

20145211 《信息安全系统设计基础》第九周学习总结
20145211 《信息安全系统设计基础》第九周学习总结——客心不自得,浩漫将何之
知识点梳理
系统级I/O概述
- 输入输出I/O
输入输出I/O是在主存和外部设备(如磁盘,网络和终端)之间拷贝数据的过程。
输入就是从I/O设备拷贝数据到贮存
- 输出就是从主存拷贝数据到I/O设备
- 使用原因
帮助理解其它系统概念。I/O视操作系统中不可或缺的一部分,我们会经常遇到I/O和其它系统概念之间的循环依赖。
别无选择。例如:标准I/O库没有提供读取文件元数据的方式,如文件大小和文件创建时间。
Unix I/O
一个Unix文件就是一个m个字节的序列:B0,B1,...,Bk,...,B(m-1)
所有的I/O设备,如网络、磁盘、和终端,都被模型化为文件,而所有的输入和输出都被当做想对应的文件的读写来执行。这种将设备优雅的映射为文件的方式,允许Unix内核引出一个简单、低级的应用接口,称为UnixI/O,这使得所有的输入和输出都能以一种统一且一致的方式来执行。
- 打开文件
一个应用程序通过要求内核来打开文件,内核返回一个小的非负整数(描述符),内核记录有关这个文件的所有的信息,应用程序只需要记住这个描述符。
- Unix外壳创建的每个进程开始时都有三个打开的文件:
标准输入(描述符为0)
标准输出(描述符为1)
标准错误(描述符为2)
头文件<unistd.h>
定义常量STDIN_FILENO、STDOUT_FILENO、STDERR_FILENO
可以用来代替显式的描述符
2. 改变当前的文件位置。
对于每个打开的文件,内核保持着一个文件位置k,初始为0。这个位置是从文件开头起始的字节偏移量。
应用程序可以通过seek操作显式的设置文件的当前位置为k。
3. 读写文件
读操作就是从文件拷贝n>0个字节到存储器,从当前文件位置k开始,然后将k增加到k+n。
给定一个大小为m字节的文件,k >= m 时执行读操作会触发一个称为end-of-file(EOF)的条件,应用程序能检测到这个条件,但是文件结尾处并没有明确的“EOF符号”。
写操作就是从存储器拷贝n>0个字节到一个文件,从当前文件位置k开始,然后更新k。
- 关闭文件
应用通知内核关闭这个文件。作为响应,内核释放文件打开时创建的数据结构,并将这个描述符恢复到可用的描述符池当中。
无论进程因为何种原因终止时,内核都会关闭所有打开的文件并释放他们的存储器资源。
- 打开和关闭文件
- 打开文件:
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int open(char *filename,int fliags,mod_it mode);
- 若成功,返回值为新文件描述符
- 若出错,返回值为-1
open函数将filename转换成一个文件描述符,并且返回描述符数字。返回的描述符总是在进程中当前没有打开的最小描述符。
fd = Open("文件名",flag参数,mode参数)
fd是返回的文件描述符(数字),总是返回在进程中当前没有打开的最小描述符。
- flag参数
表示访问方式额外提示
- O_RDONLY:只读。
- O_WRONLY:只写。
- O_RDWR:可读可写。
一位或者多位掩码的或
- O_CREAT,表示如果文件不存在,就创建它的一个截断的文件。
- O_TRUNC:如果文件已经存在,就截断它。
- O_APPEND:在每次写操作前,设置文件位置到文件的结尾处。
mode参数:指定新文件的访问权限位。作为上下文的一部分,每个进程都有一个umask,通过调用umask函数设置。当进程通过带某个带mode参数的open函数用来创建一个新文件的时候,文件的访问权限位被设置为mode & ~umask。
给定mode和umask的默认值:
#define DEF_MODE S_IRUSR|S_IWUSR|S_IRGRP|S_IWGRP|S_IROTH|S_IWOTH
#define DEF_UMASK S_IWGRP|S_IWOTH
出错的时候返回-1。
- 关闭文件:
int close(int fd);
若成功则返回0,不成功则为-1。
关闭一个已经关闭的描述符程序会出错。
