

重做日志用来实现事务的持久性,即ACID中的D,由两部分组成:
一是内存中的重做日志缓冲(redo log buffer) 易丢失
二是重做日志文件(redo log file) 持久的
InnoDB是事务的存储引擎,其通过Force Log at Commit 机制实现事务的持久性,即当事务提交commit时,必须先将事务的所有日志写入到重做日志文件进行持久化,待事务COMMIT操作完成才算完成,这里的日志指重做日志,在InnoDB存储引擎中,由两部分组成,即redo log 和undo Log. redo log用来保证事务的持久性,undo log 用来帮主事务回滚及MVCC的功能。redo log 基本是顺序写的,在数据库运行时不需要对redo log的文件进行读取操作。而undo log 是需要进行随机读写的
为了确保每次日志都能写入日志文件,在每次将重做日志缓冲写入重做日志文件后,InnoDB存储引擎都需要调用一次fsync操作,由于重做日志文件打开并没有使用O_DIRECT选项,因此重做日志缓冲先写入文件系统缓存。为了确保重做日志写入磁盘,必须进行fsync操作。由于fsync的效率取决于磁盘的性能,因此磁盘的性能决定了事务提交的性能,也就是数据库的性能
InnoDB存储引擎允许用户手工设置非持久性的情况发生,以此来提高数据库的性能。即当事务提交时,日志不写入重做日志,而是等待一个时间周期后在执行fsync操作。由于并非强制在事务提交时进行一次fsync操作,显然这可以提高数据库的性能,但是当数据库发生宕机时,由于部分日志未书安心到磁盘,因此会丢失最后一段的事务
参数innodb_flush_log_at_trx_commit用来控制重做日志刷新到磁盘的策略,改参数默认为1 ,表示事务提交时必须调用一次fsync操作,还可以设置成0 和2 ,0表示事务提交时不进行写入重做日志操作,这个操作仅在master thread中完成,而master thread中每一秒会进行一次重做日志文件的fsync操作,2 表示事务提交时将重做日志写入重做日志文件,但仅写入文件系统的缓存中,不进行fsync操作。在这个设置下,当MySQL发生宕机而操作系统不发生宕机时,并不会导致事务的丢失,而当操作系统宕机时,重启数据库会丢失未从文件系统缓存刷新到重做日志文件的那部分事务
参考一个列子,比较innodb_flush_log_at_trx_commit对事务的影响。首先根据如下代码创建表t1和存储过程p_load
CREATE TABLE test_load( a INT, b CHAR(80) )ENGINE=INNODB; DELIMITER // CREATE PROCEDURE p_load(COUNT INT UNSIGNED) BEGIN DECLARE s INT UNSIGNED DEFAULT 1; DECLARE c CHAR(80) DEFAULT REPEAT('a',80); WHILE s<= COUNT DO INSERT INTO test_load SELECT NULL,c; COMMIT; SET s = s+1; END WHILE; END; // DELIMITER ;
存储过程p_load的作用是将数据不断的插入表test_load中,并且每插入一条就进行一次显示的COMMIT操作,在默认的设置下,参数innodb_flush_log_at_trx_commit为1的情况下,InnoDB会将重做日志缓冲写入文件,并且调用一次fsync操作,如果执行CALL p_load(500 000),则会向表中插入50W行的记录,执行50W次的fsync操作,先看看默认情况下插入50W条记录需要的时间
CALL p_load(500000);
虚拟机,插入50W条记录,开销18分钟,对于生产环境来说,时间肯定是不能接受的,而造成时间比较馋的原因是在于fsync所需要的时间,那么将参数设置成
SET GLOBAL innodb_flush_log_at_trx_commit=0;
再执行
CALL p_load(500000); 总耗时40秒
可以看到参数innodb_flush_log_at_trx_commit设置为0后,插入50W行的 记录缩短了接近17分钟。造成这么大现象的主要原因是 后者大大减少了fsync的次数,从而挺高了数据库执行的性能,如下表显示了innodb_flush_log_at_trx_commit的不同设置下,调用存储过程p_load插入50W行记录的时间

