Python文件处理
文件和流
python3中使用 open 打开文件,python2.x是file
open(name[,mode[,buffering]])
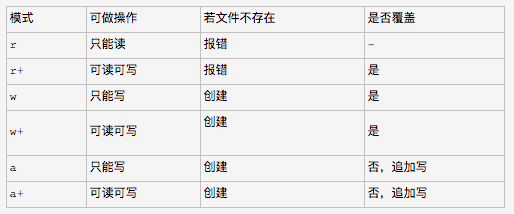
mode: 'r' 读模式
'w' 写模式
'a' 追加模式
'b' 二进制模式
'r+' 等同于 'r+a' #可读可写,不会创建不存在的文件。如果直接写文件,则从顶部开始写,覆盖之前此位置的内容,
如果先读后写,则会在文件最后追加内容
'w+' 等同于 'w+r' #可读可写,若文件不存在,则创建新的文件,如果文件存在,则覆盖,
'a+' 等同于 'a+r' #可读可写,若文件不存在,则会创建新的文件,若文件存在,不会覆盖,追加文件到最后面
"U"表示在读取时,可以将 \r \n \r\n自动转换成 \n (与 r 或 r+ 模式同使用)
1、rU
2、r+U
"b"表示处理二进制文件
1、rb
2、wb
3、ab
buffering 参数是0或者false, 表示无缓冲区,直接对硬盘进行操作
参数是1或者True , 表示使用内存,程序更快
参数大于1,表示缓冲区的大小,(单位是字节)
-1或者负数,表示使用默认缓存区的大小
小例带大家进一步演练
小丽:
f = open('somefile.txt' , 'w')
f.write('hello , ') #会提示写入字符的个数
f.write('world')
f.close() #如果文件存在,直接覆盖起先的内容,然后写入,如果是写的,则新建
小丽:
f = open('somefiles.txt' , 'r') #'r'模式是默认的模式,可以不用添加
f.read(4) # 告诉流读取4个字符(字节),会输出前四个字符
f.read() #读取剩余的部分,输出剩余的字符,为什么在读的话就是剩余的全部,
这里面有个指针的概念,后面会说到
f.close()
管式输出: $cat somefile.txt | python somescript.py | sort #可以结合管道式输出
#somescript.py 脚本内容:
#somescript.py
import sys
text = sys.stdin.read()
words = text.split()
wordcount = len(words)
print 'Wordcount:' , wordcount
seek & tell
前面的小例都是按照流从头往后来处理的。可以用seek 和 tell 来对兴趣的部分进行处理
seek(offset[,whence]):
whence = 0 #表示偏移量是在文件的开始进行
whence = 1 #想当与当前位置,offset可以是负值
whence = 2 #相对于文件结尾的移动
小丽:
f = open(r'a.txt' , 'w')
f.write('0123456789')
f.seek(5)
f.write('hello world')
f = open(r'a.txt')
r.read()
'01234hello world...' #会在第五的位置开始写。
小丽:
f = open('a.txt')
f.read(3)
'012'
f.read(2)
'34'
f.tell()
5l #告诉你在当前第五的位置
f.readline #读取一行
f=open('a.txt')
for i in range(3):
print str(i) + ':' + f.readline()
0:......
1:......
2:.....
3:.....
f.readlines #全部读取
f.writeline()
f.writelines()
关闭文件
文件的关闭:
关闭文件,可以避免用完系统中所打开文件的配额
如果想确保文件被关闭了,可以使用try/finally 语句,并在finally中调用close()
方法:
open your file here
try:
write data to your file
finally:
file.close()
实际上有专门对这种情况设计的语句 ,既with语句
with open('someone.txt') as somefile:
do something(someone.txt)
#把文件负值到 somefile变量上,好处是不用再使用f.close()了。
如果文件正在内存中,还没有写入文件中,想要在文件中看到内容,需要用 flush 方法
f.flush() #频繁的写入到硬盘会影响到性能,一般的应用场景是时时的读取日志。
flush 功能可以在ipython解释器中来查看这个方法,首先f.write('wwww'),打开文件内容没有被写入,然后f.flush后文件就会被写入到文件中了。
下面利用个显示进度条的小例子来解释flush
1 import sys,time 2 3 4 for i in range(10): 5 sys.stdout.write('#') 6 sys.stdout.flush() #如果没有这一行,则会一口气全部输出 7 time.sleep(0.2)
文件读取的高效方法
f = open('a')
f.read() #读取所有的文件然后输出,不能对其操作,内容以‘’ 引起,字符串的形式
f.readline() #一行一行的读取
f.readlines() #读取所有的行,一list的方式输出,可对对去的所有行操作。
如果是大文件,4G - 10 G ,readlines 的方法会把所有的文件都读取到内存中,这种方法不可取,
可靠的方法:
for line in f:
print (line) #再对每行做处理
这种方法是逐行的读取,然后处理完毕后释放内存,再处理下一个,这里为什么会这样呢?因为 f 的保存是迭代器的方式,
迭代器:迭代器是访问集合元素的一种方式。迭代器对象从集合的第一个元素开始访问,知道所有的元素被访问完结束。迭代器只能往前不会后退,不过这也没什么,因为人们很少在迭代途中往后退
迭代器的一大优点是不要求事先准备好整个迭代过程中所有的元素。迭代器仅仅在迭代到某个元素时才计算该元素,而在这之前或之后,元素可以不存在或者被销毁。这个特点使得它特别适合用于遍历一些巨大的或是无限的集合,比如几个G的文件,或是斐波那契数列等等。
日志处理小练习


