

kuda 了解片
本来上个月想去了解一下kuda的,结果一直没有抽出时间去搞,现在大致先开个头,方便后面深入!
Apache Kudu是开源Apache Hadoop生态系统的新成员,它完善了Hadoop的存储层,可以 快速分析快速数据。
Kudu提供快速插入/更新和高效柱状扫描的组合,以在单个存储层上实现多个实时分析工作负载。作为HDFS和Apache HBase的新补充,Kudu使架构师能够灵活地处理各种用例,而无需异乎寻常的解决方法。
Kudu专为需要快速(快速变化)数据快速分析的用例而设计。Kudu专为利用下一代硬件和内存处理而设计,可显着降低Apache Impala(孵化)和Apache Spark(最初与其他执行引擎)的查询延迟。
Kudu和Impala均是Cloudera贡献给Apache基金会的顶级项目。
之前一直是 hdfs+Parquet+hive+impala
现在很多厂有用kuda+impala(或其他),
去百度一番,快速了解一下。
kuda大致了解
Kudu作为底层存储,在支持高并发低延迟kv查询的同时,还保持良好的Scan性能,该特性使得其理论上能够同时兼顾OLTP类和OLAP类查询。
Impala作为老牌的SQL解析引擎,其面对即时快速查询(Ad-Hoc Query)类请求的稳定性和速度在工业界得到过广泛的验证,Impala并没有自己的存储引擎,其负责解析SQL,并连接其底层的存储引擎。在发布之初Impala主要支持HDFS,Kudu发布之后,Impala和Kudu更是做了深度集成。
在众多大数据框架中,Impala定位类似Hive,不过Impala更关注即席查询SQL的快速解析,对于执行时间过长的SQL,仍旧是Hive更合适。
对于GroupBy等SQL查询,Impala进行的是内存计算,因而Impala对机器配置要求较高,官方建议内存128G以上,此类问题Hive底层对应的是传统的MapReduce计算框架,虽然执行效率低,但是稳定性好,对机器配置要求也低。
执行效率是Impala的最大优势,对于存储在HDFS中的数据,Impala的解析速度本来就远快于Hive,有了Kudu加成之后,会是如虎添翼,部分查询执行速度差别可达百倍。
值得注意的是,Kudu和Impala的英文原意是来自非洲的两个不同品种的羚羊,Cloudera这个公司非常喜欢用跑的快的动物来作为其产品的命名。
Kudu的典型使用场景
流式实时计算场景
流式计算场景通常有持续不断地大量写入,与此同时这些数据还要支持近乎实时的读、写以及更新操作。Kudu的设计能够很好的处理此场景。
时间序列存储引擎(TSDB)
Kudu的hash分片设计能够很好地避免TSDB类请求的局部热点问题。同时高效的Scan性能让Kudu能够比Hbase更好的支持查询操作。
机器学习&数据挖掘
机器学习和数据挖掘的中间结果往往需要高吞吐量的批量写入和读取,同时会有少量的随机读写操作。Kudu的设计可以很好地满足这些中间结果的存储需求。
与历史遗产数据共存
在工业界实际生产环境中,往往有大量的历史遗产数据。Impala可以同时支持HDFS、Kudu等多个底层存储引擎,这个特性使得在使用的Kudu的同时,不必把所有的数据都迁移到Kudu。
Kudu中的重要概念
列式存储