虽然用户可以设置参数innodb_flush_log_at_trx_commit为0或2来提高事务提交的性能,但是需要牢记,这种设置丧失了事务的ACID特性,而针对上述存储过程,为了提高事务的提交性能,应该在将50W行记录插入表后进行一次的COMMIT操作,而不是没插入一条记录后进行一次COMMIT操作。这样的好处是还可以使事务方法在回滚时会滚到事务最开始的确定状态
在MySQL数据库中还有一种二进制日志其用来进行POINT-IN-TIME(PIT)的恢复及主从复制(Replication)环境的建立,从表面上看和重做日志非常相似,都是记录了对于数据库操作的日志,然而,从本质上来看,两者有非常大的不同
首先,重做日志是InnoDB存储引擎层产生,而二进制日志是在MySQL数据库的上层产生,并且二进制日志不仅仅针对InnoDB存储引擎,MySQL数据库中任何存储引擎对于数据库的编个都会产生二进制日志
其次,两种日志记录的内容形式不一样,MySQL数据库上层的二进制日志是一种逻辑日志,其记录的是对应的SQL语句,而InnoDB存储引擎层面的重做日志是物理格式日志,其记录的是每个页的修改
此外,两种日志记录写入磁盘的时间点不同,如图,二进制日志只在事务提交完成后进行一次写入,而InnoDB存储引擎的重做日志在事务进行中不断地被写入,这表现为日志并不是随事务提交的顺序进行写入的

从图看到,二进制日志近在事务提交时记录,并且对每一个事务,仅包含对应事务的一个日志,而对于InnoDB存储引擎的重做日志,由于其记录的是物理操作日志,因此每个事务对应多个日志条目,并且事务的重做日志是并发的,并非在事务提交时写入,故其在文件中的记录顺序并非是事务的开始顺序。*T1 * T2 *T3表示事务提交时的日志
2 log block
在InnoDB存储引擎中,重做日志都是以512字节进行存储的,这意味着重做日志缓存、重做日志文件块都是以块block的方式进行保存的,称为重做日志块(redo log block)每块的大小512字节
每个页中产生的重做日志数量大于512字节,那么需要分割多个重做日志块进行存储,此外,由于重做日志快的大小和磁盘扇区大小一样,都是512字节,因此重做日志的写入可以保证原子性,不需要double write技术
重做日志快除了日志本身之外,还由日志块头(log block header)及日志块尾(log block tailer)两部分组成。重做日志头一共占用12字节,重做日志尾占用8字节。故每个重做日志块实际可以存储的大小为492字节(512-12-8),如图显示重做日志块缓存的结构
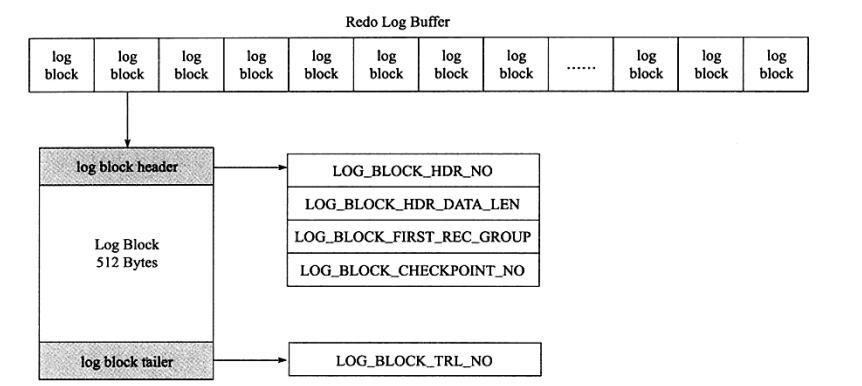
如图显示了重做日志缓存的结果,可以发现,重做日志缓存由每个为512字节大小的日志块锁组成,日志块由三部分组成,依次为日志快头(log block header)、日志内容(log body)、日志块尾(log block tailer)
log block header由4部分组成

