
数据结构和算法之哈希表(散列)的介绍和内存布局
散列表的基本介绍
散列表(Hash table,也叫哈希表),是根据关键码值(key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存
放记录的数据叫做散列表。
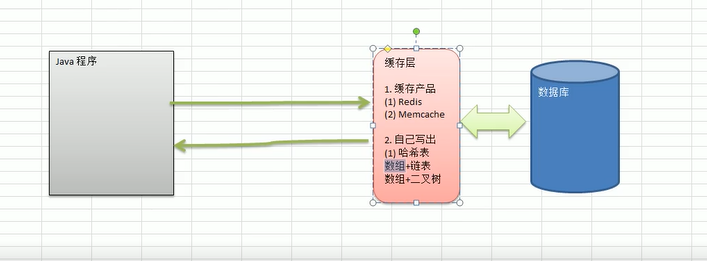
在写了一段java程序,java程序要去操作数据库,然后数据库经过一番操作将结果返回给java程序,java程序拿到结果进行显示,数据一般是放在数据库的,但是这种结构有一个问题,它会对我们的数据库的操
作可能非常频繁,有些数据没必要每次都去查数据库,在某些情况下不需要,那在这种情况下我们会加一个缓存层。一般来讲,我们提高我们的检索速度,一般就是把我们常用的数据加载到缓存层,我们能够
在缓存层取数据就不到数据库取数据,那么缓存层我们一般使用相关的缓存产品。
缓存产品:Redis Memcache
那我们除了缓存产品以外,也可以自己写一个缓存层,这个时候就要借助于数据结构哈希表来做。哈希表从某个角度来说,它就是可以先把数据先加载到内存,加载到内存,把它放入到哈希表中,这样再取数
据的时候就无须在到数据库取,什么时候才到数据库取呢,如果在某些情况下使用缓存产品太重量级了就可以自己写个哈希表,这个时候我们可以事先把数据先放到哈希表中,然后我们取数据的时候先到哈希
表中取,这样就可以提高我们的效率。
那么哈希表的结构有哪些呢?
比如说我们常用的有:
- 数组+链表
- 数组+二叉树(如果我们用的是二叉排序树,性能就能有所提升)
不管是数组配合链表还是数组配合二叉树,其主要目的都是去提升我们数据的查找速度,为什么这么做呢?因为如果我们每次都是直接查数据库,速度太慢了,而且对数据库压力太大,所以我们先把数据放入
哈希表,我程序先到哈希表去取,取不到再到数据库去取,然后把经常用的在加载到哈希表里面就可以了,这样就提升了我们的速度。那如果一级缓存不够,我们可以再加一个缓存层,这样就形成二级缓存
了,二级缓存可以通过再哈希得到。这就是哈希表的由来。
那么哈希表在内存布局中的结构是怎么样的呢?下面这张图清晰的反映了它的结构:
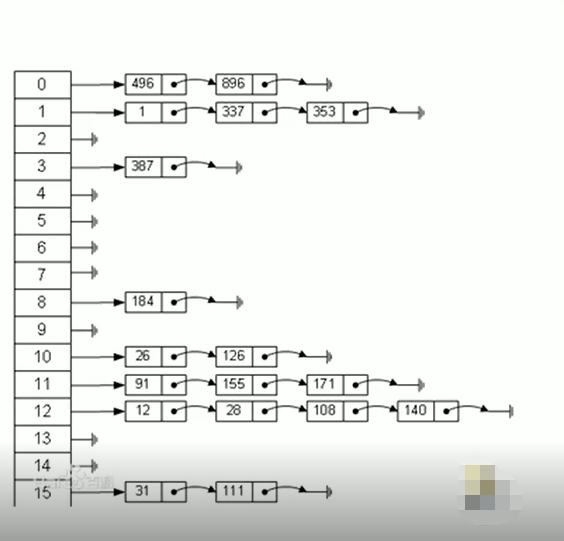
从上图可以看出,这是一张表,也可以看成是一个数组,那这个数组它放的不再是普通数据,而是一个链表,也就是说这个数组变成了链表数组,当我们去查找一个id的时候,我们可以先用散列函数来得到我
们这个信息会在这个表里面的哪一条链表,这样就直接在这条链表里面去查,从而提高速度。打个比方,比如现在有15条链表,我们来一个值 111 % 15 ,我们就知道111 id号在哪条链表,我们直接到这条链表
去取,相当于说速度就提升了15倍。这样比我们单独使用链表要快,那整个数组+链表就形成了一个所谓的散列表,也叫哈希表,这就是哈希表一个最基本的工作原理,也是它的内存布局图。
实际需求:google公司的一个上机题
有一个公司,当有新的员工来报到时,要求将该员工的信息加入(id,性别,年龄,名字,住址...)当输入该员工的id时,要求查找到该员工的所有信息
要求:不使用数据库,尽量节省内存,速度越快越好=>哈希表(散列)
添加时,保证按照id从低到高插入(思考:如果id不是从低到高插入,但要求各条链表仍是从低到高,怎么解决?)
