软工作业4:词频统计
一、基本信息
1 # 编译环境:Pycharm2018、Python3.7 2 # 项目名称:词频统计——基本功能(结对编程) 3 # 作者: 1613072046:霍星 1613072047:梅岭
二、项目分析
Task1:基本任务
主要需要解决二个问题:1、统计文件的有效行数;2、统计文件的单词总数(其中特殊定义了单词的定义);3、将数据存储在文本中
1.1、统计文件的有效行数
lines = len(open(dst, 'r').readlines())
1.2、使用正则表达式统计文件的单词总数
1 def process_buffer(dst, phrase_words, regex): 2 words = open(dst, 'r', encoding="gb2312").read() # 文本读取 3 bvffer = words.lower() # 将文本内容都改为小写 4 # 将文本中的缩写都替换 5 bvffer = bvffer.replace('’t', '') 6 bvffer = bvffer.replace('’m', '') 7 bvffer = bvffer.replace('’s', '') 8 bvffer = bvffer.replace('’ve', '') 9 for i in range(len(phrase_words)): # 将文本中的“停词”删除掉 10 bvffer = bvffer.replace(' ' + phrase_words[i] + ' ', ' ') 11 result = re.findall(regex, bvffer) # 正则查找词组 12 word_freq = {} 13 for word in result: # 将正则匹配的结果进行统计 14 word_freq[word] = word_freq.get(word, 0) + 1 15 return word_freq
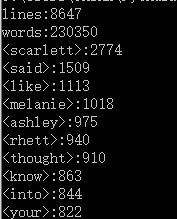
1.3、统计文件中各单词的出现次数,最终只输出频率最高的10个。频率相同的单词,优先输出字典序靠前的单词
1 def output_result(word_freq): 2 if word_freq: 3 sorted_word_freq = sorted(word_freq.items(), key=lambda v: v[1], reverse=True) 4 for item in sorted_word_freq[:10]: # 输出 Top 10 的单词 5 print("(%s,%d) " % (item[0], item[1]))