log buffer 是由log block组成,在内部log buffer就好似一个数组,因此LOG_BLOCK_HDR_NO用来标记这个数组中的位置,尤其是递增并且循环使用的。占用4个字节。但是由于第一位用来判断是否是flush bit,所以最大值为2G
LOG_BLOCK_HDR_DATA_LEN占用2个字节,表示log block所占用的大小,当log block被写满时,该值为0x200,表示使用全部的log block空间,即占用512字节
LOG_BLOCK_FIRST_REC_GROUP 占用2个字节,表示log block中第一个日志所在的偏移量。如果该值的大小和LOG_BLOCK_HDR_DATA_LEN相同,则表示当前log block不包含新的日志。如事务T1的重做日志1占用762字节,事务T2的重做日志占用100字节,。由于每个log block实际只能保存492字节,因此其在log buffer的情况应该如图所示
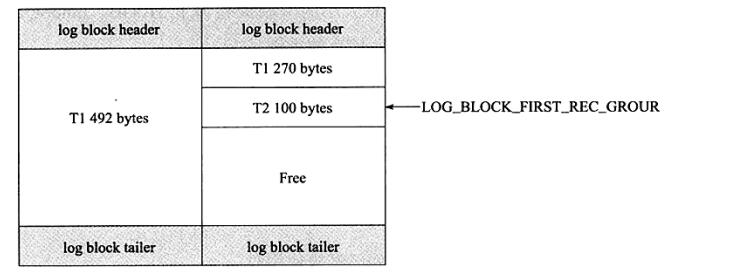
从图可以观察到,由于事务T1的重做日志占用792字节,因此需要占用两个log block。左侧的log block中 LOG_BLOCK_FIRST_REC_GROUP为12,级log block中第一个日志的开始位置,在第二个log block中,由于包含了之前事务T1的重做日志,事务T2的日志才是log block中第一日志,因此该log block的LOG_BLOCK_FIRST_REC_GROUP为(270+12)
LOG_BLOCK_CHECKPOINT_NO占用4字节,表示该log block最后被写入时的检查点第4字节的值
log block tailer 只由1个部分组成,且值和LOG_BLOCK_HDR_NO相同,并在函数log_block_init中被初始化 LOG_BLOCK_TRL_NO 大小为4字节
3 log group
log group 重做日志组,其中有多个重做日志文件,虽然源码已经支持log group的景象功能,但是在ha_innobase.cc文件中禁止了该功能,因此,InnoDB存储引擎实际只由一个log group
log group是一个逻辑的概念,并没有一个实际的物理文件来表示log group信息,log group 由多个重做日志文件组成,每个log group中的日志文件是相同的,且在InnoDB 1.2版本之前,重做日志文件的总大小要小于4GB,从InnoDB 1.2版本开始重做日志文件的总大小限制提高为512GB,InnoSQL版本的InnoDB存储引擎在1.1版本就支持大于4GB的重做日志
重做日志文件中存储就是之前log buffer中保存的log block。因此其也是根据块的方式进行物理存储的管理,每个块的大小与log block一样,同样为512字节,在InnoDB存储引擎运行过程中,log buffer根据一定的规则将内存中的log block刷新到磁盘。这个规则具体是
事务提交时
当log buffer中有一半的内存空间已经被使用时
log checkpoint时
对于log block的写入追加在redo log file最后部分,当一个redo log file写满时,会接着写下一个redo log file,其使用的方式为round-robin
虽然log block总是在redo log file的最后部分进行写入,有的读者可能以为对redo log file的写入时顺序的,其实不是,因为redo log file除了保存log buffer刷新到磁盘的log block,还保存了一些其他的信息,这些信息一共占用2KB大小,即每个redo log file的前2KB的部分不保存log block信息,对于log group中的第一个redo log file,其前2KB的部分保存4个512字节大小的块,其中存放的内容为

需要特别注意,上述信息仅在每个log group的第一个redo log file中进行存储,log group中的其余redo log file仅保留这些空间,但不保存上述信息。正因为保存了这些信息,就意味着对redo log file 的写入并不是完全顺序的。因为其除了log block的写入操作,还需要更新前2KB部分的信息,这些信息对于InnoDB存储引擎的恢复操作来说非常关键和重要,故log group与redo log file 之间的关系如下
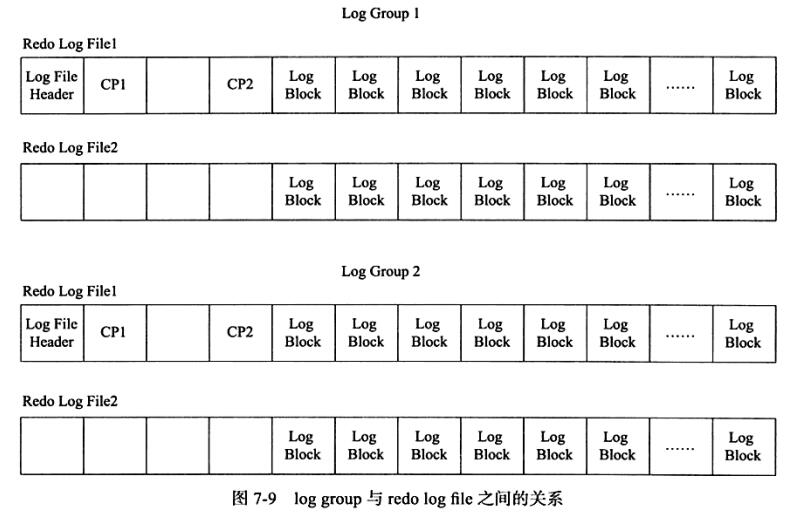
在log filer header 后面的部分为InnoDB存储引擎保存的checkpoint(检查点)值,其设计时交替写入。这样的设计避免了因介质失败而导致无法找到可用的checkpoint的情况
4 重做日志格式
不同的数据库操作会有对应的重做日志格式。此外,由于InnoDB存储引擎的存储管理是基于页的,故其重做日志格式也是基于页的。虽然有着不同的重做日志格式,但他们有着通用的头部格式,如图