毫无疑问,Kudu是一个纯粹的列式存储引擎,相比Hbase只是按列存放数据,Kudu的列式存储更接近于Parquet,在支持更高效Scan操作的同时,还占用更小的存储空间。列式存储有如此优势,主要因为两点:1. 通常意义下的OLAP查询只访问部分列数据,列存储引擎在这种情况下支持按需访问,而行存储引擎则必须检索一行中的所有数据。2. 数据按列放一起一般意义来讲会拥有更高的压缩比,这是因为列相同的数据往往拥有更高的相似性。
Table
Kudu中所有的数据均存储在Table之中,每张表有其对应的表结构和主键,数据按主键有序存储。因为Kudu设计为支持超大规模数据量,Table之中的数据会被分割成为片段,称之为Tablet。
Tablet
一个Tablet把相邻的数据放在一起,跟其他分布式存储服务类似,一个Tablet会有多个副本放置在不同的服务器上面,在同一时刻,仅有一个Tablet作为leader存在,每个副本均可单独提供读操作,写操作则需要一致性同步写入。
Tablet Server
Tablet服务顾名思义,对Tablet的读写操作会通过该服务完成。对于一个给定的tablet,有一个作为leader,其他的作为follower,leader选举和灾备原则遵循Raft一致性算法,该算法在后文中有介绍。需要注意的是一个Tablet服务所能承载的Tablet数量有限,这也要求的Kudu表结构的设计需要合理的设置Partition数量,太少会导致性能降低,太多会造成过多的Tablet,给Tablet服务造成压力。
Master
master存储了其他服务的所有元信息,在同一时刻,最多有一个master作为leader提供服务,leader宕机之后会按照Raft一致性算法进行重新选举。
master会协调client传来的元信息读写操作。比如当创建一个新表的时候,client发送请求给master,master会转发请求给catelog、 tablet等服务。
master本身并不存储数据,数据存储在一个tablet之中,并且会按照正常的tablet进行副本备份。
Tablet服务会每秒钟跟master进行心跳连接。
Raft Consensus Algorithm
Kudu 使用Raft一致性算法,该算法将节点分为follower、candidate、leader三种角色,当leader节点宕机时,follower会成为candidate并且通过多数选举原则成为一个新的leader,因为有多数选举原则,所以在任意时刻,最多有一个leader角色。leader接收client上传的数据修改指令并且分发给follower,当多数follower写入时,leader会认为写入成功并告知client。
Catalog Table
Catelog表存储了Kudu的一些元数据,包括Tables和Tablets。(catalog table)目录表可能无法直接读取或写入。相反,它只能通过客户端API中公开的元数据操作访问。
Tables:table schemas, locations, and states
Tablets:the list of existing tablets, which tablet servers have replicas of each tablet, the tablet’s current state, and start and end keys.
Logical replication
Logical Replication(逻辑复制)Kudu复制操作,而不是磁盘数据。这称为逻辑复制,而不是物理复制。这有几个好处:
-
