
软工第二次作业

解题思路
刚拿到题目,我先看了几遍,大致的了解题目的含义。因为有些工具不会使用,如vs2017,我就先去学习工具的使用了。从工具的配置以及大致的使用过程,我都通过上网查资料以及询问同学。查资料以及学习资料的过程花费了我不少的时间,但有很大的收获,起码我些许懂得如何使用当下最时髦的编译软件。至于编码,因为我的代码能力较弱,我一开始没有自己动手打,而是去网上找了一个和题目有相似性的c代码,自己再将c改成了c++,还补充了一些功能上去,虽然还是有bug,但是编译过了,我也有些许安慰。
设计实现过程
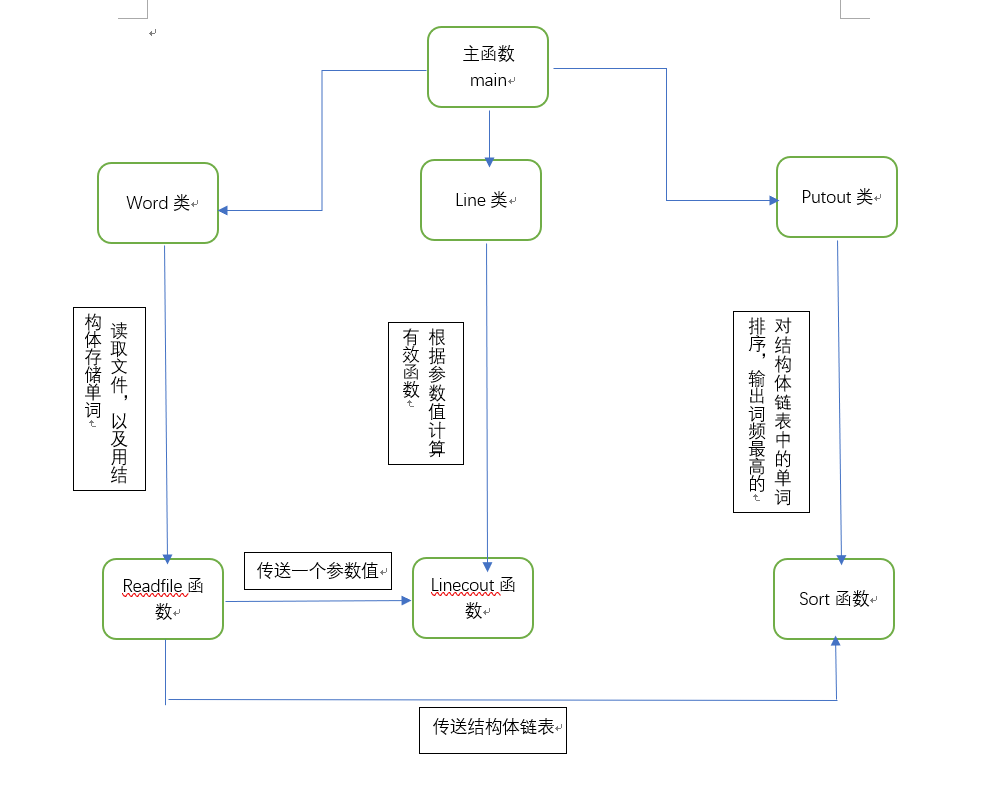
以下是我的流程图
单元测试功能因为代码有bug,然后没有通过,不过知道怎么设置附加依赖项。
性能分析
由于自己水准不够,代码没有实现全部的功能,所以我就只是尝试了一下什么是性能分析功能,不过我会利用课余时间,拿一段简单易实现的代码,去测试一下分析功能。
代码说明
void readfile(struct word * &head)
{
FILE *fp;
linecount l;
if ((fp = fopen("in.txt" ,"r") )== NULL)
{
printf("无法打开此文件!\n");
exit(0);
}
while (!feof(fp))
{
int i = 0;
ch = fgetc(fp);
if (ch != 32 && ch != 10 && ch != 9) flag1 = 1;
temp[0] = ' '; //保证单词的开始一定是有效字符
do
{
charnum++; //统计字符数
if (ch >= 'a'&&ch <= 'z' || ch >= 'A'&&ch <= 'Z' || ch >= '0'&&ch <= '9')
{
if (ch >= 'A'&&ch <= 'Z') //大写化小写
{
temp[i] = ch - 32;
i++;
}
else
{
temp[i] = ch;
i++;
}
if (i <= 3 && ch >= '0'&&ch <= '9') flag = 0; //如果字符序列前四个有数字则不算单词
}
ch = fgetc(fp);
if (ch != 32 && ch != 10 && ch != 9) flag1 = 1;
if (ch = 10)
{
l.line(flag1);
flag1 = 0;
}
if (feof(fp))
{
charnum--; //多加了一个EOF
break;
}
} while (ch >= 'a'&&ch <= 'z' || ch >= 'A'&&ch <= 'Z' || ch >= '0'&&ch <= '9' || temp[0] == ' ');
charnum++;
temp[i] = '\0';
p = head->next;
while (p)
//旧单词,词频加1
{
if (!strcmp(temp, p->name))
{
p->num++;
wordnum++;
break;
}
p = p->next;
}
if (!p&&temp[0] != '\0'&&flag == 1)
//新单词存入链表
{
p = new word;
strcpy_s(p->name, temp);
p->num = 1;
wordnum++;
p->next = head->next;
head->next = p;
}
flag = 1;
}
}
};
以上就是我的核心代码。我的思路是通过逐个字符的读取文本文件,将相似于单词的字符串存入一个字符数组,然后在通过一个判断,判断这个字符串是不是单词,是就存储进结构体链表中。
心得体会
这次的实践,由于c++使用的较少,然后也是初次使用vs2017,我的代码实现挺糟糕的,只完成字符的统计功能。如果是用c写的话到可以完成全部的功能,由于时间问题我是不能在deadline之前实现全部功能,之后自己会找时间改进自己的代码,让自己能收获到更多,总之让我自己意识到自己的代码水平有很大的进步空间。然后就是上网学习资料,我觉得这获得知识都是比较实用,多看看别人的博客对自己也是有很大的提升。还有就是以前从来没有很系统的为一道题目做很系统的安排计划,这次实践让我感觉到有一个系统的过程会省事h很多。