1.4性能 测试
1 if __name__ == '__main__': 2 cProfile.run("main()", "pstats_result") 3 # 调用pstats模块分析结果 4 p = pstats.Stats("pstats_result") # 创建Stats对象 5 p.strip_dirs().sort_stats("call").print_stats() # 按照调用的次数排序 6 p.strip_dirs().sort_stats("cumulative").print_stats() # 按执行时间次数排序
Task 2:任务进阶
2.1支持 stop words
1 def process_buffer(bvffer, dst): 2 txt_words = open(dst, 'r').readlines() # 读取停词表文件 3 stop_words = [] # 存放停词表的list 4 for i in range(len(txt_words)): 5 txt_words[i] = txt_words[i].replace('\n', '') 6 stop_words.append(txt_words[i]) 7 if bvffer: 8 word_freq = {} # 下面添加处理缓冲区 bvffer代码,统计每个单词的频率,存放在字典word_freq 9 bvffer = bvffer.lower() # 将文本内容都改为小写 10 for ch in '“‘!;,.?’”': # 除去文本中的中英文标点符号 11 bvffer = bvffer.replace(ch, " ") 12 words = bvffer.strip().split() 13 # strip()删除空白符(包括'/n', '/r','/t');split()以空格分割字符串 14 for word in words: 15 if word in stop_words: # 如果word在停词表里就跳过(本任务核心) 16 continue 17 else: 18 word_freq[word] = word_freq.get(word, 0) + 1 19 return word_freq