尽管插入和更新确实通过网络传输数据,但删除操作不需要移动任何数据。删除操作将发送到每个tablet server(服务器),该服务器在本地执行删除。
-
物理操作(例如压缩)不需要在Kudu中通过网络传输数据。这与使用HDFS的存储系统不同,后者需要通过网络传输块以满足所需数量的副本。
-
tables不需要同时或在相同的时间表上执行压缩,或者在物理存储层上保持同步。由于压缩或大量写入负载,这降低了所有tables(平板电脑)服务器同时遇到高延迟的可能性。
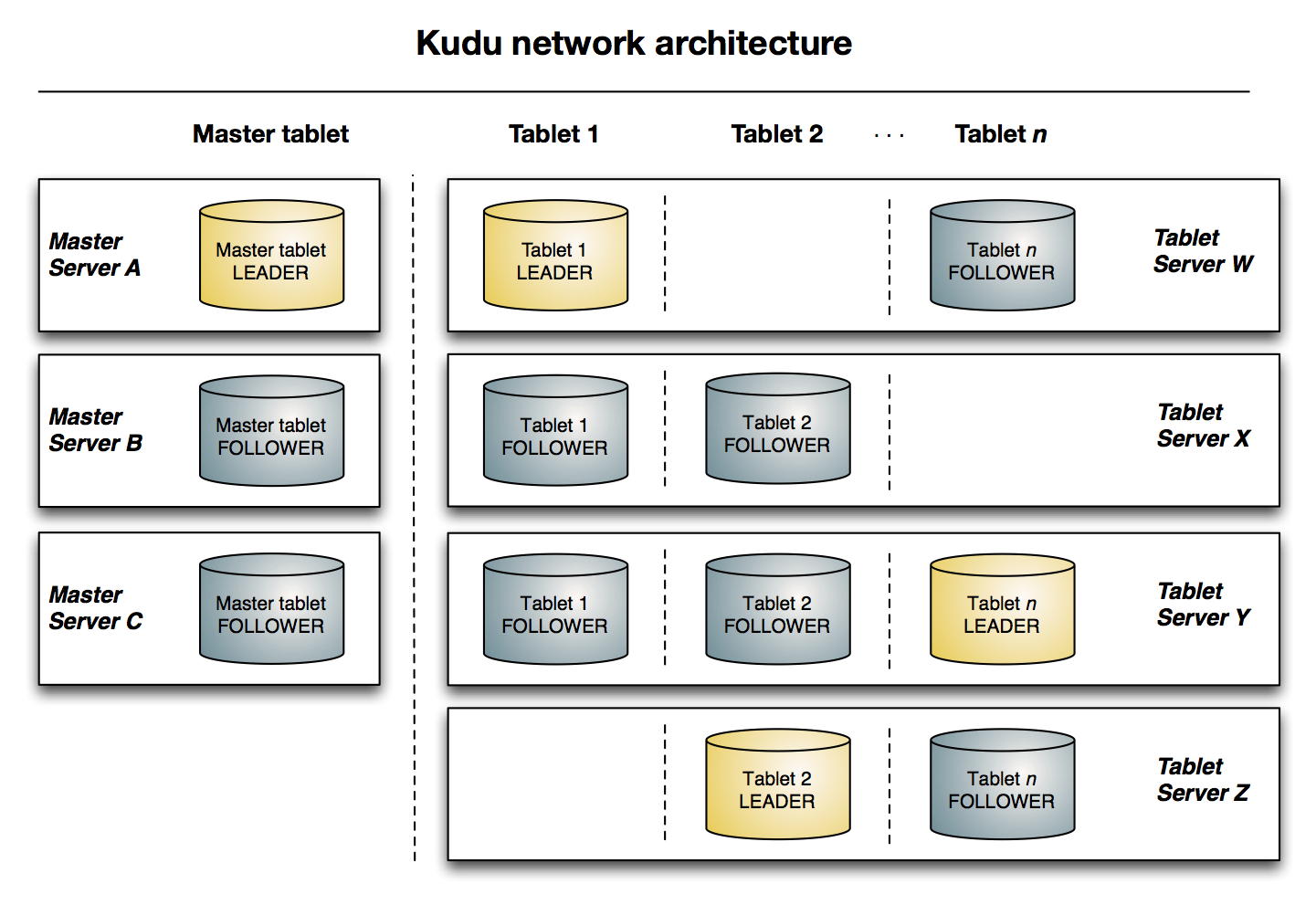
Kudu架构概览
从下图可以看出有三台Master,其中一个是leader,另外两个是follower。
有四台Tablet server,n个tablets及其副本均匀分布在这四台机器上。每个tablet有一个leader,两个follower。每个表会按照分片的数量分成多个tablet。
leader以黄金显示,而follower以蓝色显示。
Kudu+Impala对我们意味着什么
Kudu+Impala为实时数据仓库存储提供了良好的解决方案。这套架构在支持随机读写的同时还能保持良好的Scan性能,同时其对Spark等流式计算框架有官方的客户端支持。这些特性意味着数据可以从Spark实时计算中实时的写入Kudu,上层的Impala提供BI分析SQL查询,对于数据挖掘和算法等需求可以在Spark迭代计算框架上直接操作Kudu底层数据。
Kudu-Impala集成功能
CREATE/ALTER/DROP TABLE
Impala支持使用Kudu作为持久层创建,更改和删除表。这些表遵循与Impala中其他表相同的内部/外部方法,允许灵活的数据提取和查询。
INSERT
可以使用与任何其他Impala表相同的语法将数据插入Impala中的Kudu表,例如使用HDFS或HBase进行持久化的表。
UPDATE / DELETE
Impala支持UPDATE和DELETESQL命令逐行或批量修改Kudu表中的现有数据。选择SQL命令的语法与现有标准尽可能兼容。除了simple DELETE 或UPDATE命令之外,还可以使用FROM子查询中的子句指定复杂连接。
灵活的分区
与Hive中的表分区类似,Kudu允许您通过散列或范围动态地将表预分割为预定义数量的平板电脑,以便在集群中均匀分配写入和查询。您可以按任意数量的主键列,任意数量的哈希值和可选的拆分行列表进行分区。请参阅架构设计。
并行扫描
为了在现代硬件上实现最高性能,Impala使用的Kudu客户端在多个平板电脑上并行扫描。
高效查询
在可能的情况下,Impala将谓词评估推送到Kudu,以便尽可能接近数据评估谓词。在许多工作负载中,查询性能与Parquet相当。
有关使用Impala查询存储在Kudu中的数据的更多详细信息,请参阅Impala文档。
Spark集成最佳实践
每个群集避免多个Kudu客户端。
一个常见的Kudu-Spark编码错误是实例化额外的KuduClient对象。在kudu-spark中,a KuduClient属于KuduContext。Spark应用程序代码不应创建另一个KuduClient连接到同一群集。相反,应用程序代码应使用KuduContext访问KuduClient使用KuduContext#syncClient。
