
(原創) 如何設計乘加電路? (SOC) (Verilog) (MegaCore)
Abstract
z = a*b + c*d;一個很簡單的運算,該如何使用數位電路實現呢?
Introduction
使用環境:Quartus II 8.0
在(原創) 如何設計2數相加的電路? (SOC) (Verilog)中,我們討論過如何實現y = a + b;但在實務上,其實最常用的是y = a*b + c*d,由於Verilog與數位電路本身的限制,不適合真的去實現很複雜的數學,就算真的實現出來,電路也跑不快,又佔resource,所以我們常會重新修改演算法配合數位電路的特性,通常演算法修改到最後,都會只剩下簡單的乘法與加法運算,也就是y = a*b + c*d的型式。
Method 1:
一般寫法
ALT_MULTADD.v / Verilog
2 (C) OOMusou 2008 http://oomusou.cnblogs.com
3
4 Filename : ALT_MULTADD.v
5 Compiler : Quartus II 8.0
6 Description : Demo how to write y = a*b + c*d
7 Release : 10/11/2008 1.0
8 */
9
10 module ALT_MULTADD (
11 input iCLK,
12 input iRST_N,
13 input [7:0] iA0,
14 input [7:0] iB0,
15 input [7:0] iA1,
16 input [7:0] iB1,
17 output [16:0] oRESULT
18 );
19
20 reg [7:0] a0;
21 reg [7:0] a1;
22 reg [7:0] b0;
23 reg [7:0] b1;
24 reg [16:0] result;
25
26 assign oRESULT = result;
27
28 always@(posedge iCLK, negedge iRST_N) begin
29 if (!iRST_N) begin
30 a0 <= 0;
31 a1 <= 0;
32 b0 <= 0;
33 b1 <= 0;
34 result <= 0;
35 end
36 else begin
37 a0 <= iA0;
38 a1 <= iA1;
39 b0 <= iB0;
40 b1 <= iB1;
41
42 result <= a0 * b0 + a1 * b1;
43 end
44 end
45
46 endmodule
模擬結果
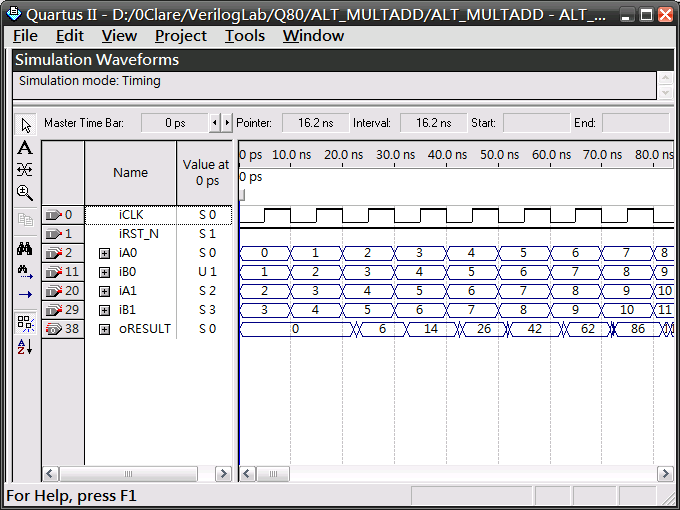
輸出結果會delay 2個clock,為什麼會這樣呢?這可由合成結果來解釋。
合成結果
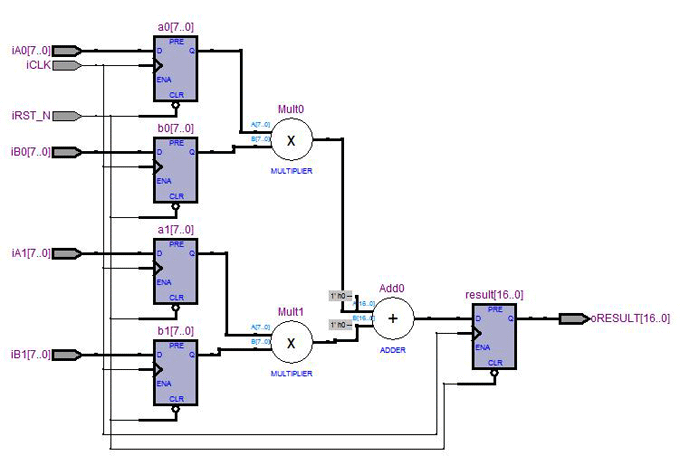
輸出輸入都使用reg寄存,所以一共delay 2個clock,中間是組合電路負責乘加運算。
Fmax為195.43MHz
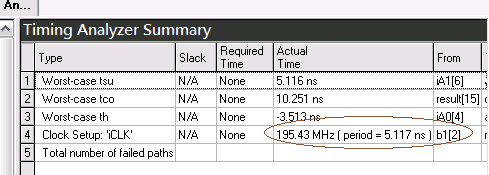
Method 2:
使用Pipeline