3.访问权限位在sys/stat.h中定义
读和写文件
- 读函数
#include<unistd.h>
ssize_t read(int fd,void *buf,size_t n);
- 若成功,返回读字节数,即实际传送的字节数量
- 若EOF,返回0
- 若出错,返回-1
read函数从描述符为fd的当前文件位置拷贝最多n个字节到存储器位置buf。
注:何为EOF
即给定了m字节大小的文件,在从k字节位置开始读或者写的时候,发现k>=m。
2. 写函数
#include<unistd.h>
ssize_t write(int fd,const void *buf,size_t n);
-
若成功,返回写的字节数
-
若出错,返回-1
write函数从存储器位置buf拷贝至多n个字节到描述符fd的当前文件位置。
注:ssziet,sizet的区别 -
ssziet被定义为int,有符号
-
sizet被定义成unsigned int,无符号
通过调用lseek函数,应用程序能够显示地修改当前文件的位置。
3.不足值
在某些情况下,read和write传送的字节比应用程序要求的要少,这些不表示有错误。 -
读时遇到EOF。假设准备读一个文件,该文件从当前文件位置开始只含有20个字节,若以50个字节的片进行读取,下一个read返回的不足值为20,此后的read将通过返回不足值0来发出EOF信号。
-
从终端读文本行。若打开文件与终端相关联(如键盘和显示器),那么每个read函数将以此传送一个文本行,返回的不足值等于文本行大小。
-
读和写网络套接字。若打开的文件对应于网络套接字,内部缓冲约束和较长的网络延迟会引起read和write返回不足值。(进程间的通信机制:对Unix管道调用read和write时,也有可能出现不足值)
实际上除了EOF,在读写磁盘文件时,不会遇到不足值。
如果想创建健壮的诸如web服务器这样的网络应用,就必须通过反复调用read和write处理不足值,直到所有需要的字节都传送完毕。
用RIO包健壮地读写
RIO包会自动处理不足值。RIO提供了两类不同的函数:
- 无缓冲的输入输出函数。这些函数直接在存储器和文件之间传送数据,没有应用级缓冲,对将二进制数据读写到网络和从网络读写二进制数据尤其有用。
- 带缓冲的输入函数。这些函数允许高效地从文件中读取文本行和二进制数据(函数从内部缓冲区中拷贝一个文本行,当缓冲区变空的时候,会自动地调用read重新填满缓冲区),这些文件的内容缓存在应用级缓冲区内,类似于像printf这样的标准I/O函数提供的缓冲区。带缓冲的RIO输入函数是线程安全的,它在同一个描述符上可以被交错地调用。
1.RIO的无缓冲的输入输出函数
通过调用rio_readn和rio_writen函数,应用程序可以在存储器和文件之间直接传送数据。
#include "csapp.h"
//返回值:若成功为传送的字节数,若EOF则为0,出错为-1
ssize_t rio_readn(int fd,void *usrbuf,size_t n);
ssize_t rio_writen(int fd,void *usrbuf,size_t n);
rio_readn函数从描述符fd的当前文件位置最多传送n和字节到存储器位置usrbuf,遇到EOF时只能返回一个不足值。
rio_writen函数从位置usrbuf传送n个字节到描述符fd,绝不会返回不足值。
对于同一个描述符,可以任意交错地调用rio_readn和rio_writen。
- RIO的带缓冲的输入函数
一个文本行就是一个由换行符结尾的ASCII码字符序列。在Unix系统中,换行符(‘\n')与ASCII码换行符(LF)相同,数字值为0x0a。
-
实现计算文本文件中文本行的数量
*方法一:用一个程序来计算文本文件中文本行的数量:用read函数来一次一个字节地从文件传送到用户存储器,检查每个字节来查找换行符。这个方法的缺点是效率低,每读取文件中的一个字节都要求陷入内核。
*方法二:是调用一个包装函数(rio_readlineb),它从一个内部读缓冲区拷贝一个文本行,当缓冲区变空时,会自动地调用read重新填满缓冲区。 -
