

乱码,编码
写着写着,发现不容易讲解,就当做记录吧。
编码是什么? 为什么我看到的是乱码?
下面我来讲讲我理解的编码:
我要把这段笔记:“我要把这段笔记保存电脑中,等以后用到的时候可以再看”使用vim编辑器保存电脑中,等以后用到的时候可以再看。为什么以后能再看了?

呵呵,这里大家都会说当然能看到啊,对。 但是为什么有些时候显示是乱码了?
首先,我们上电脑上文件的都是以01的方式放在电脑中,那为什么cat a时会打印出我们想要的内容了?
这时我们要知道为什么要acsii码,utf-8编码,gbk编码,unicode编码等?
关于为什么要这些编码,我这里不做讲解,请阅读
通过阅读上面链接的文章,我们知道了中文的utf8编码是3字节,中文的gbk编码是2字节,英文的acsii/utf8/gbk编码都是1字节。
我先说明下:
“我的”utf-8编码为:\xe6\x88\x91 ,gbk编码为:\xce\xd2。
我们用crt 打开一个远程终端,用vim编辑的文字,或在命令行输入的文字,是以什么样的方式发送到服务器的了?
当然是抓包咯,我在shell输入“我”:

抓包到的是:
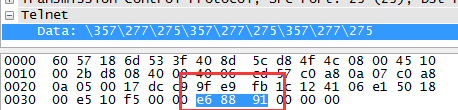 可以看到,这里是utf-8编码后发送到服务器端的,这是为什么了?为什么不是gbk编码后发送过去了?
可以看到,这里是utf-8编码后发送到服务器端的,这是为什么了?为什么不是gbk编码后发送过去了?
这是我们在crt上配置的 ,crt以对收到的网络数据或系统输入数据都有 utf8来编码和解码。这配置gbk那就以gbk来编码解码。
,crt以对收到的网络数据或系统输入数据都有 utf8来编码和解码。这配置gbk那就以gbk来编码解码。