要诊断KuduClientSpark作业中的多个实例,请查看主服务器的日志中的符号,这些符号会被来自不同客户端的许多GetTableLocations或 GetTabletLocations请求过载,通常大约在同一时间。这种症状特别适用于Spark Streaming代码,其中创建KuduClient每个任务将导致来自新客户端的主请求的周期性波。
Spark集成已知问题和限制
-
Spark 2.2+在运行时需要Java 8,即使Kudu Spark 2.x集成与Java 7兼容。Spark 2.2是Kudu 1.5.0的默认依赖版本。
-
当注册为临时表时,必须为名称包含大写或非ascii字符的Kudu表分配备用名称。
-
包含大写或非ascii字符的列名的Kudu表不能与SparkSQL一起使用。可以在Kudu中重命名列以解决此问题。
-
<>并且OR谓词不会被推送到Kudu,而是由Spark任务进行评估。只有LIKE带有后缀通配符的谓词才会被推送到Kudu,这意味着它LIKE "FOO%"被推下但LIKE "FOO%BAR"不是。 -
Kudu不支持Spark SQL支持的每种类型。例如,
Date不支持复杂类型。 -
Kudu表只能在SparkSQL中注册为临时表。使用HiveContext可能无法查询Kudu表。
Kudu以及Impala的不足
Kudu主键的限制
- 表创建后主键不可更改;
- 一行对应的主键内容不可以被Update操作修改。要修改一行的主键值,需要删除并新增一行新数据,并且该操作无法保持原子性;
- 主键的类型不支持DOUBLE、FLOAT、BOOL,并且主键必须是非空的(NOT NULL);
- 自动生成的主键是不支持的;
- 每行对应的主键存储单元(CELL)最大为16KB。
Kudu列的限制
- MySQL中的部分数据类型,如DECIMAL, CHAR, VARCHAR, DATE, ARRAY等不支持;
- 数据类型以及是否可为空等列属性不支持修改;
- 一张表最多有300列。
Kudu表的限制
- 表的备份数必须为奇数,最大为7;
- 备份数在设置后不可修改。
Kudu单元(Cells)的限制
- 单元对应的数据最大为64KB,并且是在压缩前。
Kudu分片的限制
- 分片只支持手动指定,自动分片不支持;
- 分片设定不支持修改,修改分片设定需要”建新表-导数据-删老表”操作;
- 丢掉多数备份的Tablets需要手动修复。
Kudu容量限制
- 建议tablet servers的最大数量为100;
- 建议masters的最大数量为3;
- 建议每个tablet server存储的数据最大为4T(此处存疑,为何会有4T这么小的限制?);
- 每个tablet server存储的tablets数量建议在1000以内;
- 每个表分片后的tablets存储在单个tablet server的最大数量为60。
Kudu其他使用限制
- Kudu被设计为分析的用途,每行对应的数据太大可能会碰到一些问题;
- 主键有索引,不支持二级索引(Secondary indexes);
- 多行的事务操作不支持;
- 关系型数据的一些功能,如外键,不支持;
- 列和表的名字强制为UTF-8编码,并且最大256字节;
- 删除一列并不会马上释放空间,需要执行Compaction操作,但是Compaction操作不支持手动执行;
- 删除表的操作会立刻释放空间。
Impala的稳定性
- Impala不适合超长时间的SQL请求;
- Impala不支持高并发读写操作,即使Kudu是支持的;
- Impala和Hive有部分语法不兼容。
FAQ
Impala支持高并发读写吗?
