Python 基础二
本章内容
1.小知识点
2.字符串string
3.字符串的深浅copy
4.列表list
5.元组tuple
6.列表生成式
7.字典dict
8.集合set
9.文件操作
10.字符编码与转码
小知识点
1、raw_input() python2中可用
input() python2/3可用
首先说下,python2中的raw_input(), 用来获取用户的输入,并把所有的输入转换成字符串的形式
python2中的input(),不好用,也建议不要用它, 因为 它这里必须跟可识别的表达式,如果是string,需要加引号,
float、int可用直接输入,如果输入的字符串恰好是个变量,则会输出这个变量。


python 3 中input 取代了raw_input
2. 小练习题, 10000存入银行,利润是0.35%,多少年才可以翻倍?
money = 10000
year = 1
while money <= 20000:
money *=1.035
year +=1
print year
3.如何让多个字符串在同一个同一行中输出?
方法一:
string = ""
string += 'test'
for i in [1,2,3]:
string += str(i)
print (string)
方法二:
import sys
sys.stdout.softspace=0 #这行需要在每个print下面添加。 貌似python3中不能用
4、type(......) #查看 ........变量的数据类型。
5、string是可以遍历的
a = 'hello world'
for i in a:
print i
6、判断变量名字的有效性:

import string
string.ascii_letters #大小写字母
string.digits #0-9
条件:
1、不能以数字开头
2、必须所有的字符都在 a-z,0-9
if I not in string.digits + string.ascii_letters + '_'
8、 len() #查看字符串的长度
max()/min() #查找最大、最小值
max(string.ascii_letters) #比较字母
max(string.digits) #比较数字
max([1,3,6,2,3,66]) #比较列表元素
range(开始:结束:分段)
sum() #计算总和
reversed() -> string[0:0:-1] #区别是前者没有返回值,直接对数据做了修改,后者有返回值,数据没动
sorted() #对列表进行排序,排序后变量并不会改变 如果是 变量.sort() 原数据则会被排序
enumerate #序列化操作

运行结果:

zip:

运行结果:


11. sys 模块是python解释器自带的。使用c语言写的,在环境路径下是找不到这个.py文件的,
字符串string
序列的公共特性:
- 可遍历
- 可切片
- 有索引
- 可连接 + 相加
- 重复
- 成员 in/not in
- 不可修改
string += '1' ,这其实是给string另外开辟了一个新的内存,id(string)可以看到其实变化的。
string的内建函数
a = 'hello world!!'
a.capitalize() #首字母大写
a.title() #每个单词的首字母大写
a.upper() #所有字母都大写
a.lower() #所有字母都小写
a.swapcase() #大小写互换
a.count('c') #统计字母c 出现的次数
a.startwith('h') #判断字母是否已 h 开头 返回True 或者Flase
a.endswith('c') #判断是否以 c 结尾 ,返回同上
a.isalnum() #判断字符串是否全为字母或者数字,返回同上
a.isalpha() #判断是否全为字母
a.isdigit() #判断是否全为数字
a.islower() #判断是否全为小写
a.isupper() #判断是否全为大写
a.replace('a','A') #将 a 替换为 A , 返回替换后的数据,元数据不受影响
a.replace('a'.'A',3) #指定只替换前多少个
a.split(':',max) #已什么为分割位,可以最大输出多少个,返回数组

a.index('f') #查找f的下标是多少,如果没有则返回 substring not found
a.find('f') #查找f并返回下标,如果没有返回 -1
index 和find,查找的时候从左到右去匹配,如果有一个匹配,后面的则不再查找。
a.rfind('f') #从右开始朝赵
a.format() #格式化输出



a.join('') #

a.strip() #去除两边的空格
a.rstrip() #去除右面的空格
a.lstrip() #去掉左面的空格
a.strip('he') #去掉左面的he