这里我们在文件b中输入“我”显示4个字节,“我们在”,ll显示10个字节,这就说明存储的中文是utf8编码存储的。
为什么是utf8存储了? 我觉得就是因为我们发送过去的就是utf8编码的咯(crt配置的utf8)。
那为什么cat b时,会正确的显示正文了?
我认为cat b时不会管你是什么编码,直接用二进制的方式读取,然后发送到crt显示,当然就能正确显示。
所有我认为,要让我们编辑的文件不是乱码,那就是crt设置utf8写的文件,cat时crt也要设置为utf8,crt设置为gbk时写的文件,cat时crt也要是gbk。这里貌似跟系统环境变量(echo $LANG)没啥关系?
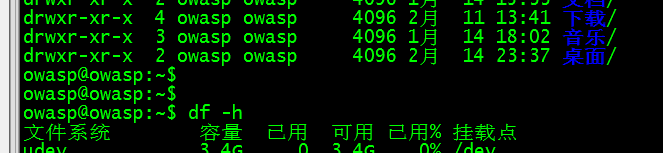
环境变量在df -h呀,ll时是有用的。
LANG=zh_CN.GB18030 ,LANG=zh_CN.UTF-8,LANG=en_US.UTF-8,LANG=en_US.GB18030,
点"."前面的应该是在dh -h第一行,或系统报错时的错误提示有用,zh_CN的话就显示中文,en_US的话显示英文,有待考证
1 [centos@liujin-1 ~]$ echo $LANG 2 en_US.UTF-8 3 [centos@liujin-1 ~]$ df -h 4 Filesystem Size Used Avail Use% Mounted on 5 /dev/vda2 50G 37G 11G 79% / 6 tmpfs 3.9G 12K 3.9G 1% /dev/shm 7 /dev/vda1 190M 44M 136M 25% /boot 8 /dev/vda4 12G 685M 11G 7% /data01 9 cm_processes 3.9G 20M 3.9G 1% /var/run/cloudera-scm-agent/process 10 [centos@liujin-1 ~]$ hahah 11 -bash: hahah: command not found 12 [centos@liujin-1 ~]$ ls aaasfa 13 ls: cannot access aaasfa: No such file or directory 14 [centos@liujin-1 ~]$
我们不能说.后面的UTF-8时不支持中文,这是错的,UTF-8当然支持中文,UTF-8和GBK都是存储字符的一种方式。
我们还经常用到的oracle,oracle怎么设置环境变量了?
NLS_LANG=AMERICAN_AMERICA.AL32UTF8, NLS_LANG=AMERICAN_AMERICA.ZHS16GBK ,d点“.”前面应该是sql中出现错误时应该提示中文错误还是英文错误,点后面的是告诉数据库客户端发过来的字符集时utf8还是gbk的,或者是数据库要发给客户端的话,要发送utf8格式的还是gbk格式的。
比如我数据库里的数据是utf8存放的,NLS_LANG设置的是gbk,那客户端找数据库查询数据时,会把存储的utf8的编码转换为gbk再传给客户端,比如数据库存储“我”存储在数据库的磁盘上是“\xe6\x88\x91”,那发给客户端时会把“我”的编码转为“\xce\xd2”。,然后再发送给客户端。
1、如果我的sql文件是utf8保存的insert.sql,我想在服务器上sql>@insert.sql时设置环境变量export NLS_LANG=AMERICAN_AMERICA.AL32UTF8,sql打开这个insert.sql文件还是二进制的方式打开,然后NLS_LANG变量就会告诉sql传输的编码是utf8。如果是gbk保存,设置export NLS_LANG=AMERICAN_AMERICA.ZHS16GBK,跟数据库存储的编码没关系(select userenv('language') from dual;)
2、如果我想select * from tables;时,crt编码和NSL_LANG编码保持一致。数据库读取数据后,会把数据转换为NLS_LANG的编码,所有crt就会收到NLS_LANG的编码,所以crt得编码就要跟NLS_LANG一样。
有一种情况,crt设置的gbk,NLS_LANG设置的utf8,数据库存储设置的utf8,这是我要插入一个"我”到数据库,
crt是bgk,所有发送到sql的是\xce\xd2,数据库收到的就是\xce\xd2。
NLS_LANG和数据库存储用的都是utf8,所以数据库不会进行转码操作,直接把\xce\xd2存储在数据库的磁盘上。
当你读这个“我”的时候,NLS_LANG和数据库存储字符集都是utf8,数据库就会直接把\xce\xd2发送给客户端,客户端收到后,再crt上显示,crt有事gbk的编码,所以就显示了“我”字。
但是,上面说了crt的字符集要跟NLS_LANG一样啊,对的,那上面那种情况怎么能正确的显示“我”了? 因为了插入的时候,crt字符集就设置错了!!!
建议:
在手动insert插入或select读取时,crt,NLS_LANG,和数据库存储字符集设置的一样,但是crt和NLS_LANG尽量保持一致!!!
@insert.sql插入数据时,NLS_LANG和insert.sql的字符集要一致。
oracle编码可以看视频:字符集概述,字符集正确设置及相关操作
我们的python2和python3了?
执行python2 a.py,python2怎么知道a.py的编码方式了?

我认为python默认会议ascii的方式打开a.py文件,而我的a文件是以utf8的编码存储的,并且里面有中文,所有上图报错,还说没有指定编码方式。
所有我们在写python2的时候会在文件开头写上#! -*- coding:utf8 -*-
 ,这样python解释器就会以utf8的方式对读取的文件进行解码。
,这样python解释器就会以utf8的方式对读取的文件进行解码。

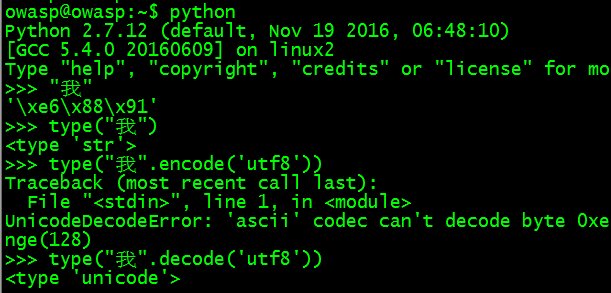
可以看到python2中,“我”是字符串类型,以utf-8或gbk的方式保存在内存中,(utf8还是gbk通过coding:utf8/coding:gbk,或系统环境变量LANG的方式确定),python内存中的编码跟踪环境变量走。
python3默认以utf8的格式解读a.py(用utf8编码存储的)

python3中,"我”是str类型,unicode编码放在内存中的,可以进行编码操作。
如果文件是gbk编码,那python3解释器默认用utf8去解读 文件时会报错