通用的头部格式由一下3部分组成
redo_log_type 重做日志类型
space: 表空间ID
page_no 页的偏移量
之后是redo log body ,根据重做日志类型的不对,会有不同的存储内容,例如,对于页上记录的插入和删除操作,分别对应的如图的格式
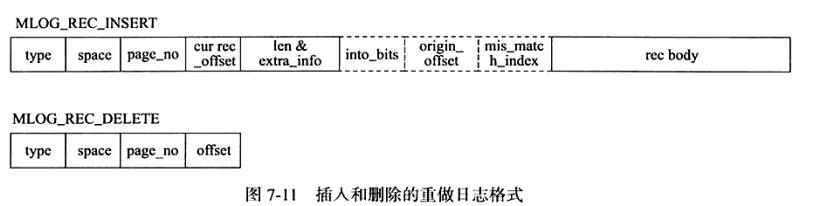
到InnoDB 1.2版本只是,一共有51中重做日志的类型。随着功能不断增加,相信会加入更多的重做日志类型
5 LSN
LSN是Log Sequence Number的缩写,其代表的是日志序列号,在InnoDB存储引擎中,LSN占用8个字节,并且单调递增。LSN的含义
重做日志的写入的总量
checkpoint的位置
页的版本
LSN表示事务写入重做日志字节的总量。例如当前重做日志的LSN为1000,有一个事务T1写入了100字节的重做日志,那么LSN久变成1100,若又有事务T2写入200字节的重做日志,那么LSN久变为1300,课件LSN记录的是重做日志的总量,其单位为字节
LSN不仅记录在重做日志中,还存在每个页中,在每个页的头部,有一个值FIL_PAGE_LSN,记录了该页的LSN,在页中,LSN表示该页最后刷新时LSN的大小。因为重做日志记录的是每个页的日志,因此页中的LSN可以判断页是否需要进行恢复操作。例如,页P1的LSN诶10000,而数据库启动时,InnoDB检测到写入重做日志中的LSN为13000,并且事务已经提交,那么数据库需要进行恢复操作。将重做日志应用到P1页中,同样的,对于重做日志中LSN小于P1页的LSN,不需要进行重做,因为P1页中的LSN标示已经被刷新到该位置
用户可以通过命令SHOW ENGINE INNODB STATUS查看LSN的情况
--- LOG --- Log sequence number 1087932358 Log flushed up to 1087932358 Pages flushed up to 1087932358 Last checkpoint at 1087932358 0 pending log writes, 0 pending chkp writes 8 log i/o's done, 0.00 log i/o's/second
Log sequence number 表示当前的LSN
Log flushed up to 表示刷新到重做日志文件的LSN
Last checkpoint at 表示刷新到磁盘的LSN
虽然在上面的例子中,Log sequence number和Log flushed up to 值是相同的,但是在实际生产环境中,该值可能不同,因为在一个事务中从日志缓冲刷新到重做日志文件并不只是在事务提交时发生,每秒都会有从日志缓冲刷新到重做日志文件的动作,下面是在生成环境下重做日志的信息示例
--- LOG --- Log sequence number 18766833801 Log flushed up to 18766832201 Pages flushed up to 18766816420 Last checkpoint at 18766816420
在生成环境下Log sequence number Log flushed up to Last checkpoint at 三个值可能不同
6 恢复
InnoDB存储引擎在启动时不管上次数据运行是否正常关闭,都会尝试进行恢复操作,因为重做日志记录的是物理日志,因此恢复的速度比逻辑日志,如二进制日志要快的多,于此同时,InnoDB存储引擎自身也对恢复进行了一定程度的优化,如顺序读取及并行应用重做日志,这样可以进一步提高数据库恢复的速度
由于checkpoint表示已经刷新到磁盘页上的LSN,因此在恢复过程中仅需恢复checkpoint开始的日志部分。对于图中的例子,当数据库在checkpoint的LSN为10 000时发生宕机,恢复操作仅恢复LSN 10000~13000范围内的日志

InnoDB存储引擎重做日志是物理日志,因此其恢复的速度较之二进制日志恢复快的多,例如对Insert操作,其记录的是每个页的变化,对于下面的表
CREATE TABLE t(a INT ,b INT,PRIMARY KEY(a),key(b));
若执行SQL语句
INSERT INTO t SELECT 1,2;
由于需要对聚集索引页和辅助索引页进行操作,其记录的重做日志大致为
page(2,3),offset 32,value 1,2 #聚集索引 page(2,4),offset 64,value 2 #辅助索引
可以看到记录的是页的物理修改曹邹,若插入涉及B+树的split,可能会有更多的页需要记录日志。此外,由于重做日志是物理日志,因此其是幂等的,幂等的概念如下
f(f(x))=f(x)
但INSERT操作在二进制日志不是幂等,重复执行可能会插入多条重复的记录,而上述INSERT操作的重做日志是幂等的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号