ALT_MULTADD_pipe.v / Verilog
2 (C) OOMusou 2008 http://oomusou.cnblogs.com
3
4 Filename : ALT_MULTADD_pipe.v
5 Compiler : Quartus II 8.0
6 Description : Demo how to write y = a*b + c*d with pipeline
7 Release : 10/11/2008 1.0
8 */
9
10 module ALT_MULTADD_pipe (
11 input iCLK,
12 input iRST_N,
13 input [7:0] iA0,
14 input [7:0] iB0,
15 input [7:0] iA1,
16 input [7:0] iB1,
17 output [16:0] oRESULT
18 );
19
20 reg [7:0] a0;
21 reg [7:0] a1;
22 reg [7:0] b0;
23 reg [7:0] b1;
24
25 reg [16:0] m0;
26 reg [16:0] m1;
27
28 reg [16:0] result;
29
30 assign oRESULT = result;
31
32 always@(posedge iCLK, negedge iRST_N) begin
33 if (!iRST_N) begin
34 a0 <= 0;
35 a1 <= 0;
36 b0 <= 0;
37 b1 <= 0;
38 m0 <= 0;
39 m1 <= 0;
40 end
41 else begin
42 a0 <= iA0;
43 a1 <= iA1;
44 b0 <= iB0;
45 b1 <= iB1;
46
47 m0 <= a0 * b0;
48 m1 <= a1 * b1;
49
50 result <= m0 + m1;
51 end
52 end
53
54 endmodule
模擬結果
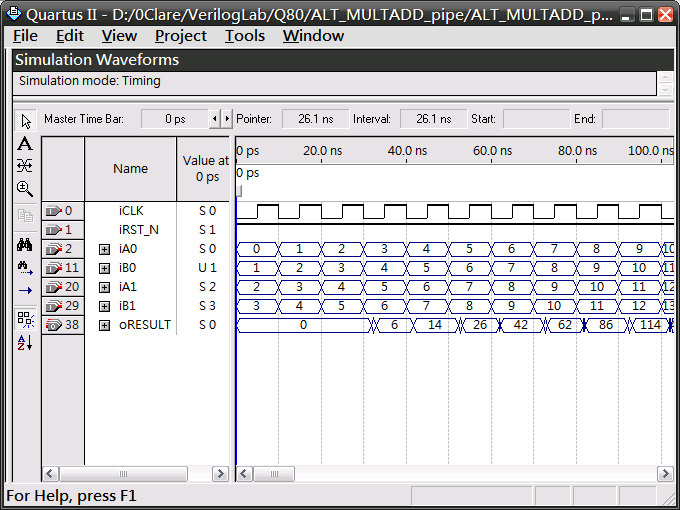
輸出結果會delay 3個clock,為什麼會這樣呢?這可由合成結果來解釋。
合成結果
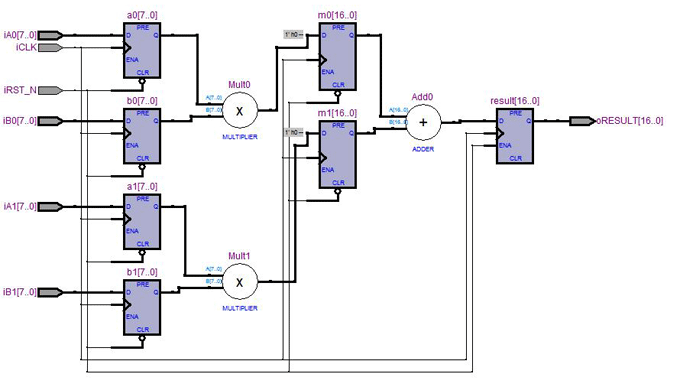
由於使用了3級reg,所以delay了3個clock。
其實在code中,也已經描述了這個現象,42行
a1 <= iA1;
b0 <= iB0;
b1 <= iB1;
第1個clock,將input做寄存。
47行
m1 <= a1 * b1;
第2個clock,計算a0 * b0與a1 * b1,由於這兩個毫不相干,所以可以同時計算。
50行
第3個clock,將output做寄存。
所以在寫code時,其實腦筋想的正是RTL Viewer合成出來的結果, 這也是為什麼寫Verilog時,不能像寫C一樣,只要語法對就好,剩下就是Compiler幫你優化,由於目前C compiler優化能力都很強,所以就算你亂寫,優化出來的結果也差不多,但寫Verilog卻要時時想著你想描述的硬體,
Fmax為260MHz