a.ljust(width,'xx') #占位width,左对齐,不够xxx来填丛

a.rjust()
a.center(width) #中间对齐,两边不够空格对齐
a.zfill(20) #右面对齐,左面不够 0 补齐。
字符串的深浅copy
a = ['hello','nihao','xiaoming']
b = a
a.append('datou')
print(id(a))
print(id(b))
print(a)
print(b)
4302256648
4302256648
['hello', 'nihao', 'xiaoming', 'datou']
['hello', 'nihao', 'xiaoming', 'datou']
a的值付给b,相当于b的内存地址指向了列表的内存地址,a如果修改数据的话相当于修改了内存地址中的数据,a,b指向相同的内存地址,所以b也是会随之变化的。
浅copy
a = ['hello','nihao','xiaoming',['a','b']]
b = a.copy()
a[2] = 'datou'
a[3][0] = 'c'
print(id(a))
print(id(b))
print(a)
print([id(ele) for ele in a])
print(b)
print([id(ele) for ele in b])
结果:
4301252680
4301253192
['hello', 'nihao', 'datou', ['c', 'b']]
[4300593392, 4300593560, 4301184056, 4301208072]
['hello', 'nihao', 'xiaoming', ['c', 'b']]
[4300593392, 4300593560, 4300640432, 4301208072]

浅copy就是之copy内存的第一层指针,然后让在新的内存地址中,如果a修改第一层的东西,当然影响不到b了,但是a修改第二层的东西时,b就会随之变化,因为b把第二层的指针copy过来的,指针是没有变化的。
实现浅copy的三种方式:
person = [........]
p1 = copy.copy(person)
p2 = person[:]
p3 = list(person)
深copy
import copy
a = ['hello','nihao','xiaoming',['a','b']]
b = copy.deepcopy(a)
a[2] = 'datou'
a[3][0] = 'c'
print(id(a))
print(id(b))
print(a)
print([id(ele) for ele in a])
print(b)
print([id(ele) for ele in b])
print('----------')
结果:
4330176648
4330177096
['hello', 'nihao', 'datou', ['c', 'b']]
[4301641968, 4301642136, 4302231680, 4329896392]
['hello', 'nihao', 'xiaoming', ['a', 'b']]
[4301641968, 4301642136, 4301689008, 4330130696]
相当于如论内存中多少层,都copy一份,你改你的,我不受你的影响。
如同linux中的硬链接和软连接:
Linux 系统中有软链接和硬链接两种特殊的“文件”。
软链接可以看作是Windows中的快捷方式,可以让你快速链接到目标档案或目录。
硬链接则透过文件系统的inode来产生新档名,而不是产生新档案。
小知识点
input 输入一个数字, 可以用isdigit() 来判断是不是数字,这个数字可能是str 型的哦,需要int下
另外在while死循环中,如果想要退出程序,可以用exit()
购物车小练习


1 product_list = [ 2 ('Iphone',5800), 3 ('Mac Pro',9800), 4 ('Bike',800), 5 ('Watch',10600), 6 ('Coffee',31), 7 ('Alex Python',120), 8 ] 9 shopping_list = [] 10 salary = input("Input your salary:") 11 if salary.isdigit(): 12 salary = int(salary) 13 while True: 14 for index,item in enumerate(product_list): 15 #print(product_list.index(item),item) 16 print(index,item) 17 user_choice = input("选择要买嘛?>>>:") 18 if user_choice.isdigit(): 19 user_choice = int(user_choice) 20 if user_choice < len(product_list) and user_choice >=0: 21 p_item = product_list[user_choice] 22 if p_item[1] <= salary: #买的起 23 shopping_list.append(p_item) 24 salary -= p_item[1] 25 print("Added %s into shopping cart,your current balance is \033[31;1m%s\033[0m" %(p_item,salary) ) 26 else: 27 print("\033[41;1m你的余额只剩[%s]啦,还买个毛线\033[0m" % salary) 28 else: 29 print("product code [%s] is not exist!"% user_choice) 30 elif user_choice == 'q': 31 print("--------shopping list------") 32 for p in shopping_list: 33 print(p) 34 print("Your current balance:",salary) 35 exit() 36 else: 37 print("invalid option")
列表list
列表使用 []
l = list(string) #字符串转换为list
"".join(l) #list转换为字符串
list支持序列共有属性和操作!!! 如 * +
list里面的值可以被修改,修改后 id()是不会改变的。
list的基本函数:
- 元素的赋值
list[0] = 'hello' 原来位置上的值则会被覆盖掉
- list[begin:end] 将会显示 list[begin] 到 list[end-1]的值,list[end]不会显示,list[:]显示整个列表
- 修改列表

list[2:2] = [123] #插入
也可以用insert
list.insert(1,[1,2,3,4])
list[2:len(list)] = [] #相当于删除其中的某些项
- count 函数