2.2定义短语与输出
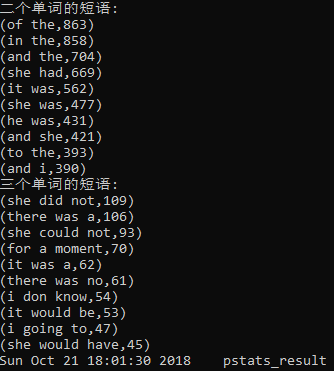
1 def main(): 2 # 涉及到的文本路径 3 txt_dst = 'E:/桌面/untitled/Gone_with_the_wind.txt' 4 two_phrase_dst = 'E:/桌面/untitled/phrase.txt' 5 three_phrase_dst = 'E:/桌面/untitled/phrase_three.txt' 6 # 正则表达式 7 two_phrase_re = '[a-z]+\s[a-z]+' # 匹配二个单词的短语 8 three_phrase_re = '[a-z]+\s[a-z]+\s[a-z]+' # 匹配三个单词的短语 9 10 print('二个单词的短语:') 11 phrase_words = create_stop_words(two_phrase_dst) 12 word_freq = process_buffer(txt_dst, phrase_words, two_phrase_re) 13 output_result(word_freq) 14 15 print('三个单词的短语:') 16 phrase_words = create_stop_words(three_phrase_dst) 17 word_freq = process_buffer(txt_dst, phrase_words, three_phrase_re) 18 output_result(word_freq)
2.3程序运行截图
Task:基本任务
Task:常用短语
时间运行
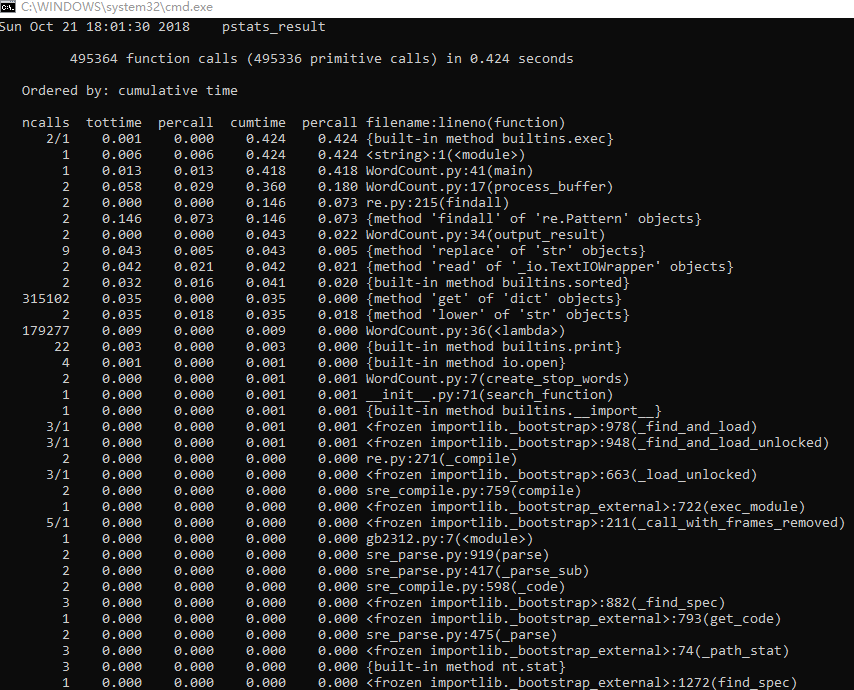
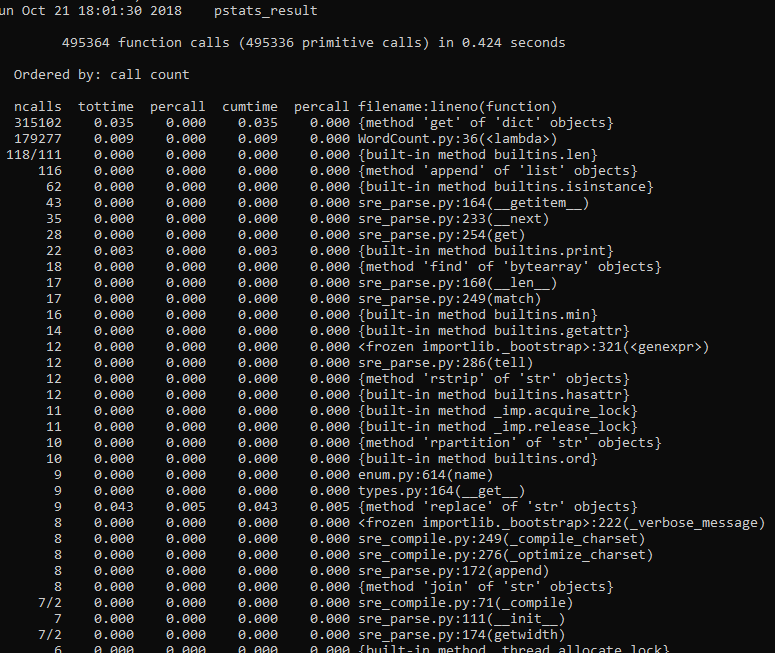
三、性能分析
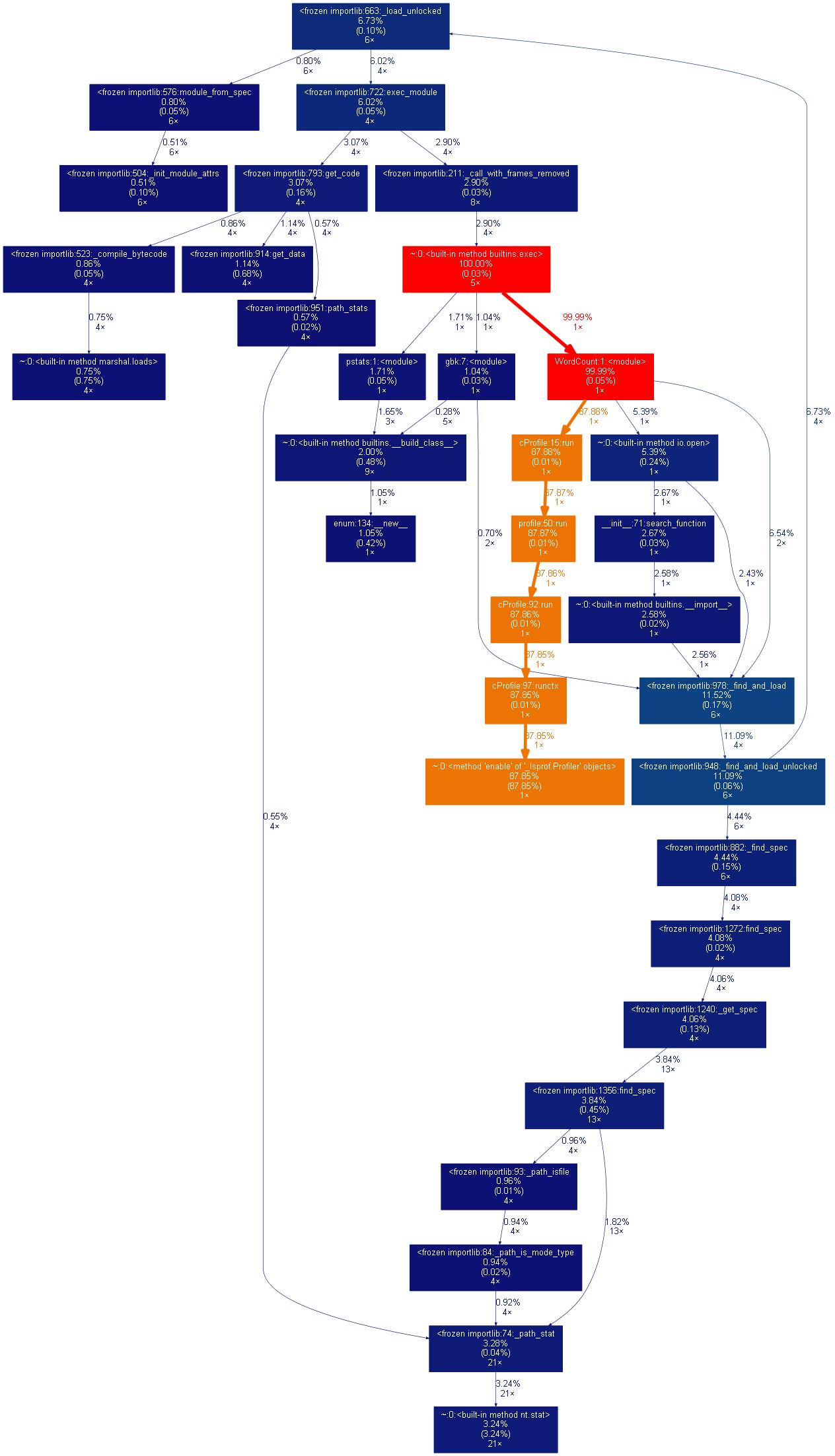
四、其他
结对编程时间开销:两人经过一星期的研究,查找资料,讨论与学习,最终编程时间大约为8小时
结对编程照片:

五、事后分析与总结
在这次结对编程的过程中感受到了以往单独编程没有体会到的编程体验,在编程的过程中我和梅岭相互讨论与学习,最终得出结论的过程是单独编程时体会不到的,希望以后能更多的参与这类编程,这样能相互督促,并且一起提高能力