不支持。虽然Impala设计为BI-即席查询平台,但是其单个SQL执行代价较高,不支持低延时、高并发场景。
Impala能代替Hive吗?
不能,Impala设计为内存计算模型,其执行效率高,但是稳定性不如Hive,对于长时间执行的SQL请求,Hive仍然是第一选择。
Impala需要多少内存?
类似于Spark,Impala会把数据尽可能的放入内存之中进行计算,虽然内存不够时,Impala会借助磁盘进行计算,但是毫无疑问,内存的大小决定了Impala的执行效率和稳定性。Impala官方建议内存要至少128G以上,并且把80%内存分配给Impala
Impala有Cache吗?
Impala不会对表数据Cache,Impala仅仅会Cache一些表结构等元数据。虽然在实际情况下,同样的query第二次跑可能会更快,但这不是Impala的Cache,这是Linux系统或者底层存储的Cache。
Impala可以添加自定义函数吗?
可以。Impala1.2版本支持的UDFs,不过Impala的UDF添加要比Hive复杂一些。
Impala为什么会这么快?
Impala为速度而生,其在执行效率细节上做了很多优化。在大的方面,相比Hive,Impala并没有采用MapReduce作为计算模型,MapReduce是个伟大的发明,解决了很多分布式计算问题,但是很遗憾,MapReduce并不是为SQL而设计的。SQL在转换成MapReduce计算原语时,往往需要多层迭代,数据需要较多的落地次数,造成了极大地浪费。
- Impala会尽可能的把数据缓存在内存中,这样数据不落地即可完成SQL查询,相比MapReduce每一轮迭代都落地的设计,效率得到极大提升。
- Impala的常驻进程避免了MapReduce启动开销,MapReduce任务的启动开销对于即席查询是个灾难。
- Impala专为SQL而设计,可以避免每次都把任务分解成Mapper和Reducer,减少了迭代的次数,避免了不必要的Shuffle和Sort。
同时Impala现代化的计算框架,能够更好的利用现代的高性能服务器。
- Impala利用LLVM生成动态执行的代码
- Impala会尽可能的利用硬件配置,包括SSE4.1指令集去预取数据等等。
- Impala会自己控制协调磁盘IO,会精细的控制每个磁盘的吞吐,使得总体吞吐最大化。
- 在代码效率层面上,Impala采用C++语言完成,并且追求语言细节,包括内联函数、内循环展开等提速技术
- 在程序内存使用上,Impala利用C++的天然优势,内存占用比JVM系语言小太多,在代码细节层面上也遵循着极少内存使用原则,这使得可以空余出更多的内存给数据缓存。
Kudu相比Hbase有何优势,为什么?
Kudu在某些特性上和Hbase很相似,难免会放在一起比较。然而Kudu和Hbase有如下两点本质不同。
- Kudu的数据模型更像是传统的关系型数据库,Hbase是完全的no-sql设计,一切皆是字节。
- Kudu的磁盘存储模型是真正的列式存储,Kudu的存储结构设计和Hbase区别很大。
综合而言,纯粹的OLTP请求比较适合Hbase,OLTP与OLAP结合的请求适合Kudu。
Kudu是纯内存数据库吗?
Kudu不是纯内存数据库,Kudu的数据块分MemRowSet和DiskRowSet,大部分数据存储在磁盘上。
Kudu拥有自己的存储格式还是沿用Parquet的?
Kudu的内存存储采用的是行存储,磁盘存储是列存储,其格式和Parquet很相似,部分不相同的部分是为了支持随机读写请求。
compactions需要手动操作吗?
compactions被设计为Kudu自动后台执行,并且是缓慢分块执行,当前不支持手动操作。
Kudu支持过期自动删除吗?
不支持。Hbase支持该特性。
Kudu有和Hbase一样的局部热点问题吗?