- len就不多少了
- append 函数 #列表的后面插入东东

也可以用+好来实现列表的详见, 【】+【】 +【】
- extend 函数, 修改原来的数列, 链接两个数列,产生新的序列

- pop 函数, 删除指定位置的元素,可以指定列表中的位置,如果没加位置,则弹出的是最后一个元素

- remove 函数, 删除指定的元素,和pop不同的是,这里直接删值

- index 函数,从列表中找出与某个元素匹配的第一个匹配的位置
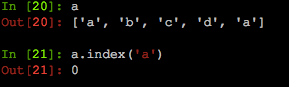
- reverse 函数, 翻转列表

- sort 函数 , 队员列表进行排序

这里需要注意:
a = b ,b 和 a 指向的同一个列表,
b = a[:] ,给bcopy了一份
按照关键字排序:

关键字排序:reverse()

字典元素遍历的效率比较
for index in dict:
print index,dict[index]
for key,val in dict.items():
print key,val
第一中直接通过key来查找,第二种需要把字典转换为列表,然然后在输出,在数据量大的情况下,第二种的方式会慢。
元组tuple
元组用() 来表示,如
tuple1 = ('a','b','c')
元组中如果只有一个元素时,需要在元素后面添加逗号来消除歧义。
tuple2 = (’a‘ ,)
元组访问
tuple3 = (1,2,3,4,5,6)
tuple3[0]
修改元组
tuple3[0] = 100 #因为元组中的元素是不可修改的,所以这种修改的方法是不可行的。
但可以对元组进行相加的操作
tup1 = ('a','b','c')
tup2 = ('e','f','g')
tup3 = tup1 + tup2
删除元组
元组中的元素值是不允许删除的,但我们可以使用del语句来删除整个元素组。
元组运算符
与字符串一样,元组之间可以使用 + 号 和* 号, 这就意味着他们可以组合和复制, 运算后会产生一个新的元组。
元组内置函数
Python 元组包含了一下内置函数:
- cmp(tup1,tup2) #比较两个元组元素
- len(tuple) #计算元组元素的个数
- max(tuple) #返回元组中最大的值
- min(tuple) #返回元组中元素的最小值
- tuple(seq) #将列表转换为元组
另一种解读
tuple 和list 非常的类似, 但是tuple一旦初始化就不能修改了,如:
classmates = ('xiaoming','bob','michael')
现在, classmates 这特tuple不能改变了,它也没有append(),insert()这样的操作,其他获取元素的方法和list一样,
可以正常的使用classmates[0],classmates[-1],但不能复制成另外的元素。
不可变的tuple有什么意义?因为tuple不可变,所以代码更安全, 如果可能, 能用tuple代替的list尽量用tuple。
tuple的陷阱,当你定义一个tuple时,在定义的时候,tuple的元素就必须被确定下来。
列表生成式
1、 [ i**2 for i in range(10)]
2、 b = [ 23,3,5,2,1]
c = [6,3,1,3,4,6]
[i for i in b if i in c] #取两个数的交际
3、['asdf' + x for x in range(10)]
4、a = ['c++','php','c','python','java']
b = [a[random.randint(0,4)] for i in range(10)] #循环一次,在a中取一个元素。
判断数据类型
type('asdf') == type(a) #a是一个字符串,判断asdf是不是字符串
type('param') == int #判断param是不是init类型
type('True') == bool #判断是不是布尔值
字典dict
字典是另一种可变容器的模型,且可村春任意的类型对象。
样子:exa = {key1:'hello',key2:'world'}
键必须是唯一的,但值则不必。
value 可以取任何的数据类型,但是键必须是不可变的,如字符串、数字、元组
取值:
a = exa['key']
修改字典:
exa['key'] = 'anything'
删除字典元素
del exa['key'] #删除键是'key'的条目
exa.clear() #清空字典的所有条目
del exa #删除整个字典。
字典内置函数
- cmp(dict1,dict2) #比较字典元素
- len(dict) #查看长度
- dict.fromkeys(sql[val])

