Python 基础(一)
本章内容
1.编译和解释型语言的区别
2.Python的解释器
3.pyc文件
4.运行环境
5.变量
6.数据类型
7.字符编码
8.三元运算
编译和解释型语言的区别
编译器是把源程序的每一条语句都编译成机器语言,并保存成二进制文件,这样运行时计算机可以直接以机器语言来运行此程序,速度很快; 而解释器则是只在执行程序时,才一条一条的解释成机器语言给计算机来执行,所以运行速度是不如编译后的程序运行的快的. 这是因为计算机不能直接认识并执行我们写的语句,它只能认识机器语言(是二进制的形式)
编译型vs解释型
编译型
优点:编译器一般会有预编译的过程对代码进行优化。因为编译只做一次,运行时不需要编译,所以编译型语言的程序执行效率高。可以脱离语言环境独立运行。
缺点:编译之后如果需要修改就需要整个模块重新编译。编译的时候根据对应的运行环境生成机器码,不同的操作系统之间移植就会有问题,需要根据运行的操作系统环境编译不同的可执行文件。
解释型
优点:有良好的平台兼容性,在任何环境中都可以运行,前提是安装了解释器(虚拟机)。灵活,修改代码的时候直接修改就可以,可以快速部署,不用停机维护。
缺点:每次运行的时候都要解释一遍,性能上不如编译型语言。
python的优缺点
1、Python的定位是“优雅”、“明确”、“简单”,write less do more
2、开发的效率很高,有很多强大的第三方库
3、高级语言,不必考虑底层的实现
4、可扩展性,内部可以嵌入其他程序的代码
5、可嵌入性,你可以把python嵌入到C/C++程序中
python的缺点
1、速度慢
2、代码不能加密
3、线程不能利用多cpu问题
Python的解释器
CPython
CPython。这个解释器是用C语言开发的,所以叫CPython。在命令行下运行python就是启动CPython解释器。
CPython是使用最广的Python解释器。教程的所有代码也都在CPython下执行。
IPython
IPython是基于CPython之上的一个交互式解释器,也就是说,IPython只是在交互方式上有所增强,但是执行Python代码的功能和CPython是完全一样的。好比很多国产浏览器虽然外观不同,但内核其实都是调用了IE。
PyPy
PyPy是另一个Python解释器,它的目标是执行速度。PyPy采用JIT技术,对Python代码进行动态编译(注意不是解释),所以可以显著提高Python代码的执行速度。
绝大部分Python代码都可以在PyPy下运行,但是PyPy和CPython有一些是不同的,这就导致相同的Python代码在两种解释器下执行可能会有不同的结果。如果你的代码要放到PyPy下执行,就需要了解PyPy和CPython的不同点。
Jython
Jython是运行在Java平台上的Python解释器,可以直接把Python代码编译成Java字节码执行。
IronPython
IronPython和Jython类似,只不过IronPython是运行在微软.Net平台上的Python解释器,可以直接把Python代码编译成.Net的字节码。
小结:
Python的解释器很多,但使用最广泛的还是CPython。如果要和Java或.Net平台交互,最好的办法不是用Jython或IronPython,而是通过网络调用来交互,确保各程序之间的独立性。
.pyc文件
__cache 在python3.*中会有这个目录,然后这个目录下有.pyc文件,python2.*中没有这个目录,直接.pyc
pyc文件是py文件编译后生成的字节码文件(byte code)。pyc文件经过python解释器最终会生成机器码运行。所以pyc文件是可以跨平台部署的,类似Java的.class文件。一般py文件改变后,都会重新生成pyc文件。
这么做的目的就是为了加快下次执行文件的速度,其实并不是所有的.py文件在与运行的时候都会差生.pyc文件,只有在import相应的.py文件的时候,才会生成相应的.pyc文件
为什么要手动提前生成pyc文件呢,主要是不想把源代码暴露出来。
手动命令:
python -m foo.py
运行环境
#!/usr/bin/env python
#!/usr/bin/python
两者的区别,第一种是通过env 去找python的环境变量,应用比较灵活,第二种是把路径写死了,如果安装的路径不是这个,那就找不到了。
变量
变量存储在内存中的值。这就意味着在创建变量时会在内存中开辟一个空间。基于变量的数据类型,解释器会分配指定内存,并决定什么数据可以被存储在内存中。因此,变量可以指定不同的数据类型,这些变量可以存储整数,小数或字符。
每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建。
变量定义的规则:
- 变量名只能是 字母、数字或下划线的任意组合
- 变量名的第一个字符不能是数字
- 以下关键字不能声明为变量名
['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']
数据类型
1、数字
(int)整形
(long)长整型
在python3*中已经没有长整形了,都是整形。
2、浮点数
浮点数不是小数,小数只是浮点数的一种表现形式
3、布尔值
4、bytes
二进制文件
这是python3中新添加的类型,在python2中,str 与 bytes 是一样的。在python3中 str 与 bytes是可以互相转换的。
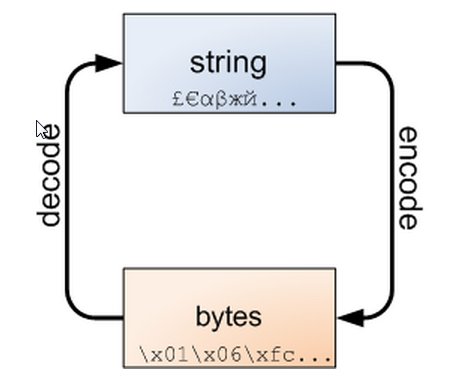
message = ' hello world' message1 = '北京' print(message.encode('utf-8')) print(message1.encode(encoding='utf-8')) print(message1.encode(encoding='utf-8').decode(encoding='utf-8')) 结果: b' hello world' b'\xe5\x8c\x97\xe4\xba\xac' 北京
字符编码
ASCII
Unicode
utf-8
三元运算
result = 值1 if 条件 else 值2
如果条件为真: result = 值1
如果条件为假: result = 值2
示例:
a,b,c = 1, 3, 5
d = a if a > b else c
猜猜结果如何。