现代的分布式存储设计往往会把数据按主键进行有序存储。这样会造成一些局部的热点访问,比如把时间作为主键的日志实时存储模型中,日志的写入总是在时间排序的最后,这在Hbase中会造成严重的局部热点。Kudu也有同样的问题,但是比Hbase好很多,Kudu支持hash分片,数据的写入会先按照hash找到对应的tablet,再按主键有序的写入。
Kudu在CAP理论中的位置?
和Hbase一样,Kudu是CAP中的CP。只要一个客户端写入数据成功,其他客户端读到的数据都是一致的,如果发生宕机,数据的写入会有一定的延时。
Kudu支持多个索引吗?
不支持,Kudu只支持Primary Key一个索引,但是可以把Primary Key设置为包含多列。自动增加的索引、多索引支持、外键等传统数据库支持的特性Kudu正在设计和开发中。
Kudu对事务的支持如何?
Kudu不支持多行的事务操作,不支持回滚事务,不过Kudu可以保证单行操作的原子性。
Example Use Cases
数据分析中的一个常见挑战是新数据快速且持续地到达,并且需要几乎实时地提供相同的数据以进行读取,扫描和更新。Kudu提供快速插入和更新的强大组合,以及高效的柱状扫描,以在单个存储层上实现实时分析用例。
时间序列模式是根据数据点发生的时间组织和键入数据点的模式。这对于随时间调查指标的性能或尝试根据过去的数据预测未来行为非常有用。例如,时间序列客户数据可用于存储购买点击流历史记录和预测未来购买,或供客户支持代表使用。虽然这些不同类型的分析正在发生,但插入和突变也可能单独和大量发生,并且可立即用于读取工作负载。Kudu可以以可扩展且高效的方式同时处理所有这些访问模式。
由于多种原因,Kudu非常适合时间序列工作负载。由于Kudu支持基于散列的分区,结合其对复合行密钥的本机支持,可以很容易地设置跨多个服务器的表,而不会出现使用范围分区时常见的“热点”风险。Kudu的柱状存储引擎在这种情况下也很有用,因为许多时间序列工作负载只读取几列,而不是整行。
过去,您可能需要使用多个数据存储来处理不同的数据访问模式。这种做法增加了应用程序和操作的复杂性,并使数据重复,使所需的存储量翻倍(或更差)。Kudu可以本地高效地处理所有这些访问模式,而无需将工作卸载到其他数据存储。
数据科学家经常从大量数据集开发预测性学习模型。当学习发生或建模的情况发生变化时,可能需要经常更新或修改模型和数据。此外,科学家可能想要改变模型中的一个或多个因素,看看随着时间的推移会发生什么。更新存储在HDFS中的文件中的大量数据是资源密集型的,因为每个文件都需要完全重写。在Kudu,更新几乎是实时发生的。科学家可以调整值,重新运行查询,并在几秒或几分钟内刷新图表,而不是几小时或几天。此外,批处理或增量算法可以随时在数据上运行,并具有接近实时的结果。
其他补充:
1.参考 kuda的官网: https://kudu.apache.org/overview.html#architecture
2.OLTP(On-line Transaction Processing) 面向的是高并发低延时的增删改查(INSERT, DELETE, UPDATE, SELECT, etc..)。
OLAP(On-line Analytical Processing) 面向的是BI分析型数据请求,其对延时有较高的容忍度,处理数据量相较OLTP要大很多。
传统意义上与OLTP对应的是MySQL等关系型数据库,与OLAP相对应的则是数据仓库。OLTP与OLAP所面向的数据存储查询引擎是不同的,其处理的请求不一样,所需要的架构也大不相同。这个特点意味着数据需要储存在至少两个地方,需要定期或者实时的同步,同时还需要保持一致性,该特点对数据开发工程师造成了极大的困扰,浪费了同学们大量的时间在数据的同步和校验上。Kudu+Impala的出现,虽然不能完美的解决这个问题,但不可否认,其缓解了这个矛盾。
在此需要注意的是OLTP并没有严格要求其事务处理满足ACID四个条件。事实上,OLTP是比ACID更早出现的概念。在本文中,OLTP和OLAP的概念关注在数据量、并发量、延时要求等方面,不关注事务。