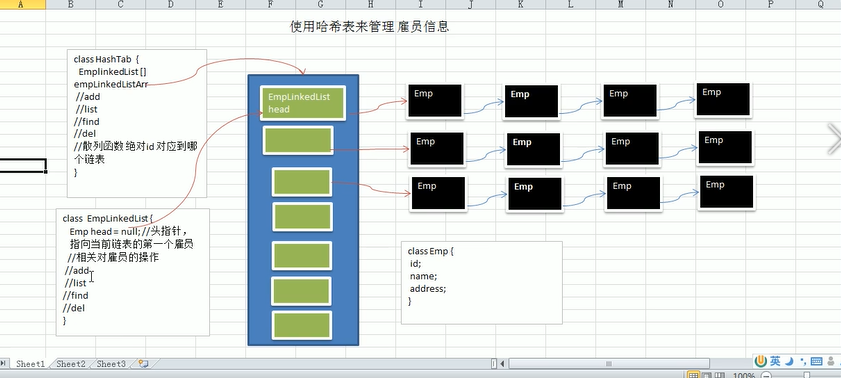
(1) 使用链表来实现哈希表,该链表不带表头[即:链表的第一个节点就存放雇员信息]
(2) 思路分析并画出示意图
(3) 代码实现[增删改查(显示所有员工,按id查询)]
代码实现:
1 import java.util.Scanner; 2 3 public class HashTableDemo { 4 public static void main(String[] args) { 5 6 // 创建哈希表 7 HashTable hashTab = new HashTable(7); 8 9 // 写一个简单的菜单 10 String key = ""; 11 Scanner scanner = new Scanner(System.in); 12 while(true){ 13 System.out.println("add: 添加雇员"); 14 System.out.println("list: 显示雇员"); 15 System.out.println("find: 查找雇员"); 16 System.out.println("exit: 退出系统"); 17 18 key = scanner.next(); 19 switch (key){ 20 case "add": 21 System.out.println("输入id"); 22 int id = scanner.nextInt(); 23 System.out.println("输入名字"); 24 String name = scanner.next(); 25 // 创建雇员 26 Emp emp = new Emp(id, name); 27 hashTab.add(emp); 28 break; 29 case "list": 30 hashTab.list(); 31 break; 32 case "find": 33 System.out.println("请输入要查找的id"); 34 id = scanner.nextInt(); 35 hashTab.findEmpById(id); 36 break; 37 case "exit": 38 scanner.close(); 39 System.exit(0); 40 default: 41 break; 42 } 43 } 44 } 45 } 46 47 //创建HashTable 管理多条链表 48 class HashTable { 49 private EmpLinkedList[] empLinkedListArray; 50 private int size; // 表示有多少条链表 51 // 构造器 52 public HashTable(int size){ 53 this.size = size; 54 // 初始化EmplinkedListArray 55 empLinkedListArray = new EmpLinkedList[size]; 56 // 这时需要分别初始化每个链表 57 for (int i = 0; i < size; i++){ 58 empLinkedListArray[i] = new EmpLinkedList(); 59 } 60 61 } 62 // 添加雇员 63 public void add(Emp emp){ 64 // 根据员工的id, 得到该员工应当添加哪条链表 65 int empLinkedListNO = hashFun(emp.id); 66 // 将emp添加到对应的链表中 67 empLinkedListArray[empLinkedListNO].add(emp); 68 69 } 70 // 遍历所有的链表,遍历hashTab 71 public void list(){ 72 for (int i = 0; i < size; i++){ 73 empLinkedListArray[i].list(i); 74 } 75 } 76 77 // 根据输入的id,查找雇员 78 public void findEmpById(int id){ 79 // 使用散列函数确定哪条链表查找 80 int empLinkedListNO = hashFun(id); 81 Emp emp = empLinkedListArray[empLinkedListNO].findEmpById(id); 