加上pipeline後,Fmax大增,為什麼加上pipeline後,Fmax增加這麼多呢?尤其若你原本是寫C的背景,看到Verilog多了幾個reg後,差異就這麼大,一定很難理解。
解釋pipeline的書很多,在有名的算盤書(Computer Organization & Design The Hardware / Software Interface) Ch.6講得很清楚,在這我用另外一種方法來解釋。
在同步設計中,電路的設計都是循序電路、組合電路交錯的組合,由上面兩個合成結果也能發現這種設計,為了要同步,所以必須很穩定的前一個clock在第1級reg,而下一個clock在第2級reg,因為Fmax是period的倒數,兩級reg中間的組合電路所需時間越長,period一定越大,倒數後的Fmax就越小。
在Method 1中
要乘要加,這樣的組合電路一定要花較長的時間,所以period也越大,Fmax當然也變小。
在Method 2中
m1 <= a1 * b1;
result <= m0 + m1;
將相乘跟相加分開來做,先將乘法運算的結果做寄存,然後再作加法運算,這樣每個組合電路的時間變少,所以period也變小,Fmax當然也變大了。
但pipeline也是有trade off!!
多花了一級reg,所以delay時間會變長,也就是一開始會慢一個clock出來,但之後每個clock都有產出,換來的就是Fmax變大。
所以有人說,硬體加速基本上就是將演算法切得很細來加速,就是因為pipeline的關係。
看到這裡,你或許會說:
『y = a*b + c*d在C只要一行的東西,在Verilog我要寫這麼多行?那真的去寫一個演算法還得了?』
幸好Altera提供了Megafunction,讓我們可以很輕鬆的計算y = a*b + c*d。
Method 3:
使用Megafunction:ALT_MULTADD
ALT_MULTADD_mf.v / Verilog
2 (C) OOMusou 2008 http://oomusou.cnblogs.com
3
4 Filename : ALT_MULTADD_mf.v
5 Compiler : Quartus II 8.0
6 Description : Demo how to write y = a*b + c*d by Megafunction
7 Release : 10/11/2008 1.0
8 */
9
10 module ALT_MULTADD_mf (
11 input iCLK,
12 input iRST_N,
13 input [7:0] iA0,
14 input [7:0] iB0,
15 input [7:0] iA1,
16 input [7:0] iB1,
17 output [16:0] oRESULT
18 );
19
20 MAC mac0 (
21 .aclr0(!iRST_N),
22 .clock0(iCLK),
23 .dataa_0(iA0),
24 .datab_0(iB0),
25 .dataa_1(iA1),
26 .datab_1(iB1),
27 .result(oRESULT)
28 );
29
30 endmodule
這樣的code夠精簡了吧!!
