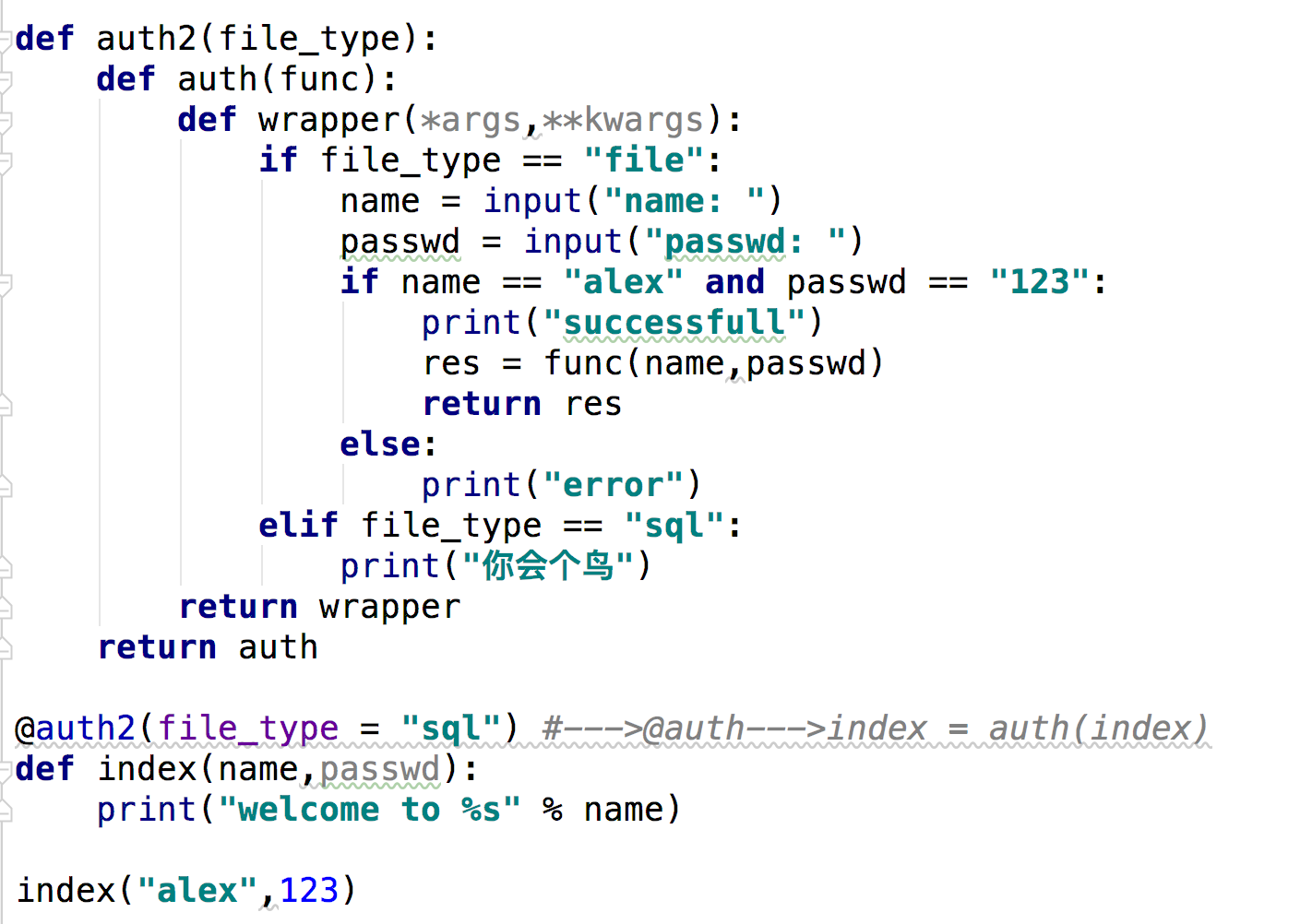
三.内置函数


salaries={ 'egon':3000, 'alex':100000000, 'wupeiqi':10000, 'yuanhao':250 } print(sorted(salaries)) #默认是按照字典salaries的key去排序的 print(sorted(salaries,key=lambda x:salaries[x]))
#max salaries={ 'egon':3000, 'alex':100000000, 'wupeiqi':10000, 'yuanhao':250 } print(max(salaries,key=lambda k:salaries[k])) ------------输出结果------- alex
#enumerate for i in enumerate(['a','b','c','d']): print(i) ------------输出结果------- (0, 'a') (1, 'b') (2, 'c') (3, 'd')
#用filter来处理,得到股票价格大于20的股票名字 shares={ 'IBM':36.6, 'Lenovo':23.2, 'oldboy':21.2, 'ocean':10.2, } shares = list(filter(lambda x:shares[x] >20,shares)) #filter #如下,每个小字典的name对应股票名字,shares对应多少股,price对应股票的价格 portfolio = [ {'name': 'IBM', 'shares': 100, 'price': 91.1}, {'name': 'AAPL', 'shares': 50, 'price': 543.22}, {'name': 'FB', 'shares': 200, 'price': 21.09}, {'name': 'HPQ', 'shares': 35, 'price': 31.75}, {'name': 'YHOO', 'shares': 45, 'price': 16.35}, {'name': 'ACME', 'shares': 75, 'price': 115.65} ] #用filter过滤出,单价大于100的股票有哪些 name = list(filter(lambda x:x["price"] > 100,portfolio)) print(name)
s=[1,"h",2,"e",[1,2,3],"l",(4,5),"l",{1:"111"},"o"] from functools import reduce print(reduce(lambda x,y:x+y,[s[i] for i in range(len(s)) if i % 2 == 1])) ------------------输出结果---- hello
#map #用map来处理字符串列表啊,把列表中所有人都变成sb,比方alex_sb name=['alex','wupeiqi','yuanhao'] name_new = list(map(lambda i: i + '_sb', name)) #用map来处理下述l,然后用list得到一个新的列表,列表中每个人的名字都是sb结尾 l=[{'name':'alex'},{'name':'y'}] l = list(map(lambda x:x["name"] + "sb",l)) #生成列表套字典 type_choices = [ (1, "Python"), (2, "Django"), (3, "Flask"), (100, "Python全栈"), (101, "Linux云计算"), (1000, "在线直播"), (10000, "免费视频"), ] map(lambda item: {'nid': item[0], 'title': item[1]}, models.Article.type_choices) [{'nid': 1, 'title': 'Python'}, {'nid': 2, 'title': 'Django'}]
l1=[1,2,3,4] s='hel' obj = list(zip(l1,s)) ------------输出结果------- [(1, 'h'), (2, 'e'), (3, 'l')] salaries={ 'egon':3000, 'alex':100000000, 'wupeiqi':10000, 'yuanhao':250 } z=list(zip(salaries.values(),salaries.keys())) ------------输出结果------- [(3000, 'egon'), (100000000, 'alex'), (250, 'yuanhao'), (10000, 'wupeiqi')] xx = ['id', 'name', 'age', 'phone', 'job'] title = ['1', 'alex', '22', '13651043850', 'IT'] print(list(zip(xx,title))) print(dict(zip(xx,title))) 按字典的格式输出 ------------输出结果------- [('id', '1'), ('name', 'alex'), ('age', '22'), ('phone', '13651043850'), ('job', 'IT')] {'id': '1', 'name': 'alex', 'age': '22', 'phone': '13651043850', 'job': 'IT'}