对于既包含文本行也包含二进制数据的文件,书上提供了一个rio_readn带缓冲区的版本:rio_readnb,它从和rio_readlineb一样的读缓冲区中传送原始字节。
rioreadinitb(riot *rp,int fd);
- 每打开一个描述符都会调用一次该函数,它将描述符fd和地址rp处的类型为rio_t的缓冲区联系起来。
rioreadnb(riot *rp,void *usrbuf,size_t n) ;
- 从文件rp中最多读n个字节到存储器位置usrbuf。对同一描述符,rioreadnb和rioreadlineb的调用可以交叉进行。
ssizet readlineb(riot *rp,void *usrbuf,size_t maxlen);
- 从文件rp中读取一个文本行(包括结尾的换行符),将它拷贝到存储器位置usrbuf,并用空字符来结束这个文本行。
3.RIO读程序的核心——rio_read函数
static ssize_t rio_read(rio_t *rp,char *usrbuf,size_t n)
{
int cnt;
while(rp->rio_cnt<=0)//如果缓冲区为空,先调用函数填满缓冲区再读数据
{
rp->rio_cnt=read(rp->rio_fd,rp->rio_buf,sizeof(rp->rio_buf));//调用read函数填满缓冲区
if(rp->rio_cnt<0)//排除文件读不出数据的情况
{
if(error != EINTR)
{
return -1;
}
}
else if(rp->rio_cnt=0)
return 0;
else
rp->rio_bufptr = rp->rio_buf;//更新现在读到的位置
}
cnt=n;
if(rp->rio_cnt<n)
cnt=rp->rio_cnt;//以上三步,将n与rp->rio_cnt中较小的值赋给cnt
memcpy(usrbuf,rp->rio_bufptr,cnt);把读缓冲区的内容拷贝到用户缓冲区
rp->rio_bufptr+=cnt;
rp->rio_cnt-=cnt;
return cnt;
}
读取文件元数据
- 元数据
应用程序能够通过调用stat和fstat函数,检索到关于文件的信息(元数据)。
#include <unistd.h>
#include <sys/stat.h>
int stat(cost char *filename,struc sta *buf);
int fstat(int fd,struct stat *buf);
- stat函数以文件名作为输入
- fstat函数以文件描述符作为输入
- stat数据结构
- st_size成员包含了文件的字节数大小
- st_mode成员编码了文件访问许可位和文件类型
Unix提供的宏指令根据st_mode成员来确定文件的类型
宏指令:S_ISREG() 普通文件?二进制或文本数据
宏指令:S_ISDIR() 目录文件?包含其他文件的信息
宏指令:S_ISSOCK() 网络套接字?通过网络和其他进程通信的文件
- 内核表示打开文件的三个相关的数据结构
- 描述符表:每个打开的描述符表项指向文件表中的一个表项
- 文件表:所有进程共享这张表,每个表项包括文件位置,引用计数,以及一个指向v-node表对应表项的指针
- v-node表:所有进程共享这张表,包含stat结构中的大多数信息
(1)典型的打开文件的内核数据结构
描述符各自引用不同的文件,没有共享文件。
- 描述符1~4通过不同的打开文件表表项来引用两个不同的文件。
(2)文件共享
多个描述符通过不同的文件表表项引用同一个文件。
- 两个描述符通过打开两个打开文件表表项共享同一个磁盘文件。
- 关键思想:每个描述符都有自己的文件位置,对不同描述符的读操作可以从文件的不同位置获取数据
(3)父子进程共享文件
子进程继承父进程打开文件。
-
调用fork后,子进程有一个父进程描述符表的副本。
-
父子进程共享相同的打开文件表集合,因此共享相同的文件位置。
-
在内核删除相应文件表表项之前,父子进程必须都关闭了他们的描述符
-
I/0重定向
Unix外壳提供了I/O重定向操作符,允许用户将磁盘文件和标准输入输出联系起来
重定向工作方式:使用dup2函数