模擬結果
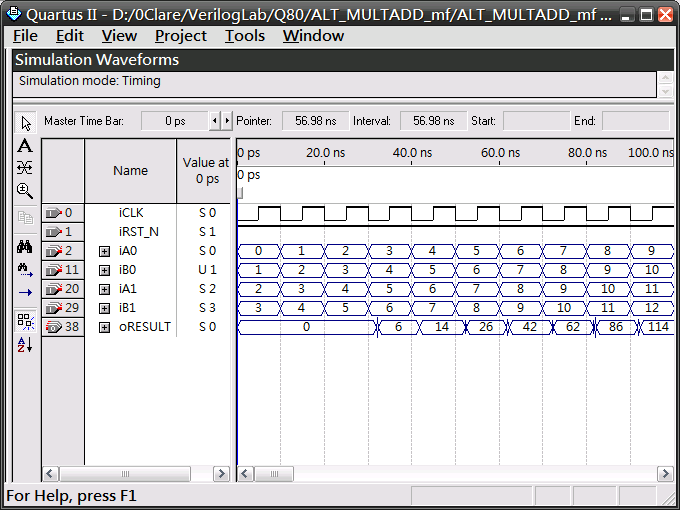
與Method 2的結果一樣delay 3個clock,可見Megafunction:ALT_MULTADD預設已經加上了pipeline。
合成結果
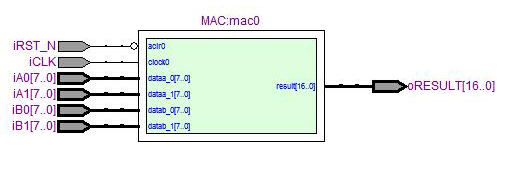
很單純的只有一個MAC block。
Fmax一樣為260MHz
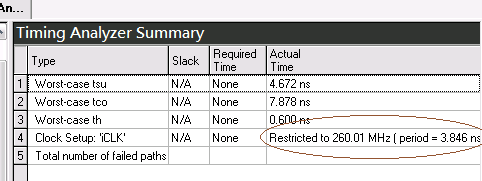
所以不用擔心Megafunction:ALT_MULTADD沒自己寫code效率好。
如何使用Megafunction:ALT_MULTADD?
Tool -> MegaWizard Plug-In Manager
之後就是wizard介面,跟著一步一步設定即可。Megafunction:ALT_MULTADD預設已經將input與output用reg做寄存,所以我們只需單純的用wire連進去即可。
完整程式下載
ALT_MULTADD.7z (一般寫法)
ALT_MULTADD_pipe.7z (使用pipeline)
ALT_MULTADD_mf.7z (使用Megafunction:ALT_MULTADD)
Conclusion
本文所要傳達的重點有4:
1.寫Verilog不能像寫C一樣,只要語法對就好,剩下的優化就交給C compiler;寫Verilog時要時時想著你要描述的硬體,因為合成器會依照你的code去做合成,寫法的差異影響結果甚鉅。
2.解釋pipeline概念,這是c coder學Verilog很難理解的地方。
3.Altera提供了不少好用Megafunction,不僅方便,而且執行效率甚至比我們自己寫的還好些,應該盡量使用Megafunction增加開發效率以及執行效率。
4.Megafunction:ALT_MULTADD在實務上經常使用,在(原創) 如何實現Real Time的Sobel Edge Detector? (SOC) (Verilog) (Image Processing) (DE2-70) (TRDB-D5M) (TRDB-LTM),我就曾經使用ALT_MULTADD這個Megafunction實現Sobel Edge Detector演算法。
See Also
(原創) 如何設計2數相加的電路? (SOC) (Verilog)
(原創) 如何實現Real Time的Sobel Edge Detector? (SOC) (Verilog) (Image Processing) (DE2-70) (TRDB-D5M) (TRDB-LTM)
(原創) 如何實現Real Time的Sobel Edge Detector? (SOC) (Verilog) (Image Processing) (DE2) (TRDB-DC2)
(原創) 如何處理signed integer的加法運算與overflow? (SOC) (Verilog)
(原創) 無號數及有號數的乘加運算電路設計 (IC Design) (Verilog) (OS) (Linux)
(原創) 如何用管線(Pipeline)實作無號數乘加運算? (IC Design) (Verilog)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号