- dict.get(key,default = None) #看key是否存在,如果不存在则给个返回值,这个主要用于统计
如用字典来统计 某个字母出现的次数。
dict['a'] = dict.get('a', 0) +=1 #如果字典中没有a,则返回0,并加1,通过来累加统计
- dict.has_key() #在python2中有,3中没有了,有这个key则返回True,没有则返回Flase
- dict.items() #返回可遍历的(键、值)元素数组
- dict.keys #返回所有的键
- dict.setdefault() #与get一样。
- dict.update(dict2) #把字典dict2的键/值更新到dict里面
- dict.values() #已列表的形式返回字典中所有的值
- dict.pop() #随机删key
做个统计的小例子


方框中的删除方法有问题,会报错,应该潜copy一个,然后去循环,再做删除
集合 set
集合是一个无序的、不重复的组合,它的主要作用如下:
1、去重,把一个列表变成集合,就自动去重了
2、关系测试,测试两组数据之前的交际、差集、并集等关系
常用操作:
s = set([4,5,3,6,4]) #创建一个数值集合
t = set("hello) #创建一个唯一的字符集合
a = t | s # t 和 s的并集
b = t & s # t 和 s的交集
c = t – s # 求差集(项在t中,但不在s中)
d = t ^ s # 对称差集(项在t或s中,但不会同时出现在二者中)
基本操作:
t.add('x') # 添加一项
s.update([10,37,42]) # 在s中添加多项
使用remove()可以删除一项: t.remove('H')
len(s) set 的长度
x in s 测试 x 是否是 s 的成员
x not in s 测试 x 是否不是 s 的成员
s.issubset(t) ,s <= t 测试是否 s 中的每一个元素都在 t 中
s.issuperset(t) ,s >= t 测试是否 t 中的每一个元素都在 s 中
s.union(t) ,s | t 返回一个新的 set 包含 s 和 t 中的每一个元素
s.intersection(t) ,s & t 返回一个新的 set 包含 s 和 t 中的公共元素
s.difference(t), s - t 返回一个新的 set 包含 s 中有但是 t 中没有的元素
s.symmetric_difference(t) ,s ^ t 返回一个新的 set 包含 s 和 t 中不重复的元素
s.copy() 返回 set “s”的一个浅复制
文件操作
字符编码与转码
Python2中的编码是ASCII,python3中的编码是unicode,默认支持中文
ASCII 只能存英文和特殊字符,每个字符占8bits,一个byte
unicode 无论中文还是应为每个占2个bytes,占16bits
utf-8 所有的英文字符按照ASCII去存储,所有的中文占3bytes
中文字符在元组中显示为unicode格式

查看字符编码的方法:
import sys
print sys.getdefaultencoding()
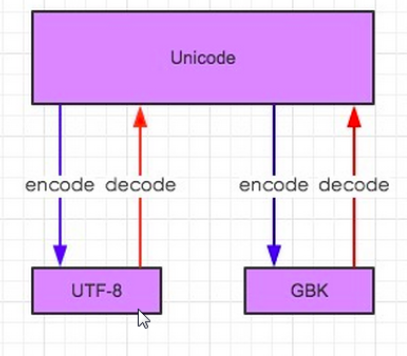
现在需要把中文GBK转换成utf-8格式的
s = '你好'
s.decode('GBK').encode('utf-8')
首先要告知我这是GBK编码的文件,需要用GBK来解码为unicode,然后再从unicode编码为UTF-8
s = u'你好' #这么写的话就表示,s是unicode编码的。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构