82 if (emp != null){ // 找到 83 System.out.printf("在第%d条链表中找到 雇员id = %d\n", (empLinkedListNO + 1), id); 84 }else{ 85 System.out.println("在哈希表中,没有找到该雇员"); 86 } 87 } 88 // 编写散列函数,使用一个简单取模法 89 public int hashFun(int id){ 90 return id % size; 91 } 92 } 93 94 95 // 表示一个雇员 96 class Emp{ 97 public int id; 98 public String name; 99 public Emp next; //next 默认为 null 100 101 public Emp(int id, String name) { 102 this.id = id; 103 this.name = name; 104 } 105 } 106 107 // 创建EmpLinkedList, 表示链表 108 class EmpLinkedList { 109 // 头指针,执行第一个Emp,因此我们这个链表的head是直接指向第一个Emp 110 private Emp head; // 默认null 111 112 // 添加雇员到链表 113 // 说明 114 // 1、指定,当添加雇员时, id是自增长,即id的分配总是从小到大 115 // 因此我们将该雇员直接加入到本链表的最后即可 116 public void add(Emp emp){ 117 //如果是添加第一个雇员 118 if(head == null){ 119 head = emp; 120 return; 121 } 122 // 如果不是第一个雇员,则使用一个辅助的指针,帮助定位到最后 123 Emp curEmp = head; 124 while(true){ 125 if (curEmp.next == null){ // 说明到链表最后 126 break; 127 } 128 curEmp = curEmp.next; // 后移 129 } 130 // 退出时直接将emp 加入链表 131 curEmp.next = emp; 132 } 133 // 遍历链表的雇员信息 134 public void list(int no){ 135 if (head == null){ // 说明链表为空 136 System.out.println("第 "+(no+1)+" 链表为空"); 137 return; 138 } 139 System.out.println("第 "+(no+1)+" 链表的信息为"); 140 Emp curEmp = head; // 辅助指针 141 while(true){ 142 System.out.printf(" => id=%d name=%s\t", curEmp.id, curEmp.name); 143 if (curEmp.next == null){ // 说明curEmp已经是最后结点 144 break; 145 } 146 curEmp = curEmp.next; // 后移,遍历 147 } 148 System.out.println(); 149 } 150 // 根据id查找雇员 151 // 如果查找到,就返回Emp, 如果没找到,就返回null 152 public Emp findEmpById(int id){ 153 // 判断链表是否为空 154 if (head == null){ 155 System.out.println("链表为空"); 156 return null; 157 } 158 // 辅助指针 159 Emp curEmp = head; 160 while(true){ 161 if (curEmp.id == id){ // 找到 162 break; // 这时curEmp就指向要查找的雇员 163 } 164 // 退出 165 if (curEmp.next == null){ // 说明遍历当前链表没有找到该雇员 166 curEmp = null; 167 break; 168 } 169 curEmp = curEmp.next; // 后移 170 } 171 return curEmp; 172 } 173 }