#include<unistd.h>
int dup2(int oldfd,int newfd);```
dup2函数拷贝描述符表表项oldfd到描述符表表项newfd,覆盖描述表表项newfd以前的内容。
若newfd已经打开,dup2会在拷贝oldfd之前关闭newfd。
### 标准I/O和I/O函数
ANSI C定义了一组高级输入输出函数,称为标准I/O库。提供了打开和关闭文件的函数(fopen和fclose),读和写字节的函数(fread和fwrite),读和写字符串的函数(fgets和fputs),格式化I/O函数(scanf和printf)
- 标准I/O库将一个打开的文件模型化为一个流。一个流就是一个指向FILE类型的结构的指针。每个ANSI C程序开始时都有三个打开的流:
include<stdio.h>
extern FILE *stdin; //标准输入,描述符0
extern FILE *stdout; //标准输出,描述符1
extern FILE *stderr; //标准错误,描述符2```
类型为FILE的流是对文件描述符和流缓存区的抽象。流缓冲区的目的和RIO读缓冲区的一样,就是使开销较高的UnixI/O系统调用的数量尽可能的少。
各类I/O关系
- Unix I/O是在操作系统内核中实现的。
较高级别的RIO和标准I/O函数都是基于Unix函数来实现的。
RIO函数是专为本书开发的read和write的健壮的包装函数。他们自动处理不足值,并且为读文本行提供一种高效的带缓冲的方法
标准I/O函数提供了Unix函数的一个更加完整的带缓冲的替代品,包括格式化的I/O例程。
标准I/O流,从某种意义上是全双工的,但对流的限制和对套接字的限制有时会相互冲突。
限制一:跟在输出函数之后的输入函数
限制二:分在输入函数的输出函数
由此,建议在网络套接字上不要使用标准 I/O函数来进行输入和输出,而要使用健壮的RIO函数。
问题解决
1.flags参数:
O_TRUNC:如果文件已经存在,就截断它。
如何理解截断?
- 在c++中ios::trunc与ios::out的效果应该是一样的,也就是打开文件的时候先将文件的内容清空,再进行写入。并不是删除文件。
截断后文件就是空文件了,所有文件指针可以说在最前面也是最后面。截断后文件还是那个文件(如果文件存在的话),但是内容没有了。 - 类比可知,O_TRUNC : 如果文件已存在,就截断它(长度被截为0,属性不变)
2.练习题10.1 代码输入后编译显示找不到csapp.h

解决:通过搜索得知csapp.h是一堆头文件的打包,在http://csapp.cs.cmu.edu/public/code.html 这里可以下载,linux应该没有自带csapp.h。于是更改了头文件,编译成功。

心得体会
-
秋色渐衰,雁声远去。长天无日,霾雾幽重。求学在外,心有丘壑。如浪翻滚,难以将息。
忽忆江人,且烦他去。当游即走,何得烦愁。乘兴而行,兴尽而返。魑魅魍魉,莫能逢之。
本周代码托管
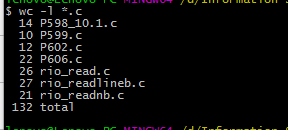
- 托管截图及代码行数统计

学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 120/200 | 1/2 | 16/16 | 学习Linux核心命令 |
| 第二周 | 100/200 | 1/3 | 30/46 | 学习vim,gcc以及gdb的基本操作 |
| 第三周 | 30/230 | 1/4 | 15/61 | 对信息的表示和处理有更深入的理解 |
| 第四周 | 30/260 | 1/5 | 22/83 | 双系统的探索 |
| 第五周 | 130/390 | 1/6 | 25/108 | 汇编的深入学习 |
| 第六周 | 60/450 | 1/7 | 25/133 | 熟悉了Y86模拟器 |
| 第七周 | 60/510 | 2/9 | 20/153 | 掌握局部性原理 |
| 第八周 | 0/510 | 2/11 | 16/169 | 期中总结 |
| 第八周 | 132/642 | 1/12 | 21/190 | 深入理解系统级I/O |