1 题目: 2 处理日志,按照访问者的IP和url和状态码三个维度统计数据,打印出现次数最多的10个 3 1.三个维度 4 2.并列的 需要都打出来(比如8到12名并列,都要打印出来) 5 s = '61.159.140.123 - - [23/Aug/2014:00:01:42 +0800] "GET /favicon.ico HTTP/1.1" 404 \ "-" "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.66 Safari/537.36 LBBROWSER" "-"' 6 # print s.split() 7 8 9 10 11 python 代码: 12 #!/usr/bin/python 13 #coding:utf8 14 15 16 with open('access.mad') as f: 17 content = f.readlines() 18 f.close() #with方法打开的文件跳出with后就直接close了,不再需要close 19 20 count_dict = {} 21 22 for line in content: #if line == '\n':contine 判断下是不是空格 23 line = line.split(' ') #string 通过split 转换为list 24 local_ip,uri,code = line[0],line[6],line[8] 25 26 count_dict[(local_ip,uri,code)] = count_dict.get((local_ip,uri,code),0) + 1 #利用元组来作为key,然后统计数量 27 28 count_dict = sorted(count_dict.items() ,key=lambda item:item[1],reverse=True) #这个排序的功能网上copy的,不了解原理 29 30 #下面进行重复行计数为一行。 31 n = 1 #取行计数 32 num = 0 #用于判断'统计数量'是否出现一样的 33 print ('---IP--------------URI----------CODE------count---') 34 for i in count_dict: 35 if n <= 10: #取前十 36 if i[1] != num: 37 print ('%-10s%20s%5s%10s ---->no%s' %(i[0][0],i[0][1],i[0][2],i[1],n)) 38 num = i[1] 39 n +=1 40 elif i[1] == num: 41 print ('%-10s%20s%5s%10s' %(i[0][0],i[0][1],i[0][2],i[1])) 42 课堂中学习到的。 43 字典的排序可以转换为list再排序。 44 代码如下: 45 res_list = res.items() #利用items把字典转换成list 46 #字典是无序的,所以需要转换成list 47 for i in range(len(res_list) - 1): #利用冒泡的方法来排序 48 for j in range(len(res_list) - 1 - i): 49 if res_list[i][1] > res_list[i + 1][1]: 50 res_list[i],res_list[i+1] = res_list[i+1],res_list[i] 51 52 print res_list 53 54 55 56 57 58 59 运行result: 60 ---IP--------------URI----------CODE------count--- 61 10.1.1.10 /ajax/MbpRequest.do 200 115 ---->no1 62 10.1.1.9 /ajax/MbpRequest.do 200 49 ---->no2 63 10.1.1.7 /ajax/MbpRequest.do 200 49 64 10.1.1.8 /ajax/MbpRequest.do 200 46 ---->no3 65 10.1.1.3 /ajax/MbpRequest.do 200 28 ---->no4 66 10.1.1.11 /ajax/MbpRequest.do 200 21 ---->no5 67 10.1.1.4 /ajax/MbpRequest.do 200 20 ---->no6 68 10.1.1.5 /ajax/MbpRequest.do 200 20 69 10.1.1.6 /ajax/MbpRequest.do 200 20 70 10.1.1.12 /ajax/MbpRequest.do 200 16 ---->no7 71 10.1.1.13 /ajax/MbpRequest.do 200 15 ---->no8 72 10.1.1.2 /ajax/MbpRequest.do 200 14 ---->no9 73 10.1.1.15 /ajax/MbpRequest.do 200 11 ---->no10 74 75 76 总结的小知识点: 77 78 for (ip,url,code),count in res_list: 79 print ip,url,code,count 80 81 82 10.1.1.2 /ajax/MbpRequest.do 200 9 83 10.1.1.1 /ajax/MbpRequest.do 200 10 84 10.1.1.3 /ajax/MbpRequest.do 200 15 #无边界输出,无[],()什么的,整洁的输出,
文件的修改
如果经过内存修改,python中的模式,只能把全部的文件加载到内存当中,类似vim一样
python的硬盘读写模式,只能打开一个文件,然后写入另外的一个新文件中
import sys f = open("yesterday2","r",encoding="utf-8") f_new = open("yesterday2.bak","w",encoding="utf-8") find_str = sys.argv[1] replace_str = sys.argv[2] for line in f: if find_str in line: line = line.replace(find_str,replace_str) f_new.write(line) f.close() f_new.close()
代码规范中一行代码最多不要超过80个字符,
with open("yesterday2" , "r",encoding="utf-8") as f,\ open("yesterday" , "r",encoding="utf-8") as f2: for line in f: print(line)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号